-
메모리 장벽의 확장: HBM의 부상과 로드맵 (25.8.14)TechStock&Review/SemiConduct 2025. 8. 14. 08:49
Scaling the Memory Wall: The Rise and Roadmap of HBM

출처: Semianalysis HBM에 대한 간략한 개요
AI 모델의 복잡성이 증가함에 따라 AI 시스템은 더 높은 용량, 더 낮은 지연 시간, 더 높은 대역폭, 그리고 향상된 에너지 효율을 갖춘 메모리를 필요로 합니다. 메모리 종류에 따라 장단점이 있습니다. SRAM은 매우 빠르지만 밀도가 낮습니다. DDR DRAM은 밀도가 높고 저렴하지만 대역폭이 부족합니다. 현재 가장 널리 사용되는 메모리는 용량과 대역폭의 균형을 맞춘 온칩 HBM입니다.

출처: Rambus
HBM은 수직 적층 DRAM 칩과 초광대역 데이터 경로를 결합하여 AI 워크로드에 최적화된 대역폭, 밀도, 에너지 소비의 균형을 제공합니다. HBM은 생산 비용이 훨씬 높고 DDR5보다 가격 프리미엄이 높지만, HBM에 대한 수요는 여전히 높습니다.
생성형 AI 학습 및 추론에 사용되는 모든 주요 AI 가속기는 HBM을 사용합니다. 가속기 로드맵의 공통적인 추세는 더 많은 스택, 더 높은 계층 수, 그리고 더 빠른 세대의 HBM을 추가하여 칩당 메모리 용량과 대역폭을 확장하는 것입니다. 다른 형태의 메모리를 사용하는 아키텍처는 앞서 설명한 바와 같이 최적이 아닌 성능을 제공 합니다.
이 보고서에서는 HBM의 현재 상황, 공급망 현황, 그리고 미래에 일어날 획기적인 변화를 살펴봅니다. AI 가속기 아키텍처에서 HBM이 차지하는 중요한 역할, HBM이 DRAM 시장에 미치는 영향, 그리고 HBM이 메모리 시장 분석 방식을 뒤흔드는 이유를 살펴봅니다.HBM 프라이머
먼저, HBM에 대한 간략한 소개를 드리겠습니다. HBM의 특별함과 제조 과정의 어려움에 대해 알아보겠습니다. HBM은 일반적으로 3DIC 어셈블리에 여러 개의 DRAM 다이를 적층한 것과 관련이 있지만, HBM의 또 다른 핵심 특징은 훨씬 더 넓은 데이터 버스입니다.
이 버스는 낮은 신호 전달 속도에서도 대역폭을 향상시킵니다. 이처럼 훨씬 넓은 버스 덕분에 HBM은 패키지당 대역폭 측면에서 다른 어떤 메모리 형태보다 훨씬 뛰어납니다.

출처: SemiAnalysis
I/O가 훨씬 많아지면 라우팅 밀도와 복잡성이 증가합니다. 각 I/O에는 개별 와이어/트레이스가 필요하며, 전원 및 제어를 위한 추가 배선이 필요합니다. HBM3E 스택의 경우, 인접한 XPU와 HBM 사이에 1,000개가 넘는 와이어가 있습니다. 이러한 수준의 라우팅 밀도는 PCB나 패키지 기판에서는 달성할 수 없으므로, CoWoS와 같은 2.5D 패키지 어셈블리에 인터포저(실리콘 또는 유기)가 필요합니다.
데이터 전송 지연 시간과 에너지 소비를 줄이려면 HBM을 컴퓨팅 엔진의 shoreline 바로 옆에 배치해야 합니다. HBM은 SOC의 두 모서리에만 배치할 수 있고 나머지 두 모서리는 패키지 외부의 I/O용으로 예약되어 있기 때문에 shoreline(SOC의 모서리)의 가치가 더욱 높아집니다. 이로 인해 HBM을 배치할 수 있는 공간이 제한되고, 충분한 용량을 확보하려면 메모리 다이를 수직으로 쌓아야 합니다.
3DIC 폼 팩터를 구현하려면 스택의 각 층에 전력과 신호를 위층으로 전달할 수 있는 TSV(Through-Silicon Via) (스택 상단 제외)가 필요합니다. 이러한 TSV를 장착하는 데 필요한 추가 공간 때문에 HBM 다이 크기가 DDR 대비 커집니다. SK Hynix D1z DDR4의 비트 밀도는 0.296Gb/mm2로 , HBM3의 0.16Gb/ mm2 보다 85% 더 높습니다 . 이 TSV 공정은 표준 DRAM과 DRAM의 주요 차이점 중 하나이며, 이를 위한 툴링은 일반 DDR DRAM 웨이퍼 용량을 HBM 용량으로 변환하는 데 있어 주요 병목 현상입니다.
또 다른 차이점은 백엔드(후공정)에 있습니다. HBM은 총 9개 또는 13개 층으로 적층해야 합니다(하단 로직 베이스 다이 위에 8개 또는 12개의 DRAM 층이 적층됨). CoWoS와 함께 HBM은 패키징 기술을 주류로 끌어올렸습니다. MR-MUF와 같은 틈새 패키징 기술은 이제 업계 관계자들 사이에서 널리 알려진 기술이 되었습니다.폭발적인 비트 수요
AI 가속기 수요와 함께 HBM 비트 수요의 엄청난 성장을 볼 수 있습니다. 맞춤형 ASIC의 급속한 증가에도 불구하고 Nvidia는 Rubin Ultra만으로 GPU 용량을 1TB로 끌어올리는 공격적인 로드맵에 힘입어 2027년에도 HBM 수요의 대부분을 차지할 것입니다.
