-
NVIDIA 텐서 코어 진화 - Volta 에서 Blackwell 까지 (25.6.26)TechStock&Review/SemiConduct 2025. 6. 26. 21:48
작년 말 AI 확장 법칙(AI Scaling Laws) 기사 에서 , 여러 AI 확장 법칙들이 어떻게 AI 산업을 지속적으로 발전시켜 무어의 법칙을 뛰어넘는 모델 성능 향상과 그에 상응하는 단위 토큰 비용의 빠른 감소를 가능하게 했는지에 대해 논의했습니다. 이러한 확장 법칙은 학습 및 추론 최적화와 혁신에 의해 주도되지만, 무어의 법칙을 뛰어넘는 컴퓨팅 성능의 발전 또한 중요한 역할을 했습니다.
이러한 맥락에서, AI 스케일링 법칙(AI Scaling Laws) 기사에서는 수십 년간 이어져 온 컴퓨팅 스케일링에 대한 논쟁을 재조명하며, 2000년대 후반 데나드 스케일링(Dennard Scaling)의 종말과 2010년대 후반 트랜지스터당 비용 감소라는 고전적인 무어의 법칙의 종말을 다뤘습니다. 그럼에도 불구하고 컴퓨팅 성능은 빠른 속도로 계속 향상되어 왔으며, 고급 패키징 , 3D 스태킹 , 새로운 트랜지스터 유형 , GPU와 같은 특수 아키텍처와 같은 다른 기술들이 그 뒤를 이어 발전해 왔습니다.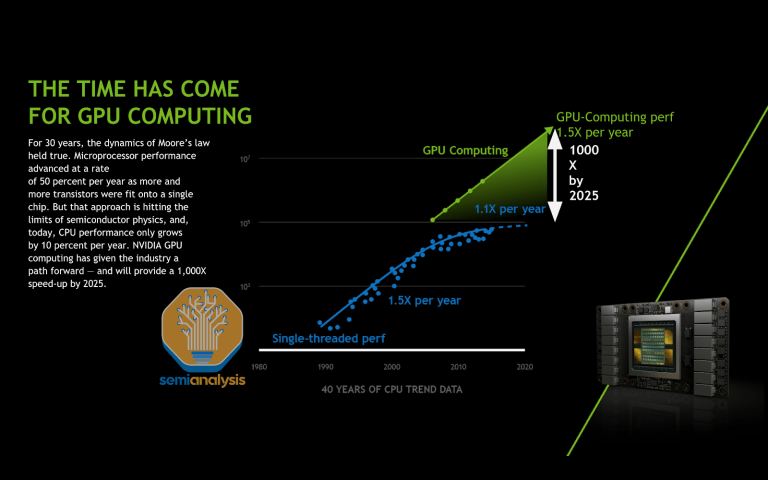
출처: 엔비디아
AI와 딥러닝 분야에서 GPU 컴퓨팅 성능은 무어의 법칙보다 빠른 속도로 발전해 왔으며, 매년 놀라운 " 황의 법칙 " 성능 향상을 달성해 왔습니다. 이러한 향상의 핵심 기술은 바로 텐서 코어입니다.
텐서 코어는 현대 AI와 머신러닝의 기반이 되는 핵심 요소임은 분명하지만, 이 분야의 많은 숙련된 실무자들조차도 텐서 코어에 대해 제대로 이해하지 못하고 있습니다. GPU 아키텍처와 이 아키텍처에서 실행되는 프로그래밍 모델의 급속한 발전으로 인해 머신러닝 연구자와 과학자들은 텐서 코어의 최신 변경 사항을 따라가고 그 변화가 가져오는 의미를 파악하기가 점점 더 어려워지고 있습니다.
출처: SemiAnalysis
이 보고서에서는 주요 데이터센터 GPU의 핵심 기능을 소개하고, 먼저 성능 엔지니어링의 중요한 기본 원칙을 설명합니다. 그런 다음 엔비디아 텐서 코어 아키텍처와 프로그래밍 모델의 진화를 추적하고 이러한 진화의 배경이 된 동기를 조명합니다. 최종 목표는 엔비디아 GPU 아키텍처를 이해하고 아키텍처 진화에 대한 직관적인 통찰력을 제공하는 것입니다. 각 아키텍처를 설명한 후에야 블랙웰 텐서 코어의 장점과 새로운 메모리 계층 구조를 설명할 수 있습니다.
