-
화웨이의 야심작, Ascend 910C 칩 & CloudMatrix384 시스템의 흥미로운점 (2025.6.21)TechStock&Review/SemiConduct 2025. 6. 21. 12:44
최근 화웨이가 공개한 AI 칩 Ascend 910C와 이를 기반으로 한 CloudMatrix384 시스템에 대한 기술 분석 자료가 공개되었습니다. 엔비디아의 아성에 도전하는 화웨이의 기술력은 과연 어느 수준까지 도달했을까요?
Ascend 910C, H100 와 주요 스펙 비교
먼저, AI 연산의 핵심인 NPU(신경망 처리 장치) 레벨에서 Ascend 910C의 주요 사양을 살펴보겠습니다. 비교 대상은 현재 AI 칩 시장의 절대 강자, 엔비디아의 H100입니다.
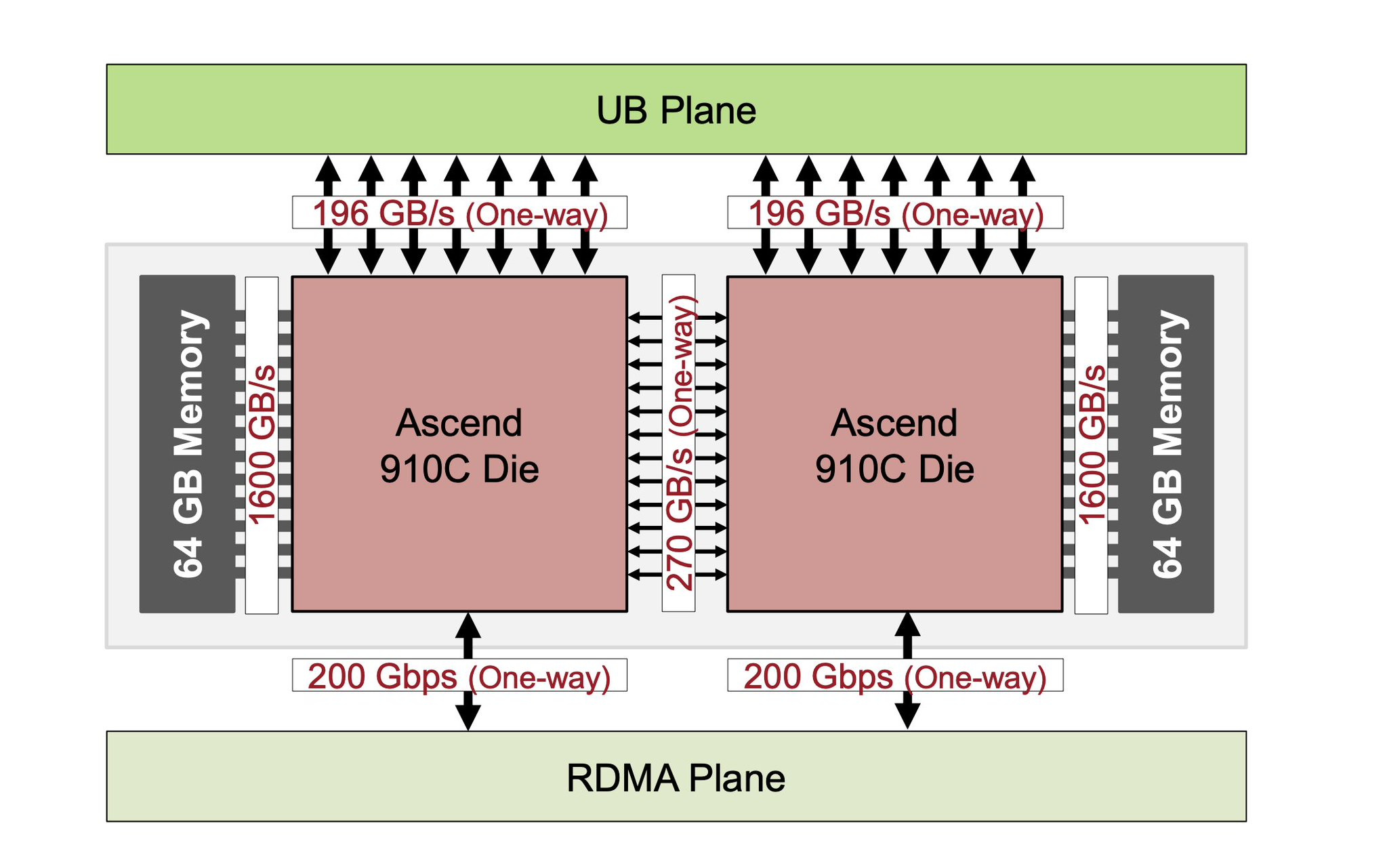

항목 화웨이 Ascend 910C 엔비디아 H100 (비교) 최대 연산 처리량 (FP16) 752 TFLOPS 989 TFLOPS (910C는 H100의 76% 수준) 메모리 (HBM) 128 GB (HBM2e) 80 GB (910C가 160% 더 많음) 메모리 대역폭 3.2 TB/s 3.35 TB/s (910C는 H100의 96% 수준) 다이-투-다이(D2D) 대역폭 540 GB/s (양방향) N/A (단일 다이) 910C의 연산량은 H100 대비 76% 수준이지만 H100보다 60%나 더 많은 메모리 용량을 자랑하며, FP16 연산 능력과 메모리 대역폭도 H100에 근접하는 수준입니다.
