-
HBM 개발사: AI 시대를 연 메모리 혁명의 전개 과정 (25.7.4)TechStock&Review/SemiConduct 2025. 7. 4. 08:40
제1장 새로운 메모리 패러다임의 서막: HBM은 왜 필요했는가
고대역폭 메모리(High Bandwidth Memory, HBM)의 등장은 단순한 점진적 기술 개선이 아니었다. 이는 고성능 컴퓨팅(High-Performance Computing, HPC)의 발전을 가로막던 '메모리 장벽(Memory Wall)'을 극복하기 위한 필연적인 아키텍처 혁명이었다. HBM의 탄생 배경을 이해하기 위해서는 기존 메모리 기술인 GDDR(Graphics Double Data Rate)이 직면했던 근본적인 한계를 먼저 살펴봐야 한다.
1.1 기존 메모리의 성능 천장: GDDR의 한계
고성능 컴퓨팅, 특히 그래픽 처리 및 과학 연산 분야에서는 프로세서가 데이터를 처리하는 속도보다 메모리가 데이터를 공급하는 속도가 뒤처지는 병목 현상이 심화되고 있었다.[1] 이 '메모리 장벽'은 시스템 전체의 성능 향상을 저해하는 심각한 문제였다. 이러한 한계는 GDDR의 구조적 특성에서 기인했다.
- 평면적(2D) 구조의 한계: GDDR 메모리 칩은 인쇄 회로 기판(PCB) 위에서 GPU 주변에 평면적으로 배치된다.[3] 이로 인해 GPU와 메모리 간 데이터 경로가 길어지고, 이는 필연적으로 신호 지연(latency) 증가와 전력 소비 증대로 이어졌다.[4]
- 좁은 버스와 높은 클럭 속도: GDDR은 상대적으로 좁은 버스(예: 칩당 32-bit, 총 384-bit 또는 512-bit)를 매우 높은 클럭 속도로 동작시켜 대역폭을 확보하는 방식을 사용한다.[4] 이 접근법은 상당한 발열과 전력 소모를 유발하여, 시스템의 열 관리와 에너지 효율성에 큰 부담을 주었다.[4]
- 확장성의 문제: GDDR의 대역폭을 늘리기 위해서는 더 복잡한 PCB 설계, 더 많은 전력 공급, 그리고 더 강력한 냉각 솔루션이 필요했다. 이는 물리적 공간의 제약과 함께 투자 대비 성능 향상률이 점차 감소하는 '수확 체감' 현상을 낳았다.[5]
흥미로운 점은 최신 GDDR7의 개별 핀당 전송 속도는 HBM3E보다 빠를 수 있다는 것이다.10 그러나 HBM의 진정한 강점은 원초적인 클럭 속도가 아니라, 1024-bit 혹은 그 이상의 압도적으로 넓은 인터페이스를 통한 대규모 병렬 처리에 있다. 이는 마치 좁은 도로에서 차들이 고속으로 달리는 것(GDDR)과, 수십 차선의 넓은 도로에서 차들이 적당한 속도로 동시에 움직이는 것(HBM)의 차이와 같다. 후자가 훨씬 더 많은 교통량을 처리할 수 있는 것과 같은 원리다.
1.2 HBM 솔루션: 메모리 아키텍처의 패러다임 전환
HBM은 고성능 메모리의 전력 소모와 폼 팩터(form factor) 문제를 해결하기 위해 2008년경 AMD에서 처음 개념이 시작되었다.[7] 그 핵심 철학은 "넓고 느리게 만들어 더 빠르게(wide and slow makes it fast)"라는 말로 요약될 수 있다.[12] 즉, 동작 속도를 낮추는 대신 데이터가 오가는 통로를 극단적으로 넓혀 전체 데이터 전송량을 극대화하는 것이다. 이를 구현하기 위해 다음과 같은 혁신적인 기술이 도입되었다.
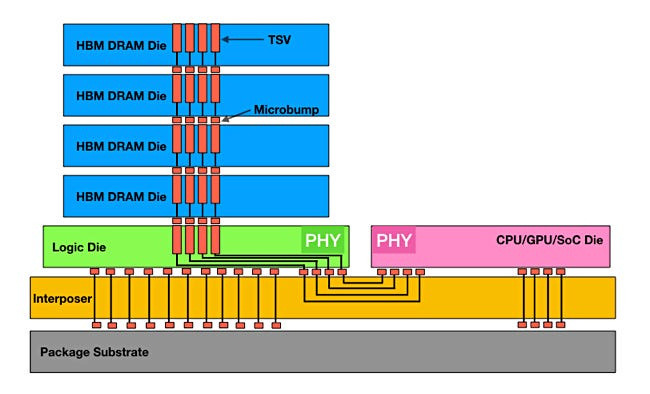
출처: Nomad Semi - 3D 적층과 실리콘 관통 전극(TSV): 여러 개의 D램 다이(die)를 평면이 아닌 수직으로 쌓아 올리는 3D 적층 기술을 통해, GDDR5 대비 90% 이상 물리적 면적을 획기적으로 줄였다.[3] 그리고 이 수직으로 쌓인 다이들 사이에 미세한 구멍을 뚫어 전극으로 연결하는 실리콘 관통 전극(Through-Silicon Via, TSV) 기술을 통해 칩 간의 전기적 경로를 극단적으로 단축시켰다.[3] TSV는 HBM을 가능하게 한 핵심 기반 기술이다.