이 글의 많은 설명과 논의를 이해하기 위해서는 컴퓨터 아키텍처에 대한 탄탄한 이해가 필수적임을 강조하는 것이 중요합니다. 이 글에서는 GPU 아키텍처의 기본 개념을 설명하기보다는 CUDA 프로그래밍에 대한 간략한 내용을 통해 복습할 수 있도록 하겠습니다. 대신, Tensor Core에 대한 최신 지식을 바탕으로, 현재 널리 알려지지 않은 지식을 상세한 설명을 통해 접근 가능하고 체계적인 통찰력으로 문서화함으로써 이 최첨단 기술에 대한 이해를 넓혀갈 것입니다.Performance First Principles - 성능 우선의 법칙
Amdahl’s Law - 암달의 법칙고정된 문제 크기에 대해 Amdahl’s Law은 더 많은 컴퓨팅 리소스를 사용하여 병렬화함으로써 얻을 수 있는 최대 속도 향상을 명시합니다. 구체적으로, 컴퓨팅 리소스를 확장하면 병렬 부분의 실행 시간만 단축되므로 성능 향상은 직렬 부분의 실행 시간에 의해 제한됩니다. 이를 정량화하기 위해 최대 성능 향상은 다음과 같습니다.

여기서 S는 병렬 작업 실행 시간이고, p는 병렬화 가능한 작업의 속도 향상입니다. 병렬 부분이 완벽하게 병렬화된 이상적인 환경에서는, 속도 향상 p는 처리 장치 수가 될 수 있습니다.
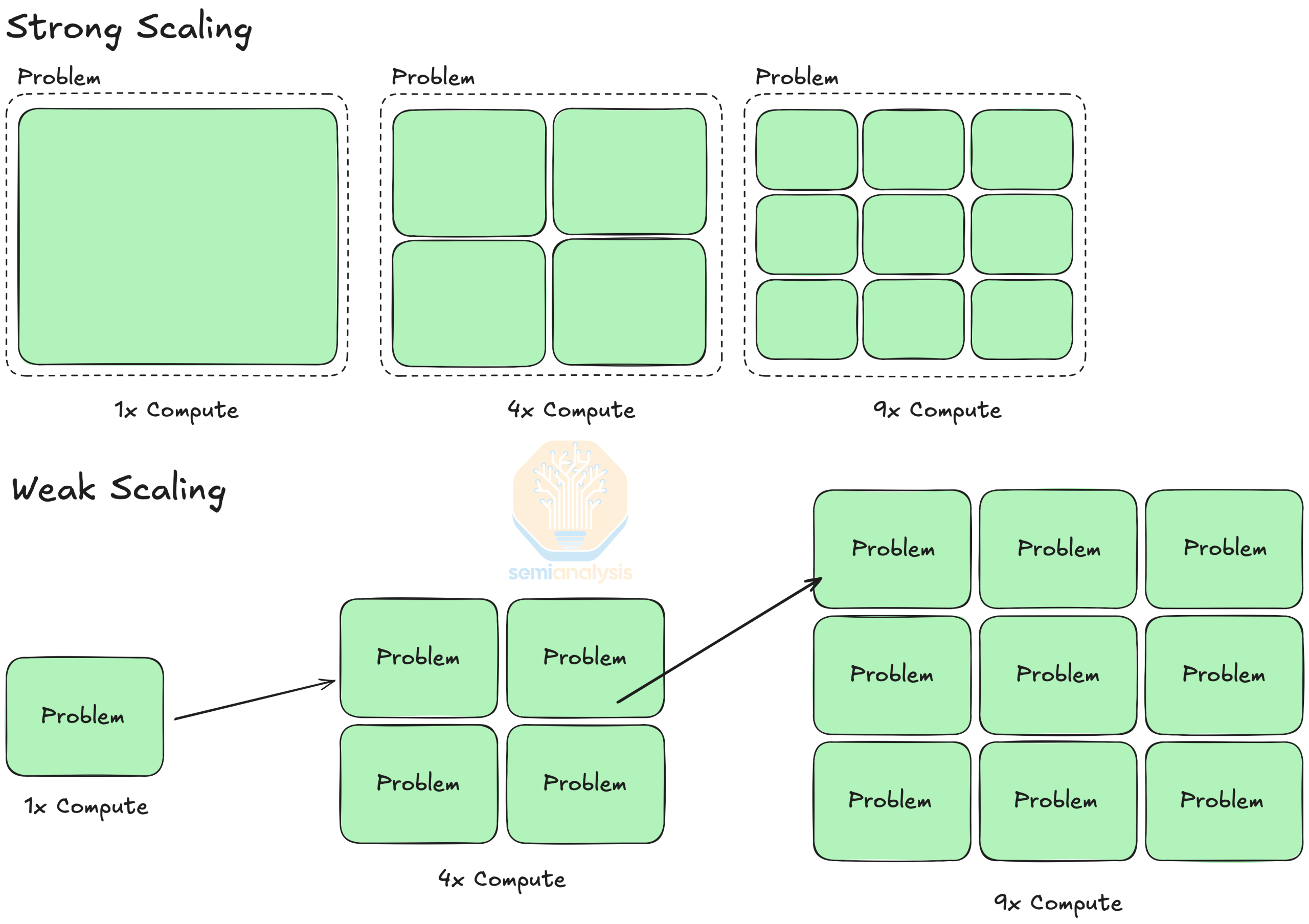
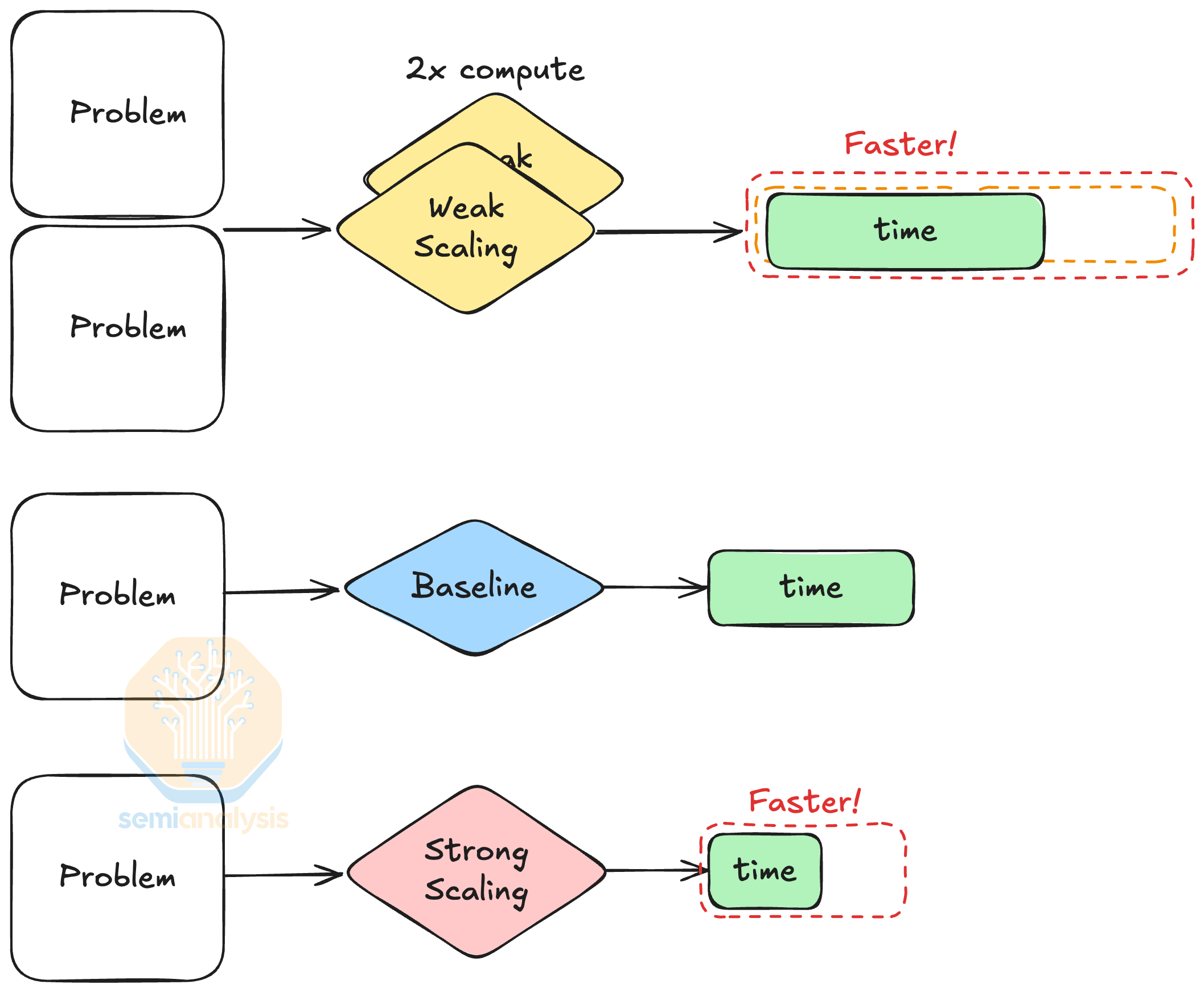
Strong and Weak Scaling - 강형 스케일링과 약형 스케일링
Strong Scaling과 Weak Scaling은 다양한 문제 설정에 대한 컴퓨팅 리소스 확장의 성능 향상을 설명합니다. Strong Scaling은 고정된 크기의 문제를 해결하기 위해 컴퓨팅 리소스를 확장하는 것을 의미하며, Amdahl’s Law은 Strong Scaling의 속도 향상을 정량화합니다. 반면, Weak Scaling은 일정한 시간에 더 큰 문제를 해결하기 위해 컴퓨팅 리소스를 확장하는 것을 의미합니다. 예를 들어, 4배 더 큰 이미지를 4배 더 많은 컴퓨팅 리소스를 사용하여 동시에 처리하는 것입니다. 더 자세한 설명은 이 블로그 게시물을 참조.https://acenet-arc.github.io/ACENET_Summer_School_General/05-performance/index.html