Broadcom이 TPU와 MTIA 볼륨이 급증하면서 뒤를 따르고, OpenAI와 SoftBank의 증분 프로젝트가 작지만 눈에 띄는 상승을 더합니다. Amazon도 주요 HBM 고객 중 하나로 부상하고 있습니다. Amazon의 경우 설계 파트너를 통하지 않고 직접 HBM을 조달하여 비용을 낮추는 전략을 가지고 있습니다.

출처:SemiAnalysis 프로세스 흐름: 프런트엔드 (전공정)
일반 DDR DRAM 용량이 HBM 용량으로 "변환"될 때 가장 큰 변화는 TSV 형성을 위한 도구 추가와 HBM 웨이퍼가 양면에 범핑됨에 따라 범핑 용량이 증가한다는 것입니다. 이 두 단계 모두 3D 스택을 구현하기 위한 것입니다. 단, 상단 다이에 사용되는 웨이퍼는 단면 범프만 필요하고 TSV가 필요하지 않으므로 제외됩니다.
TSV는 via (통로) 를 생성하기 위한 식각(etching) 장비와 이를 채우기 위한 증착(deposition) 및 도금 장비가 필요합니다. TSV를 드러내기 위해서는 그라인더, 추가 식각 단계, 그리고 이 공정에 사용되는 캐리어 웨이퍼를 부착하기 위한 임시 본더가 필요합니다.
이것이 HBM 용량이 이제 TSV 용량으로 표기되는 이유입니다. TSV는 DDR 웨이퍼를 HBM 웨이퍼로 만드는 주요 증분 공정이기 때문입니다.
범핑의 경우, 주로 증착, 도금, 박리 공정을 거칩니다. 또한, Camtek과 Onto의 광학 검사 장비 (레이저 삼각측정을 통한 높이 측정 장비) 를 사용하여 범프에 결함이 없고 정확한 프로파일인지 확인할 수 있습니다.

출처: Applied Materials
프로세스 흐름: 패키징
이 기술의 또 다른 부분은 하이닉스가 MR-MUF를 통해 지속적으로 추진하고 있는 백엔드 패키징입니다. 간단히 말해, MR-MUF(Mass Reflow-Molded Underfill)는 더 높은 생산성과 더 나은 열 성능을 제공합니다. 하이닉스가 독자적으로 개발한(일본 NAMICS와 공동 개발한) 몰드 언더필 소재는 마이크론과 삼성에서 사용하는 Non Conductive Film (비전도성 필름) 보다 더 뛰어난 방열 성능을 제공합니다. 하이닉스는 휨 현상을 관리하는 다른 방법을 발견했기 때문에 열압착 접합(TCB)을 피할 수 있었습니다. TCB의 장점 중 하나는 힘을 사용하여 접합 물질을 안정화하는 것입니다.
반면, 힘을 가하면 범프가 손상될 위험이 커집니다. 범프에 압력(stree)를 가하기 위해 SK는 더미 범프를 더 추가하여 열 방출에도 도움이 될 수 있습니다.

출처: SK하이닉스 
출처: SK하이닉스
이 공정은 생산성도 훨씬 높습니다. TC-NCF (Thermally Compress-Non Conductive Film)를 사용하는 경우 각 층의 접합부 형성에 전체 TCB 단계를 사용하는 것과 달리, 일괄 대량 리플로우 및 단일 오버몰드 단계를 통해 접합부를 형성합니다.

출처: SK하이닉스 프로세스 흐름: 수율
HBM은 다른 DRAM 폼팩터보다 기술적으로 더 정교한 제품이며, 특히 높은 3DIC 스택을 고려할 때 더욱 그렇습니다. 따라서 패키징 수율은 제조업체들이 기존 제품에 비해 기대하는 수준에는 미치지 못할 것입니다. 그러나 프런트 엔드 수율 또한 까다로우며, 프런트 엔드 수율이 더 큰 문제라고 생각합니다. 앞서 언급했듯이 HBM은 속도 측면에서는 그다지 까다롭지 않은데, 왜 이런 현상이 나타나는 것일까요?
그 이유는 3DIC 어셈블리와 TSV로 거슬러 올라갑니다. TSV가 스택까지 전력을 공급할 수 있어야 하는 Power Distribution Network (PDN / 전력분배망)이 과제 중 하나입니다. TSV 레이아웃과 설계는 독점적이며, 여러 제조업체를 차별화하는 주요 요소 중 하나입니다.
HBM의 핵심 과제 중 하나는 전력 TSV를 통해 스택에 전력을 공급하는 것입니다. 특히 메모리 리프레시 동작은 많은 전력을 소모하므로 전력 분배 네트워크 설계가 중요합니다. 하이닉스의 HBM3E는 주변 장치 면적을 줄이고, 두 개의 전력 TSV 뱅크 대신 다이 전체에 전력 TSV를 적용하여 TSV 수를 거의 6배 늘렸습니다. 그 결과, SKH는 VPP(Voltage Proposition 1)의 IR 강하를 최대 75%까지 크게 낮출 수 있었습니다.