- 실리콘 인터포저(Silicon Interposer): HBM의 수천 개에 달하는 넓은 버스는 기존의 PCB 기판으로는 감당할 수 없는 수준의 미세한 연결을 요구했다. 이를 해결하기 위해 GPU와 HBM 스택을 나란히 배치하는 정교한 중간 기판, 즉 실리콘 인터포저가 도입되었다.[2] 인터포저는 GPU와 HBM 사이의 물리적 거리를 최소화하여, HBM의 낮은 지연 시간과 높은 전력 효율을 실현하는 데 결정적인 역할을 한다.[3]
이러한 기술들의 조합은 결과적으로 기존 GDDR 대비 월등히 높은 대역폭, 낮은 전력 소비(GDDR5 대비 와트당 3배 이상의 대역폭), 짧은 지연 시간, 그리고 훨씬 작은 폼 팩터라는 혁신적인 이점을 제공했다.[3]
1.3 기술적 함의
HBM의 발명은 2D 메모리 패러다임의 물리적 한계에 대한 직접적인 응답이었다. 이는 대역폭 문제를 원초적인 '속도'로 해결하려던 접근법(GDDR)에서 '병렬성'(HBM)으로 해결하려는 근본적인 사상의 전환을 의미한다. GDDR의 발열, 전력, 공간이라는 제약을 극복하기 위해 엔지니어들은 기존 방식을 최적화하는 대신, 완전히 새로운 구조를 구상했다. 이는 엄청난 제조상의 난제(TSV, 인터포저)를 수반했지만, 그로 인해 얻을 수 있는 아키텍처적 이점은 그만한 투자를 감수할 가치가 있었다. 이는 기술적 도약이 종종 기존 기술의 개선이 아닌, 근본적인 가정에 대한 재고찰에서 비롯됨을 보여주는 대표적인 사례다.
표 1: GDDR 대 HBM - 근본적인 아키텍처 비교특징 GDDR
(예: GDDR6)HBM
(예: HBM3)근거 및 함의 아키텍처 2D 평면
(PCB 위 개별 칩)3D 적층
(실리콘 인터포저 위)HBM은 수직 적층으로 공간 효율성을 극대화하고 물리적 거리를 단축함.[4] 버스 폭 좁음
(예: -bit)매우 넓음
(예: -bit)HBM은 넓은 버스를 통해 낮은 클럭에서도 높은 대역폭을 달성함.[4] 클럭 속도 높음 낮음 HBM은 낮은 클럭으로 동작하여 전력 소비와 발열을 크게 줄임.[14] 전력 소비 높음 낮음 짧은 신호 경로와 낮은 클럭으로 인해 에너지 효율이 월등히 우수함.[4] 지연 시간 비교적 높음 낮음 GPU와의 물리적 근접성 덕분에 데이터 접근 시간이 짧음.[4] 물리적 면적 큼 작음 3D 적층 구조로 인해 시스템 설계에 필요한 공간이 획기적으로 감소함.[9] 제조 비용 낮음 높음 TSV, 인터포저 등 복잡한 공정으로 인해 제조 비용이 매우 높음.[4] 주요 사용처 소비자용/게이밍
그래픽카드HPC, 데이터센터,
AI 가속기비용 문제로 HBM은 고부가가치 시장에, GDDR은 대중 시장에 주로 사용됨.[4] 제2장 개척자들과 프로토타입: HBM으로 가는 길
HBM의 초기 개발 과정은 높은 위험과 불확실성 속에서 개척자들의 신념과 뚝심으로 점철된 여정이었다. 이 섹션에서는 AMD와 SK하이닉스의 결정적 역할, 그리고 시장의 냉담한 초기 반응을 극복하고 기술 표준으로 자리 잡기까지의 과정을 추적한다.
2.1 파트너십의 탄생: AMD의 비전과 SK하이닉스의 전문성
HBM 개발의 씨앗은 2008년경 AMD에서 뿌려졌다. 당시 AMD는 컴퓨터 메모리의 전력 소비와 폼 팩터 증가 문제를 해결할 새로운 기술을 모색하고 있었다.[7] GPU 설계 기업으로서 메모리 장벽의 고통을 누구보다 절실히 느끼고 있었기 때문이다. AMD는 3D 적층 메모리 분야에서 풍부한 경험을 보유한 SK하이닉스에 손을 내밀었다.[13] 마침 SK하이닉스는 2009년경부터 TSV 기술의 미래 파급력을 예견하고, 높은 비용과 불확실성에도 불구하고 관련 연구개발에 착수한 상태였다.[15]
두 기업은 2010년에서 2012년 사이에 TSV 기반의 HBM 제품 개발을 위한 협력을 공식화했다.[2] 일각에서는 닌텐도가 자사 콘솔의 그래픽 성능 강화를 위해 고대역폭 솔루션을 제안한 것이 개발의 촉매제가 되었다는 이야기도 전해진다.[2]2.2 '아오지 탄광'의 시절: 기술적, 내부적 난관 극복
HBM 프로젝트는 SK하이닉스 내부에서부터 거센 저항에 부딪혔다. 개발 비용이 막대하고 생산 공정이 까다로워 "개발비도 못 건질 것"이라는 등 채산성에 대한 부정적 의견이 팽배했다.[20] 당시 HBM 개발팀은 그 어려움과 고됨을 빗대어 '아오지 탄광'이라는 별명으로 불릴 정도였다.[20]