Performance and Scalability – ACENET Summer School - General
Solution Remember that Gustafson’s Law models the case where the amount of work grows in proportion to the number of processors. In our case, the problem size is the number of pixels and we use a thread for each processor. So to properly evaluate weak sc
acenet-arc.github.io
출처: SemiAnalysis
Strong Scaling과 Weak Scaling은 문제 크기에 따라 다른 성능 향상을 가져옵니다. Strong Scaling은 모든 문제 크기에 대해 속도 향상을 제공하는 반면, Weak Scaling은 더 큰 문제를 해결하기 위해 더 많은 컴퓨팅을 사용할 때만 성능 향상을 보장합니다.
출처: SemiAnalysis
Data Movement is the Cardinal Sin - 데이터 이동은 중대한 죄악이다.
데이터 이동은 런타임과 확장성 측면에서 계산은 저렴하지만 데이터 이동은 비용이 많이 들기 때문에 골칫거리입니다. 최신 DRAM 셀은 수십 나노초 단위로 작동하는 반면 트랜지스터는 나노초 미만의 속도로 스위칭하기 때문에 데이터 이동 속도가 근본적으로 더 느립니다. 확장성과 관련하여, 2000년대 이후 계산 속도 향상은 둔화된 반면 메모리 속도는 더 느리게 향상되어 메모리 장벽이 형성되었습니다 .
https://semianalysis.com/2024/09/03/the-memory-wall/