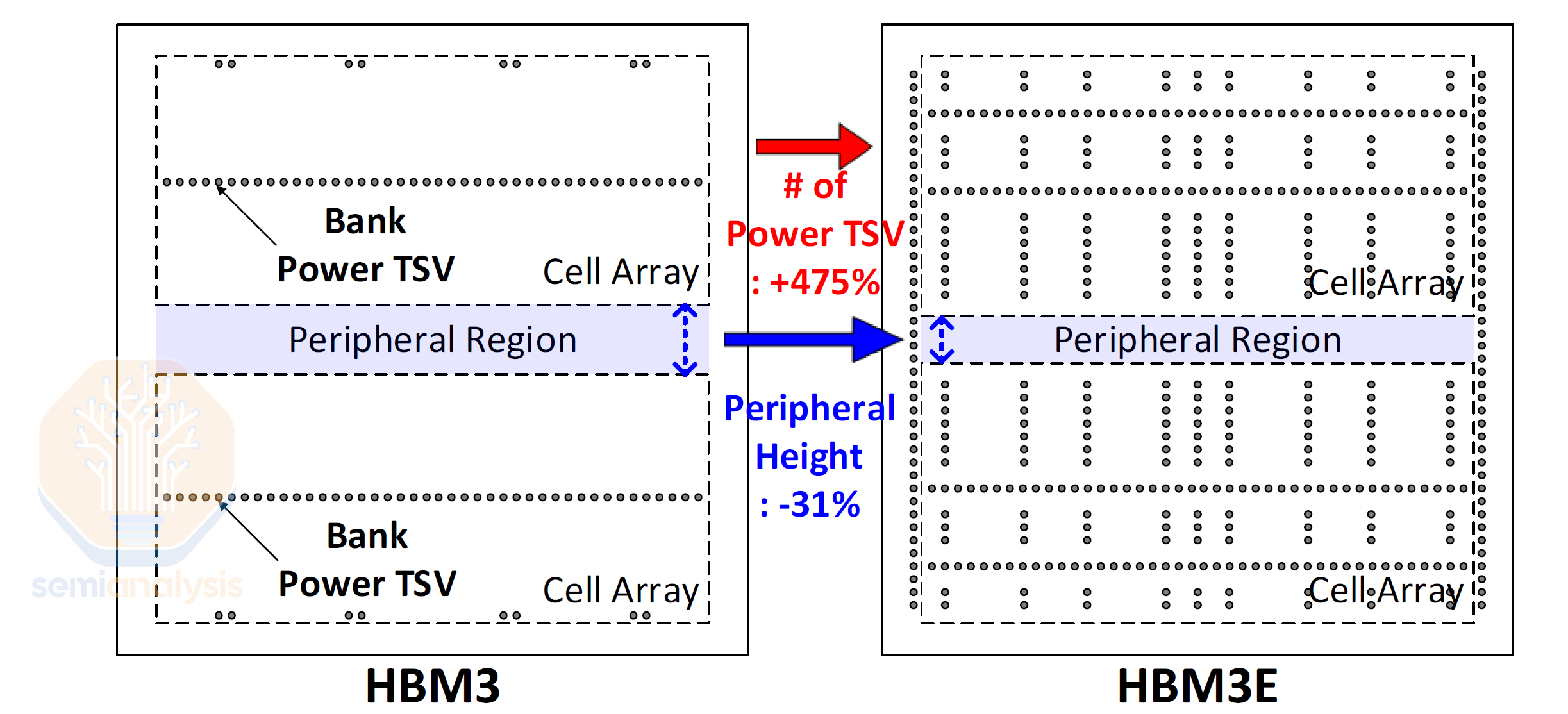
출처: SK하이닉스 
출처: SK하이닉스
마찬가지로, 마이크론이 HBM 기술에서 놀라운 도약을 이룬 것은 (마이크론은 표준 HBM3조차 제공하지 않았음) TSV와 전력 공급망에 집중했기 때문입니다. TSV 네트워크는 마이크론이 전력 소비량을 30% 줄였다고 주장할 수 있는 차별화 요소로 여겨지지만, 아직 검증되지는 않았습니다.

출처: 마이크론
또 다른 중요한 점은 전력 및 열 포락선 (the power and thermal envelope) 내에서 약속된 속도를 제공한다는 것입니다. 모든 3DIC 어셈블리와 마찬가지로 열 방출이 문제이며, 특히 DRAM은 열을 좋아하지 않습니다. 하이퍼스케일러 데이터에서 알 수 있듯이 HBM 오류는 GPU 오류의 가장 큰 원인이며, 데이터 센터에서 다른 칩보다 더 자주 발생합니다.
모든 제조업체의 절대 수율은 기존 메모리 웨이퍼에 비해 기존보다 훨씬 낮기 때문에, 이는 상대 수율과 최종 경제성의 문제입니다. SK와 마이크론의 경우, 수율 손실은 높은 가격으로 충분히 만회할 수 있기 때문에 HBM은 마진을 증가시킵니다. 삼성의 수율은 더욱 심각합니다. 아이러니하게도, 낮은 수율로 인해 전체 DRAM 웨이퍼 공급이 줄어들어 가격 상승으로 이어집니다.
이는 층 수로 이어집니다. 층 수가 많을수록 달성하기 더 어렵습니다. 간단히 말해, 단일 층의 적층 수율이 x%라면, 각 층의 수율은 n 결합 단계의 제곱(총 층 수에서 1을 뺀 값)의 x%로 누적됩니다. 층당 적층 수율이 99%인 8층 적층의 경우, 총 수율은 92%가 됩니다. 12층 적층의 경우, 이는 87%가 됩니다. 물론 이는 지나치게 단순화된 설명입니다. 층 수가 많을수록 중요하지 않은 적층 결함이 누적될 수 있으므로 수율이 저하됩니다.
예를 들어, 몇 개의 층에서 작지만 허용 가능한 수준의 비평면성이 더 높은 층에서는 허용할 수 없는 수준의 평면성을 초래할 수 있습니다.