흥미로운 점은 910C가 기존의 910B 다이(die) 두 개를 하나로 합친 구조라는 것입니다. 분석에 따르면, 각 다이는 24코어에 376 TFLOPS의 성능을 내는 것으로 보입니다.숨겨진 약점: 뒤처진 패키징 기술
하지만 이번 분석을 통해 새롭게 드러난 '다이-투-다이(D2D) 대역폭'은 화웨이의 명백한 한계를 보여줍니다. D2D 대역폭이란 칩 내부에서 분리된 다이(실리콘 조각) 간의 데이터 전송 속도를 의미하는데, 910C는 이 수치가 540 GB/s에 불과합니다.
이는 2021년에 출시된 AMD의 MI250(400 GB/s)과 비슷한 수준이며, 최신 기술과는 상당한 격차를 보입니다. 참고로 엔비디아의 최신 '블랙웰' 아키텍처는 D2D 대역폭이 무려 10 TB/s에 달합니다. 이는 910C보다 거의 20배나 빠른 속도입니다.
📌 참고:
23년 6월에 발표한 애플 M2 Ultra 프로세서 간(다이-투-다이) 대역폭은 2.5TB/s 로 AI 모델 학습과 추론에서 가장 병목현상이 자주 발생하는 구간은 메모리 리소스이다. 메모리 I/O 대기시간 때문에 GPU Tensor 코어 유휴 상태에 자주 노출되는것은 흔한 일이므로 화웨이측 에서는 전략적으로 메모리대역폭 증대에 자원을 집중한 것으로 보인다.
이러한 차이는 중국 내 첨단 패키징 기술의 한계를 명확히 보여주는 지표입니다. D2D 대역폭이 낮으면 두 다이 간 데이터를 주고받는 과정에서 병목 현상이 발생하여, 대규모 AI 모델의 학습 및 추론 속도가 저하될 수밖에 없습니다.
따라서 AI 엔지니어들은 910C를 사용할 때, 두 다이를 마치 별개의 칩처럼 여기고 데이터 이동을 최소화하는 방향으로 신중하게 접근해야 합니다. 이런 관점에서 보면, 단일 칩으로 구성된 엔비디아 H100이 훨씬 효율적인 선택지로 보입니다.2025.05.07 - [TechStock&Review] - 화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답 (25.5.7)
화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답 (25.5.7)
화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답화웨이는 새로운 AI 가속기와 랙 스케일 아키텍처로 큰 반향을 일으키고 있습니다. Ascend 910C를 기반으로 제작된 중국 최신의 가장
spedtrder.tistory.com
화웨이의 돌파구: 네트워킹 혁신, CloudMatrix384
물론 화웨이도 이러한 약점을 보완하기 위한 노력을 기울이고 있습니다. 바로 'CloudMatrix384'로 대표되는 스케일업(Scale-up) 및 스케일아웃(Scale-out) 네트워킹 기술입니다. 칩 내부의 약점을 칩과 칩, 시스템과 시스템을 연결하는 외부 네트워킹 기술의 혁신으로 일부 만회하려는 전략으로 풀이됩니다. 이러한 전략을 구사할 수 있었던 이유는 화웨이의 근원 사업이 네트워크 통신장비 였기 때문에 자신이 가진 장점을 크게 발휘한 것으로 보입니다.