The Memory Wall: Past, Present, and Future of DRAM
Winners & Losers in the 3D DRAM Revolution The world increasingly questions the death of Moore’s Law, but the tragedy is that it already died over a decade ago with 0 fanfare or headlines. The …
semianalysis.com
https://en.wikipedia.org/wiki/Random-access_memory#Memory_wall
Random-access memory - Wikipedia
From Wikipedia, the free encyclopedia Form of computer data storage Example of writable volatile random-access memory: Synchronous dynamic RAM modules, primarily used as main memory in personal computers, workstations, and servers. A 64 bit memory chip die
en.wikipedia.org
Tensor Core Architecture Evolution - 텐서 코어 아키텍처 진화
Tensor Core Generation Overview - 텐서 코어 생성 개요
이 섹션에서는 텐서 코어를 사용하는 주요 엔비디아 GPU 아키텍처인 테슬라 V100 GPU, A100 텐서 코어 GPU, H100 텐서 코어 GPU, 그리고 블랙웰 GPU를 소개합니다. 또한 CUDA 프로그래밍 모델을 다시 살펴보기 위해 텐서 코어 이전 섹션도 포함했습니다. 텐서 코어를 이해하는 데 도움이 되는 주요 기능과 변경 사항을 간략하게 살펴보겠습니다. 자세한 내용은 각 하위 섹션에 링크를 제공하는 다른 자료에서 확인할 수 있습니다.