공정 흐름: 본딩 툴, SK하이닉스 와 한미반도체의 드라마
본딩 또는 다이 어태치 단계는 수율에 중요한 영향을 미치므로 정교한 장비가 필요합니다. TSV 피치가 약 40µm이므로 본더는 한 자릿수 또는 서브마이크론 수준의 정렬 정확도를 구현해야 합니다. 여러 층에 걸쳐 악화되는 휨 현상을 방지하기 위해 균일한 압력 분포 또한 중요합니다. 또한, 처리량 또한 비용에 영향을 미치므로 중요합니다.
한미반도체는 당시 시장 선두주자인 베시(Besi)와 ASMPT가 외면했던 HBM용 ThermoCompression(TC) 본더에 집중하기로 조기에 결정했다. 이는 현재 HBM 공정에서 거의 독점적인 지위를 확보하는 결과를 낳았다. SK하이닉스는 작년 가을까지 HBM 공정 점유율이 100%였지만, 한화에 경쟁 장비를 대량 주문했다. 한화 에 더 높은 가격을 지불한 것으로 알려졌다.
이는 한미반도체에 큰 논란을 일으켰는데, 당연히 한미반도체는 Nvidia(최대 규모이자 가장 중요한 HBM 고객)에 대한 Hynix의 HBM 공급 절차에 적격자가 아님에도 불구하고 경쟁자가 더 높은 가격으로 수주하는 것을 보고 화가 났습니다.

출처: 한미반도체
25년 4월 초 한화케미칼이 SK하이닉스 팹에서 현장 서비스팀을 철수시키면서 분쟁은 극에 달했습니다. 서비스 중단으로 하이닉스는 주요 제품을 출하하는 데 몇 달, 아니 몇 주가 걸릴 것이었습니다. 장기적으로는 마이크론과 삼성이 생산 능력 공백을 신속하게 메울 수 없게 되어 가속기 공급망 전체에 위협이 될 것이었습니다. 한화케미칼의 장비는 아직 납품되지 않았고, 지난 가을 주문한 ASMPT 본더는 하이닉스의 12인치 HBM3E에 사용할 수 없었습니다. 이로 인해 SK하이닉스는 한화케미칼에 용서를 구할 수밖에 없었습니다.
https://magazine.hankyung.com/business/article/202504242467b동맹 SK하이닉스와 한미반도체에 무슨 일이…반도체 업계 ‘술렁’
동맹 SK하이닉스와 한미반도체에 무슨 일이…반도체 업계 ‘술렁’, 안옥희 기자, SK하이닉스
magazine.hankyung.com
엄청난 압박 속에서 SK하이닉스는 최근 몇 주 동안 한미반도체에 소량 주문을 했습니다. 이는 대량 주문보다는 한미반도체를 달래기 위한 조치로 보이지만, 장비 현장 서비스를 재개하기에는 충분했습니다. ASMPT, Besi 등이 HBM 전용 TC 본더 개선에 박차를 가하고 있는 만큼, 한미반도체가 독점적 지위를 이용해 더 이상 힘을 내기 어려울 것으로 보입니다.
https://www.hankyung.com/article/2025051683511하이닉스, 한미반도체와 거래 재개
하이닉스, 한미반도체와 거래 재개, HBM TC본더 428억 계약 갈등 봉합 전망 속 "불씨 여전" 같은 날 한화세미텍도 납품
www.hankyung.com
중국: CXMT & Huawei HBM
수출 제한으로 인해 모든 raw HBM 스택의 중국 내 반입이 금지됩니다. 그러나 HBM이 장착된 칩은 FLOPS 규정을 초과하지 않는 한 여전히 운송이 가능합니다. 현재 금지된 HBM은 CoAsia Electronics, Faraday, SPIL이 참여하는 네트워크를 통해 중국으로 재수출되고 있으며, 이를 통해 중국 최종 사용자는 GPU 패키지에서 HBM을 디솔더링하고 회수할 수 있습니다.
HBM은 가속기의 핵심 요소 중 하나이고, 수출 제한으로 HBM 공급이 중단될 위기에 처해 있는 상황에서 중국은 자연스럽게 국내 개발에 자원을 투자하고 있습니다. 중국은 향후 5년간 국산 반도체에 2,000억 달러(USD)의 보조금을 지원할 계획이며, 상당 부분이 HBM에 투자될 것으로 예상됩니다. DRAM 업계 선두주자인 CXMT는 HBM 생산 능력을 적극적으로 확대하고 있으며, 개정된 수출 규제(미국은 2024년 12월, 한국은 최근 HBM 규제 강화)에 대응하기 위해 막대한 장비 비축을 확보하고 있습니다.
HBM2 8세대는 2025년 상반기에 양산을 시작할 예정이며, TSV 생산 능력은 연말까지 마이크론과 맞먹을 것으로 예상됩니다.
https://biz.chosun.com/it-science/ict/2025/08/14/OL2ZS7FKPVEOJOPYV62U4G7UVY/中 ‘AI 굴기’ 발목 잡는 HBM 수급난… CXMT, 대규모 설비 투자 재개
中 AI 굴기 발목 잡는 HBM 수급난 CXMT, 대규모 설비 투자 재개 HBM 부족에 AI 굴기 발목 잡힌 中 DDR4 생산 장비 활용하던 CXMT DDR5·HBM 양산 위해 장비 발주 D램 기술력 韓 기업 대비 2~3년 뒤처져 단기간
biz.chosun.com
진입하고 싶지 않은 첨단 기술 시장은 본 적이 없는 화웨이는 자체 HBM 계열사를 보유하고 있으며, XMC(우한 신신)에서 HBM 웨이퍼를 생산하고 SJSemi(성허 징웨이 반도체)에서 패키징합니다.