이러한 불확실한 미래에 대한 베팅을 가능하게 한 것은 SK그룹의 하이닉스 인수였다. 반도체 기술에 개인적인 관심을 보이며 투자를 주도한 최태원 회장의 지원 아래, 프로젝트는 단기적인 수익성 우려를 딛고 본격적인 궤도에 오를 수 있었다.[20] 이는 장기적인 기술 잠재력에 대한 전략적 투자가 얼마나 중요한지를 보여주는 사례다. 마침내 2013년, SK하이닉스는 세계 최초로 HBM 개발에 성공했다. 이 프로토타입은 당시 최고 사양의 GDDR5보다 4배 이상 빠르면서도 전력 소비는 40% 이상 낮추는 혁신적인 성능을 입증했다.[13]2.3 역사적인 데뷔: AMD 라데온 R9 Fury X
HBM 기술이 탑재된 최초의 상용 제품은 2015년 6월 24일에 출시된 AMD의 라데온 R9 Fury X 그래픽카드였다.[7] 이 제품은 SK하이닉스의 1세대 HBM(HBM1) 4GB를 탑재했으며, 4개의 4단(4-Hi) 스택이 4096-bit라는 압도적인 메모리 인터페이스를 통해 연결되어 초당 512GB/s 의 대역폭을 구현했다. 이는 이전 세대 플래그십 제품보다 60%나 향상된 수치였다.[22]
기술적으로는 경이로운 성과였지만, 시장의 반응은 미지근했다. 높은 가격에 비해 게이밍 환경에서의 성능 향상이 뚜렷하지 않았기 때문이다.[21] 결국 AMD는 후속 소비자용 그래픽카드에서 HBM 채택을 포기했고, HBM은 한동안 값비싼 틈새 기술로 전락할 위기에 처했다.[21]2.4 JEDEC의 역할: 독점 기술에서 산업 표준으로
HBM이 특정 기업의 전유물을 넘어 산업 전반에 확산되기 위해서는 표준화가 필수적이었다. 이에 AMD와 SK하이닉스는 반도체 산업 표준화 기구인 JEDEC(Joint Electron Device Engineering Council)에 HBM을 표준으로 제안했다.[13]
JEDEC은 2013년 10월, HBM을 JESD235 표준으로 공식 채택했다.[2] 이는 삼성전자와 같은 다른 메모리 제조사와 엔비디아 같은 시스템 설계 기업들이 상호 호환 가능한 제품을 개발할 수 있는 공통의 기반을 마련한 결정적인 사건이었다. 이후 HBM2, HBM2E, HBM3, HBM4 등 후속 세대 기술 역시 JEDEC을 통해 표준화가 이루어지며 HBM 생태계 확장의 발판이 되었다.[7]
HBM의 초기 역사는 기술이 시장의 요구보다 앞서나갔던 '기술 푸시(technology push)'의 전형적인 사례다. 이 기술이 생존하고 궁극적으로 성공할 수 있었던 것은 개척자들의 확고한 비전, 초기 시장의 무관심을 버텨낼 수 있었던 '인내 자본(patient capital)', 그리고 산업 표준화라는 보이지 않는 조력자의 역할 덕분이었다. 이는 파괴적 혁신이 단지 좋은 아이디어만으로는 불충분하며, 이를 뒷받침하는 비전, 자본, 그리고 산업 전반의 협력 체계가 필수적임을 시사한다.제3장 AI 쓰나미: 틈새 기술에서 산업의 핵심으로
이 섹션에서는 HBM을 고가의 호기심 대상에서 수조 달러 규모의 AI 산업에 없어서는 안 될 핵심 부품으로 탈바꿈시킨 시장의 변곡점을 분석한다.
3.1 변곡점: 거대 AI 모델의 부상
GPT나 스테이블 디퓨전과 같은 거대 언어 모델(LLM)과 생성형 AI의 등장은 메모리 대역폭에 대한 기존의 수요를 무의미하게 만들었다.[1] 이 모델들은 방대한 양의 데이터를 학습하고 추론하는 과정에서 메모리 대역폭을 끊임없이 요구하며, 이는 시스템 성능의 가장 큰 병목 지점이 되었다.[6]
바로 이 지점에서 HBM의 진가가 드러났다. 압도적인 대역폭, 높은 용량, 그리고 뛰어난 전력 효율이라는 HBM의 핵심 가치는 AI 시대가 요구하는 조건과 완벽하게 부합했다.[1] HBM은 AI 가속기, 슈퍼컴퓨터, 데이터센터의 필수 부품으로 자리매김했다.[3]
AMD가 게이밍 시장에서 HBM의 문을 열었다면, 그 잠재력을 AI 시장에서 폭발시킨 것은 엔비디아였다. 2016년, 엔비디아는 서버용 GPU인 '테슬라 P100'에 HBM2를 채택했다.[3] 이는 HBM을 시장의 변방에서 컴퓨팅의 중심으로 끌어올린 결정적 사건이었다. 이후 A100, H100을 거쳐 차세대 블랙웰(Blackwell)과 루빈(Rubin) 플랫폼에 이르기까지, 엔비디아의 모든 플래그십 AI 가속기는 HBM을 중심으로 설계되었고, 이는 HBM을 하이엔드 AI 하드웨어의 사실상 표준으로 만들었다.[13]3.2 경쟁의 서막: 3강 체제의 형성
AI가 촉발한 HBM 수요 폭증은 메모리 반도체 시장에 전례 없는 경쟁 구도를 형성했다.