Pre-Tensor Core 프리-텐서 코어
PTX Programming Model
Parallel Thread Execution(PTX)은 GPU 세대를 추상화하는 가상 명령어 집합입니다. PTX 프로그램은 GPU의 하드웨어 실행 장치(CUDA 코어)에서 실행되는 다수의 GPU 스레드로 실행되는 커널 함수를 설명합니다. 스레드는 그리드 형태로 구성되며, 그리드는 cooperative thread arrays( CTA )로 구성됩니다. PTX 스레드는 서로 다른 특성을 가진 메모리 저장 영역인 여러 상태 공간의 데이터에 액세스할 수 있습니다. 구체적으로, 스레드는 스레드별 레지스터 를 가지고 있으며 , CTA 내의 스레드는 공유 메모리를 가지고 있으며 , 모든 스레드는 전역 메모리 에 액세스할 수 있습니다. 자세한 내용은 CUDA 설명서의 이 섹션을 참조하십시오.1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com

출처: SemiAnalysis
PTX Machine ModelGPU 아키텍처는 Streaming Multiprocessors( SM ) 배열을 중심으로 구축됩니다 . SM은 스칼라 처리 코어, 멀티스레드 명령어 유닛, 그리고 온칩 공유 메모리로 구성됩니다. SM은 각 스레드를 스칼라 처리 코어(CUDA 코어라고도 함)에 매핑하고, 멀티스레드 명령어 유닛은 워프(warp) 라고 하는 32개의 병렬 스레드 그룹으로 스레드를 관리합니다 .
명령어 실행 시점에 명령어 유닛은 워프를 선택하고 해당 워프의 스레드에 명령어를 실행합니다. 이러한 실행 방식을 single-instruction, multiple threads ( SIMT )라고 합니다. 단일 명령어, 다중 데이터 single-instruction, multiple data ( SIMD )와 유사하게, SIMT는 단일 명령어로 여러 처리 요소를 제어하지만, SIMD와 달리 벡터 폭 대신 단일 스레드 동작을 지정합니다. 자세한 내용은 CUDA 설명서의 이 섹션을 참조1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
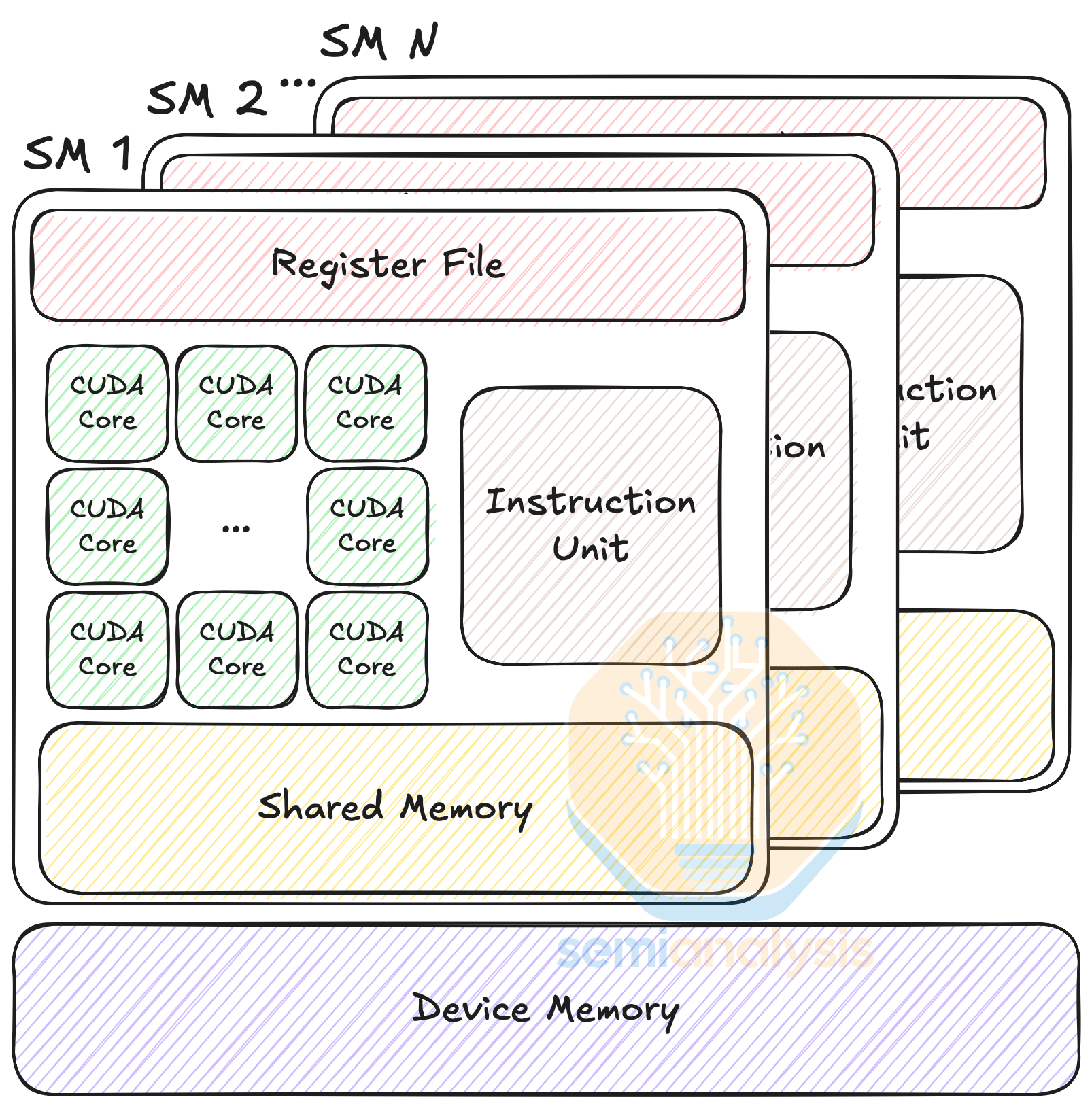
PTX Machine model. Source: SemiAnalysis