현재 생산 능력은 대량 생산이 아닌 R&D 규모이지만, 향후 수년 내에 증설할 계획입니다. XMC와 SJSemi는 모두 상장 기업으로, 미국산 부품이 사용된 장비를 구매할 수 없습니다. (글로벌파운드리는 최근 라이선스 없이 SJSemi에 1,700만 달러 이상의 칩을 판매했음에도 불구하고 징계를 받았습니다.)
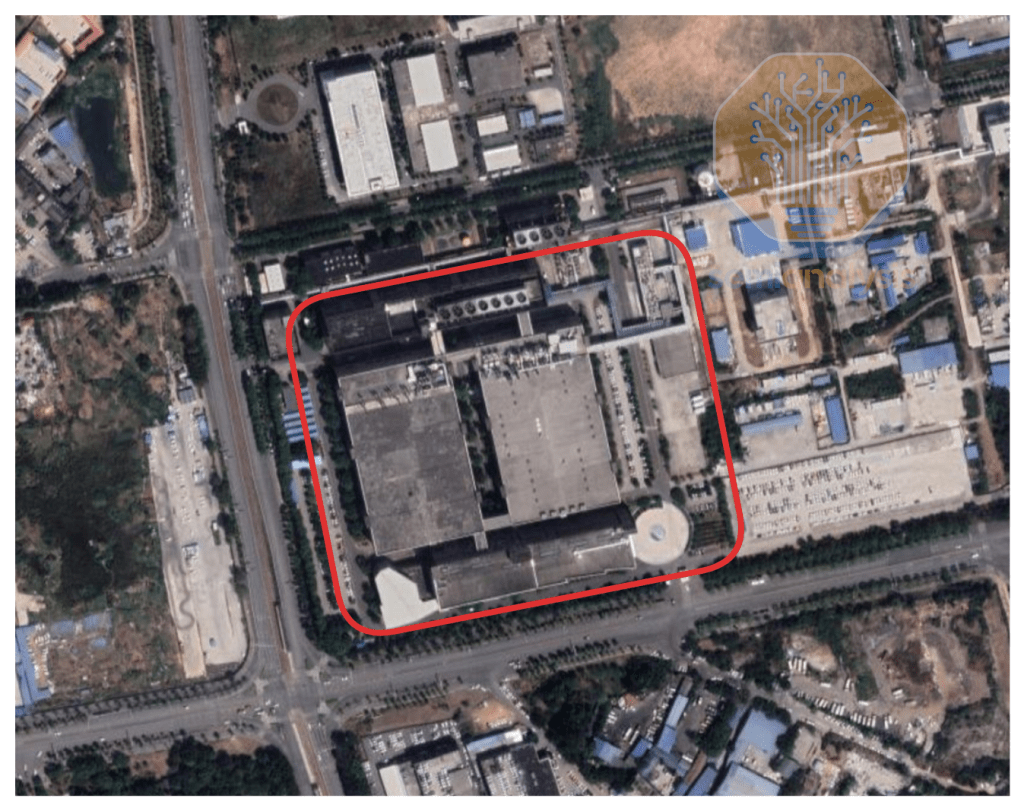
XMC’s DRAM / HBM fab, supplying Huawei’s domestic HBM efforts. (출처: Google, SemiAnalysis) HBM 스택 카운트 - 하이브리드 본딩을 할 것인가 말 것인가?
HBM 스택의 층이 더 많아질수록 메모리 용량도 더 커집니다. 세대가 바뀔 때마다 층 수는 더 많아졌습니다. 이 스택 높이는 지금까지 720마이크론 높이의 큐브(현재 JEDEC 표준) 안에 들어갔습니다.
더 많은 층을 넣기 위해 각 다이(후속 패키징 단계에서 취급을 견딜 수 있도록 훨씬 두꺼워야 하는 최상단 다이 제외)는 더 얇아졌고, 다이 사이의 범프 갭 또한 더 얇아져 더 많은 층을 넣을 수 있는 공간이 확보되었습니다. 얇아진 다이는 취급이 점점 더 어려워지고, 따라서 휘어짐과 파손에 더 취약해져 수율에 악영향을 미칩니다.
HBM에 하이브리드 본딩(HB)을 적용하는 주요 이점은 범프가 없다는 것입니다. 범프 갭을 제거함으로써 더 많은 DRAM 코어 레이어를 장착할 수 있는 공간이 확보됩니다.
이는 수율 및 비용 측면에서 여러 가지 새로운 과제를 야기하는데, 특히 HBM은 하이브리드 본딩이 제공하는 수준의 상호 연결 밀도를 필요로 하지 않기 때문에 이러한 과제를 해결하는 것이 바람직하지 않을 수 있습니다.
제조업체들은 하이브리드 본딩에서 패드 밀도를 얼마나 완화하여 본딩 정확도 요건을 완화하고 HBM에 이 기술을 더욱 적용 가능하게 할 수 있는지 연구하고 있습니다. HB는 전력 및 발열 측면에서도 일회성 이점을 제공하지만, 가장 큰 이점은 스택 높이입니다.