- SK하이닉스 - 선점 효과와 기술 리더십: 초기 개발의 뚝심을 이어온 SK하이닉스는 시장의 선두 주자로 확고히 자리매김했다. 특히 엔비디아의 플래그십 H100에 HBM3를 독점 공급하며 2023년 HBM3 시장의 90% 이상을 장악했다.[21] 전체 HBM 시장에서도 50%가 넘는 점유율을 기록했다.[13]
- MR-MUF(Mass Reflow Molded Underfill) 패키징 기술이다. 이 기술은 칩을 쌓을 때 각 층 사이의 공간을 액체 형태의 보호재로 한 번에 채우고 굳히는 방식으로, 기존 방식보다 열 방출 특성과 생산성을 크게 개선하여 SK하이닉스에 강력한 경쟁 우위를 제공했다.[15]
- 삼성전자 - 잠자는 거인의 귀환: 2019년 시장성 부족을 이유로 HBM 전담팀을 해체했던 삼성전자는 AI 붐이 일자 뒤늦게 경쟁에 뛰어들었다.[28] 2022년 HBM3 '아이스볼트(Icebolt)'를 개발했지만 SK하이닉스보다 1년 늦었고, 이는 핵심 고객사인 엔비디아 H100 계약을 놓치는 결정적 원인이 되었다.28 이후 삼성은 HBM3E '샤인볼트(Shinebolt)'를 개발하고, 차세대 HBM4에서는 하이브리드 본딩(Hybrid Bonding)과 자사의 최첨단 4나노 파운드리 공정을 결합하는 과감한 전략으로 기술적 도약을 노리며 맹렬히 추격하고 있다.[28]
- 마이크론 테크놀로지 - 무서운 추격자: 2023년 약 9%의 점유율로 시작한 마이크론은 HBM3E 시장에서 매우 공격적인 행보를 보이고 있다.[13] 2024년 2월, 경쟁사들을 제치고 가장 먼저 HBM3E 양산을 발표하며 엔비디아 H200 GPU를 공략했다.[28] 초기 생산 안정화에 일부 어려움을 겪었음에도 불구하고 [28], 2025년 생산 물량을 조기 완판시키는 등 빠르게 입지를 넓히고 있으며, 자사의 전체 D램 시장 점유율에 걸맞은 수준(약 20-23%)까지 HBM 점유율을 끌어올리는 것을 목표로 하고 있다.[28]

출처: SK하이닉스 3.3 왕좌의 관문: 시장을 지배하는 엔비디아의 영향력
HBM 시장의 경쟁 구도는 공급자들 간의 경쟁만으로 결정되지 않는다. 2025년 전체 HBM 구매량의 73%를 차지할 것으로 예상되는 엔비디아의 존재는 시장의 판도를 좌우하는 절대적인 변수다.[13]
엔비디아의 품질 검증(qualification) 절차는 HBM 제조사들에게 '왕좌로 가는 마지막 관문'과 같다. 2024년 한 해 동안 삼성전자와 마이크론이 엔비디아의 HBM3E 퀄 테스트 통과에 어려움을 겪고 있다는 소식이 연이어 보도된 것은 이 과정이 얼마나 엄격한지를 보여준다.[13] 엔비디아의 테스트를 통과하는 것은 단순히 기술력을 인정받는 것을 넘어, 가장 수익성 높은 시장에 진입할 수 있는 '황금 티켓'을 얻는 것과 같다. 이로 인해 엔비디아는 가격 결정뿐만 아니라 HBM 생태계의 기술적 방향성에도 막대한 영향력을 행사하게 되었다.
이러한 시장 구조는 HBM 경쟁의 본질이 메모리 제조사 간의 단순한 스펙 경쟁이 아님을 시사한다. 오히려 이는 소수의 공급자가 단일 핵심 고객의 엄격한 기준을 통과하기 위해 벌이는 고도의 기술 및 전략 경쟁에 가깝다. 또한, SK하이닉스의 MR-MUF 사례에서 보듯, HBM의 기술 리더십은 이제 D램 다이 자체의 성능을 넘어, 전체 칩을 어떻게 효율적으로 쌓고 열을 관리하는가 하는 '첨단 패키징' 기술로 옮겨가고 있다. 메모리 기업은 더 이상 단순한 '다이' 제조사가 아니라, 복잡한 '시스템 통합' 기업이 되어야만 생존할 수 있는 시대가 된 것이다.제4장 세대별 심층 분석: HBM 기술의 진화
이 섹션에서는 HBM의 세대별 기술 사양을 상세히 분석하고, 차세대 표준인 HBM4가 가져올 기술적 변화와 경쟁 구도를 전망한다.
4.1 HBM 세대별 비교 분석 (HBM1 ~ HBM3E)
HBM 기술은 각 세대를 거치며 비약적인 성능 향상을 이루었다.