Pushing the Limits: Huawei's AI Chip Tests U.S. Export Controls | Center for Security and Emerging Technology
Since 2019, the U.S. government has imposed restrictive export controls on Huawei—one of China’s leading tech giants—seeking, in part, to hinder the company’s AI chip development efforts. This data snapshot reveals how exactly Huawei’s latest AI
cset.georgetown.edu
📌 참고:
스케일업 (Scale-up, 수직 확장)
스케일업은 하나의 시스템 또는 서버의 성능을 높이는 방식입니다. GPU 클러스터의 맥락에서 스케일업은 다음과 같은 의미를 가집니다.- 하드웨어 업그레이드: 기존 서버 내의 GPU, CPU, RAM, 스토리지 등의 하드웨어 사양을 더 고성능의 부품으로 교체하거나 추가하는 것을 말합니다. 예를 들어, 더 많은 CUDA 코어를 가진 GPU로 교체하거나, GPU 메모리를 늘리는 식입니다.
- 고속 인터커넥트 활용: 하나의 서버 내에서 여러 개의 GPU를 NVLink와 같은 고속 인터커넥트 기술로 연결하여 GPU 간의 데이터 전송 속도를 극대화하고, 마치 하나의 거대한 GPU처럼 작동하도록 합니다. 엔비디아의 DGX 시스템이 대표적인 스케일업 솔루션이라고 할 수 있습니다.
스케일아웃 (Scale-out, 수평 확장)
스케일아웃은 기존 시스템에 서버나 노드를 추가하여 전체적인 성능과 용량을 확장하는 방식입니다. GPU 클러스터의 맥락에서는 다음과 같습니다.- 서버(노드) 추가: 여러 대의 GPU 서버를 네트워크로 연결하여 하나의 거대한 GPU 클러스터를 구성하는 것을 말합니다. 각 서버는 독립적으로 작동하면서도, 분산 학습 프레임워크 등을 통해 협력하여 작업을 처리합니다.
- 로드 밸런싱: 추가된 서버들에 작업 부하를 균등하게 분산시켜 전체적인 처리량을 높입니다.
- 고속 네트워크: 서버 간의 효율적인 통신을 위해 InfiniBand나 고속 이더넷(RoCE)과 같은 저지연, 고대역폭 네트워크가 필수적으로 요구됩니다.
특징 엔비디아 NVLink 화웨이 CloudMatrix384 핵심 초점 GPU 간의 노드 내/인접 노드 스케일업 전체 슈퍼노드에 걸친 완전한 피어투피어 스케일업 및 클러스터 간 스케일아웃 상호 연결 GPU 간의 전용 고속 링크 UB (Unified Bus) 평면을 통한 NPU, CPU, 메모리 간의 직접적인 All-to-All 연결 메모리 GPU 메모리 간 통합 액세스 분리된 메모리 풀 (CPU DRAM)을 통한 NPU의 균일한 액세스 스케일아웃 외부 RDMA/InfiniBand에 의존 별도의 RDMA 평면 (슈퍼노드 간), VPC 평면 (데이터센터 네트워크 연결) 아키텍처 CPU 중심의 계층적 설계 유지 경향 피어투피어, 리소스 분리 및 독립적 스케일링 혁신 고성능 GPU 상호 연결 AIV-Direct 통신, 분리된 PDC(Prefill-Decode-Caching) 아키텍처, UB 기반 캐싱 기타 주목할 만한 사항들
- FP8 정밀도 미지원: 최신 AI 칩들이 하드웨어적으로 지원하는 FP8 정밀도를 910C는 소프트웨어를 통해 에뮬레이션 방식으로 지원합니다. 이는 성능 저하의 요인이 될 수 있습니다.
- HBM2e 메모리 유지: 메모리 대역폭(3.2 TB/s)을 통해 확인된 사실은 910C가 910B와 동일한 HBM2e 메모리 기술을 사용한다는 점입니다. 최신 HBM3로 업그레이드되지 않았습니다.
참고 원문:https://x.com/jacob_feldgoise/status/1935004781640134970
https://x.com/ohlennart/status/1899488375574278336?s=46
반응형'TechStock&Review > SemiConduct' 카테고리의 다른 글
HBM 개발사: AI 시대를 연 메모리 혁명의 전개 과정 (25.7.4) (7) 2025.07.04 NVIDIA 텐서 코어 진화 - Volta 에서 Blackwell 까지 (25.6.26) (5) 2025.06.26 중국의 반도체 굴기 - EUV 장비, 독자 개발의 현주소와 미래 (25.6.15) (0) 2025.06.15 반도체 경쟁의 패자, 니콘의 화려한 부활? 제조업의 판도를 바꿀 'NXG 600' 이야기 (25.6.14) (4) 2025.06.14 화웨이 Ascend 칩에 대한 미국의 수출 통제 역사와 영향 분석 (25.5.17) (0) 2025.05.16