HBM에 HB를 도입하는 것은 항상 "차세대" 기술이었고, 그 목표는 계속해서 바뀌고 있습니다. D2W 하이브리드 본딩의 경우, 2층 구조에서는 수율을 수용 가능한 수준으로 끌어올리는 것이 매우 어렵고 비용이 많이 듭니다. 16층 이상으로 이 문제를 확장한다고 상상해 보세요. 메모리 업체들은 아직 하이브리드 본딩 기술 개발 초기 단계에 있습니다. TSMC의 경험에 따르면, HB 도입이 양산 단계에 도달하기까지는 오랜 시간이 걸렸으며, 고급 로직에서 성능 이점이 더 명확하게 드러나더라도 도입에는 오랜 시간이 걸렸습니다.
HBM3와 HBM3E는 최대 12층 스택까지 확장되고 있으며, 범프 기반 인터커넥트를 통해 12layer는 현재 720um 큐브 두께 내에서 한계에 도달했습니다. 더 높은 스택을 구현하기 위한 두 가지 해결책은 범프를 없애거나 스택을 더 높이거나 두껍게 만드는 것입니다. 하이브리드 본딩 채택에 대한 반발로, JEDEC은 스택 높이를 775um로 완화하기로 결정했습니다.
높이 완화는 더욱 확대될 수 있습니다. 775um는 실리콘 웨이퍼의 표준 두께입니다. HBM은 함께 패키징되는 로직 다이와 동일한 높이여야 합니다. 775um보다 높은 두께를 구현하려면 로직 웨이퍼도 더 두꺼워야 하며, 현재 장비는 더 두꺼운 웨이퍼를 수용하도록 설계되지 않았습니다.
한 가지 가능한 해결책은 로직 아래에 있는 인터포저 몰딩을 높여 로직을 높이고 인접한 HBM과의 동일 평면성을 확보하는 것입니다. 하지만 이렇게 하면 트레이스가 길어지고 상호 연결을 위한 실리콘 브리지 구현이 간단하지 않을 수 있습니다.

출처: SemiAnalysis
처음에는 HBM4에 HB 구현에 대한 논의가 더 많았지만, 현재는 4E로 다시 옮겨갔습니다. 최근 하이닉스와 마이크론은 HB 도입에 대해 훨씬 더 조용한 반면, 삼성은 가장 큰 목소리를 내고 있습니다. 이는 삼성이 종종 가장 공격적인 기술 구현을 통해 추격을 시도하지만, 예상대로 실행에 실패하는 전형적인 사례입니다. 이로 인해 삼성은 더욱 뒤처지게 됩니다.
16층은 스택 높이를 높여 해결되지만, 20층 이상으로 올라가려면 범프 갭을 더욱 줄이고 웨이퍼 두께를 더욱 얇게 만들어야 하거나, 아니면 16층에서 한계에 도달할 가능성이 높습니다. 스택 높이를 높이면 밀도를 높일 수 있지만, 스택이 많을수록 대역폭과 밀도가 향상됩니다.처리량 최적화: I/O는 AI 가속기의 핵심
AI 가속기의 핵심 특징은 고도로 병렬화되고 처리량에 최적화되어 있다는 것입니다. 가속기는 연산의 복잡성을 희생하여 가속기가 초당 수행할 수 있는 총 연산 수를 극대화하도록 설계되었습니다.
대부분의 가속기는 AI 학습 및 추론 워크로드에서 주로 사용되는 일반 행렬 곱셈(General Matrix Multiplication /GEMM)의 곱셈 및 덧셈 연산에 중점을 둡니다. 이는 초당 실행할 수 있는 명령어 수에 중점을 두는 CPU와 비교되지만, CPU 코어는 훨씬 더 "스마트"하여 훨씬 더 많은 회로와 면적을 필요로 합니다. 따라서 CPU는 훨씬 낮은 처리량으로 다양한 복잡한 작업을 실행하도록 설계되었습니다.
이는 AI 가속기가 메모리와 스케일업 및 스케일아웃 패브릭을 위해 많은 오프칩 대역폭을 필요로 한다는 것을 의미합니다. 처리된 데이터를 칩 외부로 이동시키는 동시에 가속기 유닛에 처리할 더 많은 데이터를 공급하기 위해서는 대역폭이 필요합니다.
충분한 대역폭이 없으면 XPU의 컴퓨팅 요소들이 활용되지 않아 모든 병렬 컴퓨팅 성능을 제공하는 목적이 달성되지 않습니다. 먼저 메모리 요구 사항부터 살펴보겠습니다.메모리 컨텐츠 증가
더 높은 성능을 제공하기 위해 메모리 용량과 대역폭, 그리고 FLOPs를 늘리는 것이 가속기 로드맵에서 가장 중요하며 쉽게 확인할 수 있습니다. 용량과 대역폭이 확장되는 세 가지 측면이 있습니다.
- 최신 세대의 HBM은 더 빠른 신호 속도와 더 밀도가 높은 코어 다이를 통해 더 높은 대역폭을 제공합니다.
- 스택당 레이어 수를 늘리면 용량이 증가합니다. 12개 레이어로 구성된 HBM이 주류 구성으로 자리 잡는 시점에 있습니다.
- 패키지당 HBM 스택을 더 추가하면 대역폭과 용량이 더 늘어납니다.
엔비디아의 로드맵에서 이를 확인할 수 있습니다. HBM 용량은 A100의 80GB HBM2E에서 Rubin Ultra의 1024GB HBM4E로 폭발적으로 증가했습니다. 칩당 메모리 대역폭 또한 크게 증가했습니다. Ampere에서 Blackwell Ultra에 이르기까지, 부품 구성에서 절대적 및 상대적 증가폭이 가장 큰 부분은 HBM 콘텐츠 추가이며, 이는 메모리 공급업체(특히 SK 하이닉스)에게 유리하게 작용합니다.