- HBM1 (2013년 개발 / 2015년 적용): HBM의 가능성을 입증한 첫 세대. 1024-bit 버스와 3D 적층 개념을 처음 도입했지만, 핀당 속도(1 Gbps)와 스택당 용량(4GB)은 비교적 평이한 수준이었다. AMD 라데온 R9 Fury X에 처음 탑재되었다.[13]
- HBM2 (2016년 표준화): 본격적인 성능 향상의 시작. 전송 속도(2.4 Gbps)와 스택당 용량(8GB)을 두 배로 늘려, 스택당 307 GB/s의 대역폭을 구현했다. 엔비디아가 테슬라 P100, V100에 채택하며 HBM이 데이터센터 시장에 진입하는 계기가 되었다.[13]
- HBM2E (2019년 표준화): HBM2의 확장(Extended) 버전. 속도를 3.6 Gbps까지 끌어올리고, 최대 12단(12-Hi) 적층을 지원하여 용량을 24GB까지 늘렸다. 생성형 AI 붐을 이끈 엔비디아 A100 가속기의 핵심 메모리로 활약했다.[13]
- HBM3 (2022년 표준화): 아키텍처의 큰 도약. 채널 수를 기존 8개에서 16개(각 64-bit)로 두 배 늘리고, 속도를 6.4 Gbps로 높여 스택당 대역폭을 819 GB/s 로 대폭 향상시켰다. 이 세대에서 SK하이닉스가 엔비디아 H100에 독점 공급하며 시장 지배력을 확립했다.[13]
- HBM3E (2024년 적용): 현재 최첨단 기술. 핀당 속도를 9.6 Gbps 이상으로 끌어올려 스택당 1.2 TB/s의 장벽을 돌파했다. 또한 더 높은 밀도의 다이를 사용하여 최대 48GB 용량을 지원한다. 엔비디아 H200, B200 가속기에 탑재되며 2024년 시장 경쟁의 중심에 있다.[13]
표 2: HBM 세대별 주요 사양 비교 [13]
사양 HBM HBM2 HBM2E HBM3 HBM3E HBM4 (예상) JEDEC 표준화 2013년 2016년 2019년 2022년 2024년 2025년 버스 폭 -bit -bit -bit -bit -bit -bit 최대 핀 속도 (Gbps) 최대 대역폭/스택
(GB/s)최대 적층 수 (단) 4 8 12 16 16 16 최대 용량/스택 (GB) 4 8 24 24 48 64 채널 아키텍처 8채널
x 128-bit8채널
x 128-bit8채널
x 128-bit16채널
x 64-bit16채널
x 64-bit32채널
x 64-bit주요 적용 제품 AMD R9 Fury X NVIDIA P100 NVIDIA A100 NVIDIA H100 NVIDIA
H200/B200NVIDIA Rubin 4.2 다음 격전지: HBM4와 그 너머
현재 표준화가 막바지에 이른 HBM4는 또 한 번의 구조적 변화를 예고하고 있다.[26]
- JEDEC HBM4 표준의 핵심:
- -bit 인터페이스: 버스 폭이 기존의 두 배인 -bit로 확장된다. 이는 대역폭을 한 단계 더 끌어올리기 위한 핵심적인 아키텍처 변경이다.[13]
- 더 높은 적층: 최대 16단(16-Hi) 적층을 공식 지원하며, 이를 수용하기 위해 패키지 최대 높이 기준이 HBM3E의 720um에서 775um로 소폭 완화되었다.[26]
- 고밀도 다이: 32Gb와 같은 고밀도 D램 다이를 사용하여 스택당 최대 64GB 의 용량을 구현할 수 있게 된다.[26]
- 패키징 전쟁: 하이브리드 본딩 대 첨단 MR-MUF: 인터페이스가 넓어지고 적층이 높아지면서 다이 사이를 연결하는 범프(bump)가 성능의 발목을 잡는 새로운 병목으로 떠올랐다. 이를 해결하기 위한 두 가지 접근법이 충돌하고 있다.
- 하이브리드 본딩(Hybrid Bonding): 솔더볼(solder ball) 같은 범프 없이 구리와 구리를 직접 접합하는 첨단 기술이다. 열 및 전기적 특성이 우수하지만, 기존 기술보다 훨씬 비싸고 공정이 복잡하다.[34] 삼성전자가 HBM4에 이 기술을 적용하며 승부수를 띄우고 있다.[34]
- 첨단 MR-MUF: SK하이닉스는 자사의 성공 방정식인 MUF 기술을 더욱 발전시켜, 막대한 설비 투자가 필요한 하이브리드 본딩과 대등한 성능을 구현하고자 한다. 동시에 하이브리드 본딩 기술도 예비책으로 개발하며 양면 전략을 구사하고 있다.[34]
- 커스텀 로직 다이와 파운드리 협력의 부상: HBM4의 베이스 다이(Base Die)는 단순한 버퍼 역할을 넘어, 고객의 요구에 맞춰 특정 기능을 추가할 수 있는 복잡한 로직 칩으로 진화하고 있다.[15] 이를 위해서는 3나노, 4나노와 같은 최첨단 로직 공정이 필수적이다. 메모리 제조사는 이러한 공정을 보유하고 있지 않기 때문에, TSMC와 같은 로직 파운드리와의 전략적 파트너십이 필수가 되었다.[15] SK하이닉스와 마이크론은 TSMC와 긴밀히 협력하는 반면, 삼성전자는 자사의 파운드리 사업부를 활용하는 '원팀' 전략으로 대응하며 새로운 경쟁 구도를 만들고 있다.[36]
HBM4의 개발은 HBM이 더 이상 단순한 '메모리' 제품이 아니라, 복잡한 '시스템 인 패키지(System-in-Package, SiP)' 제품임을 명확히 보여준다. HBM4 시대의 경쟁 우위는 D램 기술력뿐만 아니라, 첨단 패키징 기술, 로직 설계 역량, 그리고 전략적 파운드리 파트너십을 얼마나 잘 조율하느냐에 따라 결정될 것이다. 이는 삼성의 '수직 계열화' 모델과 SK하이닉스·마이크론의 '개방형 협력' 모델 간의 대결이기도 하다.
제5장 전략 분석 및 미래 전망
본 장에서는 앞서 다룬 역사적, 시장적, 기술적 분석을 종합하여 HBM의 산업적 영향과 미래 궤적에 대한 거시적 관점을 제시한다.