출처: SemiAnalysis
이는 비메모리 I/O의 필요성과도 관련이 있습니다. 단일 메모리 일관성 도메인에서 더 많은 GPU를 확장하면 더 큰 총 메모리 용량과 대역폭을 확보할 수 있습니다. 이를 통해 더 큰 매개변수 모델의 추론을 확장하고 추론 모델과 복잡한 워크로드에서 널리 사용되는 훨씬 더 긴 컨텍스트 길이를 지원할 수 있습니다.
파킨슨의 법칙이 할당된 시간을 채우기 위해 작업이 확장된다는 것을 관찰하는 것처럼, 현대 AI는 신경망 아키텍처가 사용 가능한 모든 HBM을 차지하기 위해 끊임없이 커지는 "메모리 파킨슨" 역학을 따릅니다. H100에서 3TB/s로 80GB이든 GB200에서 8TB/s로 192GB이든 HBM 용량과 처리량이 세대를 거듭할수록 증가하면 설계자는 매개변수 수, 컨텍스트 길이, KVCache 공간을 늘려야 하며, 몇 달 전까지만 해도 충분해 보였던 여유 공간이 사라집니다.
한때 모델을 빠듯한 예산에 맞추기 위해 사용되었던 기술(활성화 검사점, 최적화기 오프로딩, 가중치 양자화)은 새로운 HBM 공간이 생기자마자 완화되다가, 메모리 벽에 다시 부딪히게 되면 효율성 트릭을 다시 찾아야 합니다. 실제로 더 크고 빠른 HBM이 있다고 해서 지속적인 여유 공간이 생기는 것은 아닙니다.
대신 "적절한" 모델 크기에 대한 기준을 재설정하여 실리콘 기술의 발전에도 불구하고 용량과 대역폭이 제한 요소로 남도록 합니다. AI 칩에 HBM이 더 많이 할당됨에 따라 개발자들은 이를 채우기 위해 더 큰 모델을 즉시 구축하게 되므로, 메모리가 항상 다음 병목 지점이 됩니다. HBM이 어떻게 사용되고 어떤 부분에서 문제가 발생하는지 살펴보겠습니다.추론에서의 HBM 사용
LLM 추론에서 모든 모델 가중치는 패키지 내 HBM 메모리에 영구적으로 저장되므로 GPU가 지연 없이 가져올 수 있습니다. HBM은 가중치와 함께 KV 캐시도 보유합니다. 모델이 다음 토큰을 생성하라는 요청을 받을 때마다 GPU는 먼저 HBM에서 가중치를 읽고 동시에 전체 KV 캐시를 검색하여 셀프 어텐션 단계에서 새 토큰을 대화 기록과 비교합니다. 계산 후, GPU는 새로 생성된 토큰에 대한 새로운 키와 값을 HBM에 다시 추가하여 캐시를 확장합니다.
모든 토큰 디코딩 단계에서 정적 가중치와 끊임없이 증가하는 KV 캐시를 반복적으로 읽기 때문에 이는 대역폭에 큰 부담을 줍니다. 메모리 대역폭이 이 데이터를 초당 수백 기가바이트의 속도로 이동할 수 없다면, GPU는 계산을 수행하는 것보다 메모리 대기에 더 많은 시간을 소비하게 됩니다. 실제로는 대역폭이 토큰 디코딩의 계산 집약도를 크게 압도하기 때문에 대부분의 LLM 추론 워크로드가 계산 중심이 아닌 메모리 대역폭 중심이 되기 때문에 이러한 현상이 발생합니다.
모델이 발전함에 따라, 그 범위도 늘어났습니다. 이는 모델이 더 오랜 시간 동안 생각하고, 계획하고, 행동할 수 있다는 것을 의미합니다. 이러한 증가율은 기하급수적으로 증가했으며, 이미 우수한 제품에서 그 효과가 나타나고 있습니다. 예를 들어, OpenAI의 Deep Research는 한 번에 수십 분 동안 생각할 수 있는 반면, GPT-4는 단 수십 초밖에 생각하지 못했습니다.
모델이 장시간에 걸쳐 생각하고 추론할 수 있게 되면서, 컨텍스트 길이가 수십만 개의 토큰을 초과하는 경우가 빈번해지면서 메모리 용량에 대한 부담이 폭발적으로 증가합니다. 토큰당 생성되는 KVCache의 양을 줄이는 최근의 발전에도 불구하고, 메모리 제약은 여전히 빠르게 증가하고 있습니다. 이러한 문제를 해결하는 한 가지 방법은 추론 모델을 더 낮은 배치 크기로 처리하는 것이었는데, 이는 경제성에 악영향을 미칩니다.
AI 발전의 주요 원동력은 강화 학습(RL)이며, RL 패러다임의 큰 부분은 추론입니다. 예를 들어, RL에 필요한 것은 엄격한 요구 사항을 충족하는 합성 데이터이며, 이는 나중에 다른 모델에 의해 필터링되는 데이터를 생성하기 위해 수많은 GPU 시간 분량의 추론을 수행해야 함을 의미합니다.
추론 부하가 큰 또 다른 예로는 창작 글쓰기와 같이 검증하기 어려운 작업을 위한 RL이 있습니다. 쉽게 검사하고 검증할 수 있는 코드와 달리 창작 글쓰기, 법률 작업, 교육과 같은 것은 쉽게 검증할 수 없습니다. 이를 해결하고 모델을 강화하고 개선할 신호를 얻는 방법은 다른 모델이 답을 평가하도록 하는 것입니다.KVCache 오프로드
희소한 HBM에 대한 부담을 줄이기 위해 다양한 알고리즘이나 설정 개선이 시도되고 있습니다. 한 가지 방법은 KVCache를 기존 DDR이나 스토리지와 같이 더 저렴하고 가용성이 높은 메모리 계층으로 이전하는 것입니다.