5.1 AI 혁명의 엔진, HBM
HBM은 AI 기술과 상호 발전하는 공생 관계를 형성했다. AI 모델이 더 많은 대역폭을 요구하면 HBM 기술이 발전하고, 새롭게 발전한 HBM은 더 강력한 AI 모델의 등장을 가능하게 하는 선순환 구조가 만들어진 것이다.
- 사례 연구: 엔비디아의 AI 가속기: 엔비디아의 제품 라인업은 HBM의 발전사와 궤를 같이한다. 2016년 테슬라 P100에 HBM2가 탑재된 이래로 V100, A100(HBM2E), H100(HBM3)을 거쳐 H200/B200(HBM3E), 그리고 차세대 루빈(HBM4)에 이르기까지, 각 세대의 HBM은 AI 가속기의 성능을 한 단계씩 끌어올리는 결정적 역할을 했다.[13]
- 광범위한 생태계: HBM의 영향력은 엔비디아에 국한되지 않는다. AMD의 인스팅트(Instinct) MI300X/MI350, 구글의 TPU(Tensor Processing Unit), 그리고 주요 클라우드 서비스 제공업체들이 자체 개발하는 AI 칩에 이르기까지, HBM은 고성능 컴퓨팅 생태계 전반의 표준으로 자리 잡았다.[3]
표 3: 주요 AI 가속기와 HBM 통합 사례 [3]
연도 가속기 (제조사) 사용된 HBM 세대 HBM 구성 (예) 총 대역폭
(TB/s)의의 2016 Tesla P100 (NVIDIA) HBM2 4 x 4-Hi 스택 HBM의 데이터센터 시장 진입 2017 Tesla V100 (NVIDIA) HBM2 4 x 4-Hi 스택 딥러닝 가속의 표준화 2020 A100 (NVIDIA) HBM2E 5~6 x 8-Hi 스택 생성형 AI 붐의 기반 마련 2022 H100 (NVIDIA) HBM3 5 x 8-Hi 스택 LLM 훈련 성능의 비약적 향상 2024 Instinct MI300X (AMD) HBM3 8 x 8-Hi 스택 AI 시장에서의 본격적인 경쟁 2024 H200 (NVIDIA) HBM3E 6 x 8-Hi 스택 추론 성능 극대화 2024 B200 (NVIDIA) HBM3E 8 x 8-Hi 스택 차세대 AI 모델을 위한 대역폭 2026(예상) Rubin (NVIDIA) HBM4 8 x 12-Hi 스택 > 10 2048-bit 인터페이스 시대 개막 5.2 지속적인 과제와 해결 노력
HBM은 혁신적인 기술이지만, 여전히 극복해야 할 과제들을 안고 있다.
- 비용과 제조 복잡성: TSV, 인터포저, 3D 패키징 등 복잡한 공정으로 인해 HBM은 GDDR보다 월등히 비싸다.[3] 이 높은 비용은 HBM의 적용 범위를 당분간 AI, HPC와 같은 고부가가치 시장에 한정시키는 주요 요인이다.
- 열 관리: 다이를 수직으로 쌓는 구조는 엄청난 열 밀도를 발생시킨다. 효과적인 열 방출은 성능 저하(throttling)를 막기 위한 핵심 과제이며, MR-MUF나 하이브리드 본딩과 같은 첨단 패키징 및 냉각 기술의 발전을 요구한다.[18]
- 수율과 공급망: 복잡한 제조 공정은 필연적으로 낮은 수율로 이어진다. 스택의 일부에 결함이 생기면 전체 스택을 폐기해야 하므로 대량 생산이 어렵고, 이는 공급망을 불안정하게 만드는 요인이 된다.[16] SK하이닉스가 HBM3E 수율 80%를 자신 있게 공개한 것은 그만큼 이 문제가 중요하고 해결하기 어렵다는 방증이다.[28]
5.3 최종 분석: HBM의 유산과 미래
HBM의 역사는 미래의 기술적 수요를 정확히 예측하고 장기적인 관점에서 투자한 고위험 R&D 전략이 어떻게 성공하는지를 보여주는 교과서적인 사례다. 이는 '인내 자본'과 비전을 가진 리더십의 중요성을 증명한다.
HBM4와 그 이후 세대를 둘러싼 경쟁은 세 가지 전선에서 펼쳐질 것이다. 첫째는 패키징 기술 (첨단 MR-MUF 대 하이브리드 본딩)의 주도권 싸움이다. 둘째는 파운드리 전략 (내부 역량 활용 대 외부 파트너십)의 효율성 경쟁이다. 마지막으로 셋째는 엔비디아와 같은 '킹메이커'의 선택을 받기 위한 생태계 관리 능력이다.
결론적으로, HBM은 더 이상 단순한 부품이 아니라 현대 컴퓨팅을 지탱하는 근본적인 기둥이다. HBM의 발전 궤적은 향후 10년간 인공지능, 슈퍼컴퓨팅, 데이터 과학의 발전 속도를 규정할 것이다. HBM 경쟁의 승자는 단순히 메모리 시장의 리더를 넘어, 미래 디지털 경제를 움직이는 핵심 동력원의 공급자로서 자리매김하게 될 것이다.
Works cited
- [반도Chat Ep.3] 초거대 AI 시대를 이끌 메모리 반도체 'HBM', https://news.samsungsemiconductor.com/kr/%EB%B0%98%EB%8F%84chat-ep-3-%EC%B4%88%EA%B1%B0%EB%8C%80-ai-%EC%8B%9C%EB%8C%80%EB%A5%BC-%EC%9D%B4%EB%81%8C-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EB%B0%98%EB%8F%84%EC%B2%B4-hbm/
- 고대역폭 메모리(HBM)의 탄생과 발전: GDDR을 뛰어넘는 메모리 혁신, https://sciencetech.tistory.com/entry/%EA%B3%A0%EB%8C%80%EC%97%AD%ED%8F%AD-%EB%A9%94%EB%AA%A8%EB%A6%ACHBM%EC%9D%98-%ED%83%84%EC%83%9D%EA%B3%BC-%EB%B0%9C%EC%A0%84-GDDR%EC%9D%84-%EB%9B%B0%EC%96%B4%EB%84%98%EB%8A%94-%EB%A9%94%EB%AA%A8%EB%A6%AC-%ED%98%81%EC%8B%A0
- HBM (High Bandwidth Memory)이란 무엇인가? - 쭌3이의 Blog - 티스토리, https://june3lee.tistory.com/entry/HBM-High-Bandwidth-Memory%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
- What is the difference between HBM and GDDR memory in a GPU? - Massed Compute, https://massedcompute.com/faq-answers/?question=What%20is%20the%20difference%20between%20HBM%20and%20GDDR%20memory%20in%20a%20GPU?
- How does HBM\'s stacked architecture compare to GDDR\'s traditional memory design?, https://massedcompute.com/faq-answers/?question=How%20does%20HBM%27s%20stacked%20architecture%20compare%20to%20GDDR%27s%20traditional%20memory%20design?
- GDDR6 vs HBM Memory | SabrePC Blog, https://www.sabrepc.com/blog/computer-hardware/difference-between-gddr-memory-vs-hbm-memory
- 고대역 메모리 - 위키백과, 우리 모두의 백과사전, https://ko.wikipedia.org/wiki/%EA%B3%A0%EB%8C%80%EC%97%AD_%EB%A9%94%EB%AA%A8%EB%A6%AC
- What are the power consumption differences between HBM and GDDR memory in AI and machine learning applications? - Massed Compute, https://massedcompute.com/faq-answers/?question=What%20are%20the%20power%20consumption%20differences%20between%20HBM%20and%20GDDR%20memory%20in%20AI%20and%20machine%20learning%20applications?
- The Rise of High Bandwidth Memory (HBM): Revolutionizing GPU Performance, https://www.buysellram.com/blog/the-rise-of-high-bandwidth-memory-hbm-revolutionizing-gpu-performance/
- [넥스트 HBM]③그래픽 넘어 AI로 나아가는 'GDDR' - 비즈워치, http://news.bizwatch.co.kr/article/industry/2024/08/07/0024
- [칩톡]엔비디아 GPU에 장착될 'GDDR7'는 한국산일까 미국산일까 - 아시아경제, https://cm.asiae.co.kr/article/2024080116232961931
- High Bandwidth Memory: Wide & Slow Makes It Fast - The AMD Radeon R9 Fury X Review: Aiming For the Top - AnandTech, https://www.anandtech.com/show/9390/the-amd-radeon-r9-fury-x-review/6
- HBM - 나무위키, https://namu.wiki/w/HBM
- HBM vs. GDDR: Which GPU Memory Type is Right for You? - Unibetter, https://en.unibetter-ic.com/hbm-vs-gddr/
- [ONE TEAM SPIRIT] EP.2 세계 최초인데 흑역사였던 SK하이닉스 ..., https://news.skhynix.co.kr/one-team-spirit-ep2/
- JEDEC 스펙으로 살펴보는 HBM3 - 골수공돌이의 탐구실, https://www.donghyun53.net/jedec-%EC%8A%A4%ED%8E%99%EC%9C%BC%EB%A1%9C-%EC%82%B4%ED%8E%B4%EB%B3%B4%EB%8A%94-hbm3/
- What is High-Bandwidth Memory (HBM)? HBM vs. GDDR - YouTube, https://www.youtube.com/watch?v=5hqhhLH3nZ8
- High Bandwidth Memory: Concepts, Architecture, and Applications - Wevolver, https://www.wevolver.com/article/high-bandwidth-memory
- The Critical Role of High Bandwidth Memory (HBM) in Modern GPUs - ByteBridge - Medium, https://bytebridge.medium.com/the-critical-role-of-high-bandwidth-memory-hbm-in-modern-gpus-63b0164f29bc
- 하이닉스 황금알 HBM…그 뒤엔 '10년 뚝심' 있었다 - 중앙일보, https://www.joongang.co.kr/article/25202718
- HBM 전쟁 총성은 울렸다…삼성, 판 뒤집기 vs SK, 1등 굳히기 - 한국경제, https://www.hankyung.com/article/2024050690841
- AMD Radeon R9 FURY X Specs | TechPowerUp GPU Database, https://www.techpowerup.com/gpu-specs/radeon-r9-fury-x.c2677
- AMD Radeon R9 Fury X Review - PCMag, https://www.pcmag.com/reviews/amd-radeon-r9-fury-x
- AMD Radeon R9 Fury X 4GB Review - Tom's Hardware, https://www.tomshardware.com/reviews/amd-radeon-r9-fury-x,4196.html