오늘날 KVCache 오프로딩은 이미 널리 사용되고 있습니다. Nvidia는 이를 위한 Dynamo Distributed KVCache Manager라는 프레임워크를 제공합니다. 개념적으로 이는 범용 CPU에서 사용 가능한 여러 계층의 메모리, 즉 매우 빠르지만 밀도가 낮은 L1/2/3 캐시와 느리지만 밀도가 높은 DRAM과 크게 다르지 않습니다.
AI 시스템에서는 KV가 저장되는 위치가 사용 빈도를 기반으로 관리됩니다. 잘 최적화된 시스템은 현재 사용되는 모든 KV를 HBM에, 자주 사용되지 않는 KV는 DDR에, 그리고 매우 드물게 사용되는 KV는 NVMe에 저장합니다.
DRAM이 CPU의 L1/L2/L3 캐시 수요를 잠식하지 않는 것처럼, HBM과 DDR/SSD 오프로드는 서로 직접적으로 경쟁하지 않습니다. 실제로 대부분의 최신 LLM 워크로드에서 사전 채우기 속도(KVCache 생성 속도)는 일반적으로 DDR 또는 NVMe SSD로의 전송 속도보다 느리기 때문에 KV가 HBM에 완전히 존재하는 경우는 거의 없습니다.
생성된 KV는 제거되거나 디코드 노드로 전송되어 다음 토큰 생성에 사용됩니다. HBM에 저장된 모든 사용자에 대해 사용되는 시스템 프롬프트와 활성 시퀀스 윈도우 및 일부 프리페치 버퍼와 같은 다른 핫 KV가 주로 사용됩니다.
DDR과 NVMe 중 무엇을 사용할지는 워크로드 요구 사항과 워크로드 규모에 따라 달라집니다. 또한, 워크로드 사이클 빈도도 중요한데, 자주 사이클되는 KV는 NAND의 제한된 쓰기/재쓰기 허용 범위에 적합하지 않기 때문입니다.
도구 호출을 사용하여 매우 낮은 지연 시간과 높은 사이클 속도로 문서와 데이터를 가져오는 에이전트 기반 사용 사례는 캐싱을 NVMe에서 DDR로 더욱 확대하고 있습니다. 이는 서로의 직접적인 대체물이 아니라 아키텍처 및 사용자 경험 측면에서 고려해야 할 트레이드오프입니다.
사용 사례가 발전함에 따라 다양한 추론 요구 사항에 맞는 다양한 하드웨어 설정이 사용될 수 있습니다. 예를 들어, 고정된 코드 베이스 또는 문서를 쿼리하는 경우, 사용자당 GPU당 더 많은 양의 KVCache에 액세스하는 것이 유리합니다. 이러한 사용자 동작은 일반 채팅에 비해 메모리 요구량이 매우 높기 때문입니다.사전 훈련을 위한 HBM
기존 사전 학습의 경우, GPU가 순방향 및 역방향 단계에 필요한 모든 것이 HBM을 통과합니다.
먼저, 모델의 가중치는 HBM에 저장되어 각 계층이 데이터 배치에 대한 순방향 패스를 계산하는 동안 빠르게 읽을 수 있습니다.
각 계층은 배치를 처리할 때 중간 활성화 값을 HBM에 기록하여 나중에 사용할 수 있도록 합니다. 순방향 패스가 완료되고 손실이 계산되면 역방향 패스가 시작됩니다.
GPU는 저장된 활성화 값과 가중치를 다시 검토하여 HBM에서 읽어 기울기를 계산합니다.
결과 가중치 기울기와 보조 옵티마이저 통계(예: Adam의 모멘텀 또는 분산 항)도 HBM에 기록됩니다.
마지막으로 옵티마이저는 HBM에서 이러한 기울기와 통계를 읽어 다음 반복을 위한 가중치를 업데이트합니다.
그러나 학습 작업은 데이터 전송에 비해 더 많은 컴퓨팅을 필요로 하므로 학습은 컴퓨팅 바운드(compute bound)되는 경우가 더 많습니다. 그러나 위에서 언급했듯이 강화 학습(RL)은 이제 모델 성능 향상의 핵심입니다. 따라서 기존에 사전 학습을 통해 달성했던 것이 강화 학습의 형태로 추론에 가까워지고 있습니다.
원문 출처
https://semianalysis.com/2025/08/12/scaling-the-memory-wall-the-rise-and-roadmap-of-hbm/Scaling the Memory Wall: The Rise and Roadmap of HBM
The first portion of this report will explain HBM, the manufacturing process, dynamics between vendors, KVCache offload, disaggregated prefill decode, and wide / high-rank EP. The rest of the repor…
semianalysis.com
반응형'TechStock&Review > SemiConduct' 카테고리의 다른 글
Huawei Ascend 생산 증가: Die Banks 와 HBM 병목 현상 (25.9.11) (1) 2025.09.11 칼 자이스(Carl Zeiss)의 역사와 EUV 리소그래피 광학 (25.9.3) (0) 2025.09.03 HBM 개발사: AI 시대를 연 메모리 혁명의 전개 과정 (25.7.4) (7) 2025.07.04 NVIDIA 텐서 코어 진화 - Volta 에서 Blackwell 까지 (25.6.26) (5) 2025.06.26 화웨이의 야심작, Ascend 910C 칩 & CloudMatrix384 시스템의 흥미로운점 (2025.6.21) (4) 2025.06.21