- HBM DRAM - 고대역폭 메모리 Architecture // HBM2, HBM3, TSV, 3D 스택 DRAM - 홍야월드 : 반도체 Trends - 티스토리, https://hongya-world.tistory.com/entry/HBM-DRAM-%EA%B3%A0%EB%8C%80%EC%97%AD%ED%8F%AD-%EB%A9%94%EB%AA%A8%EB%A6%AC-Architecture-HBM2-HBM3-TSV-3D-%EC%8A%A4%ED%83%9D-DRAM
- [칩톡]차세대 'HBM4' 표준화 코앞…삼성전자 vs TSMC·SK하이닉스 연합군 승자는?, https://cm.asiae.co.kr/article/2024071909415038275
- High Bandwidth Memory - Wikipedia, https://en.wikipedia.org/wiki/High_Bandwidth_Memory
- HBM의 개요 및 현재 기술력 : sk하이닉스의 독주와 삼성전자의 도전, https://note2629.tistory.com/entry/HBM%EC%9D%98-%EA%B0%9C%EC%9A%94-%EC%97%AD%EC%82%AC
- HBM이 뭐길래…삼성전자·SK하이닉스, 주도권 경쟁 치열 - 연합뉴스, https://www.yna.co.kr/view/AKR20230721145500003
- HBM 분야에서 글로벌 상위 3대 반도체 AI 메모리 선도 기업이 신뢰하는 솔루션 - Advantech, https://www.advantech.com/ko-kr/resources/case-study/copy-of-trusted-by-global-top-3-semiconductor-ai-memory-leader-for-hbm
- 일반 컴퓨터에는 없는 초고성능 메모리, 'HBM' 이모저모 - 다나와 DPG, https://dpg.danawa.com/mobile/news/view?boardSeq=64&listSeq=5369968
- 딥시크가 HBM 시장도 흔든다…SK하이닉스·삼성전자 '촉각' [황정수의 반도체 이슈 짚어보기], https://www.hankyung.com/article/202501282081i
- [DBR]돌파형 혁신, SK하이닉스 HBM 사업 도약의 비결 - 동아일보, https://www.donga.com/news/Economy/article/all/20240714/125906744/2
- Samsung to adopt hybrid bonding for HBM4 memory - Tom's Hardware, https://www.tomshardware.com/pc-components/dram/samsung-to-adopt-hybrid-bonding-for-hbm4-memory
- Samsung Prepares Hybrid Bonding for HBM4 to Slash Thermals and Boost Bandwidth, https://www.techpowerup.com/forums/threads/samsung-prepares-hybrid-bonding-for-hbm4-to-slash-thermals-and-boost-bandwidth.336748/
- Samsung to mass-produce HBM4 on 4 nm foundry process | SemiWiki, https://semiwiki.com/forum/threads/samsung-to-mass-produce-hbm4-on-4-nm-foundry-process.20623/
- Skyrocketing HBM Will Push Micron Through $45 Billion And Beyond - The Next Platform, https://www.nextplatform.com/2025/06/30/skyrocketing-hbm-will-push-micron-through-10-billion-and-beyond/
- Micron posts record Q3 as HBM-fueled DRAM sales surge - Blocks and Files, https://blocksandfiles.com/2025/06/26/micron-q3-2025/
- What is High Bandwidth Memory 3 (HBM3)? - Synopsys, https://www.synopsys.com/glossary/what-is-high-bandwitdth-memory-3.html
- HBM3E | Micron Technology Inc., https://www.micron.com/products/memory/hbm/hbm3e
- HBM3E: Everything You Need to Know - Rambus, https://www.rambus.com/blogs/hbm3-everything-you-need-to-know/
- 차세대 HBM4 표준, 올해말 공식화될 듯…삼성·SK 개발 '속도전', https://www.hankooki.com/news/articleView.html?idxno=143225
- [News] Following JEDEC's HBM4 Standard: What's Next for SK hynix, Samsung, and Micron? - TrendForce, https://www.trendforce.com/news/2025/04/28/news-following-jedecs-hbm4-standard-whats-next-for-sk-hynix-samsung-and-micron/
- 삼성전자 "커스텀 HBM, HBM4 양산 시점에 상용화" - 디일렉, https://www.thelec.kr/news/articleView.html?idxno=29002
- SK Hynix Shifts to 3nm Process for Its HBM4 Base Die in 2025 | TechPowerUp, https://www.techpowerup.com/329489/sk-hynix-shifts-to-3nm-process-for-its-hbm4-base-die-in-2025
- "삼성 HBM3E 적용"…AMD 발표에 시장의 눈은 엔비디아로 - KB의 생각, https://kbthink.com/news-list/view.html?newsId=20250613192428758
- Choosing The Correct High-Bandwidth Memory - Semiconductor Engineering, https://semiengineering.com/choosing-the-correct-high-bandwidth-memory/
- HBM의 단점 비싼 가격과 내구성 문제, https://note2629.tistory.com/entry/HBM
반응형'TechStock&Review > SemiConduct' 카테고리의 다른 글
칼 자이스(Carl Zeiss)의 역사와 EUV 리소그래피 광학 (25.9.3) (0) 2025.09.03 메모리 장벽의 확장: HBM의 부상과 로드맵 (25.8.14) (12) 2025.08.14 NVIDIA 텐서 코어 진화 - Volta 에서 Blackwell 까지 (25.6.26) (5) 2025.06.26 화웨이의 야심작, Ascend 910C 칩 & CloudMatrix384 시스템의 흥미로운점 (2025.6.21) (4) 2025.06.21 중국의 반도체 굴기 - EUV 장비, 독자 개발의 현주소와 미래 (25.6.15) (0) 2025.06.15