Streaming Assembler
Streaming Assembler(SASS)는 PTX가 가상화하는 아키텍처별 명령어 집합입니다. 자세한 내용은 CUDA 바이너리 유틸리티 문서를 참조하십시오 . 안타깝게도 SASS는 NVIDIA가 경쟁사에게 아키텍처 ISA 세부 정보를 숨기고 있기 때문에 제대로 문서화되어 있지 않습니다.
https://docs.nvidia.com/cuda/cuda-binary-utilities/index.html#instruction-set-reference
1. Overview — cuda-binary-utilities 12.9 documentation
--binary -b When this option is specified, the input file is assumed to contain a raw instruction binary, that is, a sequence of binary instruction encodings as they occur in instruction memory. The value of this option must be the asserted architecture of
docs.nvidia.com
Volta
Why NVIDIA Added Tensor Cores - NVIDIA가 텐서 코어를 추가한 이유
딥 러닝이 더욱 두드러지면서 업계에서는 ML 워크로드에 하드웨어 가속이 필요하다는 것을 알게 되었습니다. 2015년 초, Google은 내부 ML 워크로드를 가속화하기 위해 TPUv1을 배포했고, 2017년에 Nvidia는 행렬 수학을 위한 전용 하드웨어를 출시했습니다. GPU는 간단한 하드웨어 파이프라인으로 인해 명령어를 실행할 때 소량의 에너지(~30pJ)를 소모하지만, 간단한 부동 소수점 연산은 HFMA 단 1.5pJ로 더 적은 에너지를 소모합니다. 이로 인해 부동 소수점 연산 자체에 비해 명령어에 필요한 전력 오버헤드가 20배 증가합니다. 결과적으로 행렬 곱셈을 위해 많은 부동 소수점 연산을 수행하는 것은 전력 효율이 낮습니다. 명령어 오버헤드를 상쇄하려면 명령어당 더 많은 계산을 수행할 수 있는 복잡한 명령어를 사용해야 합니다. 이를 위해 Nvidia는 반정밀도 행렬 곱셈 을 수행하는 특수 명령어인 반정밀도 행렬 곱셈 및 누산( HMMA) 명령어를 설계했습니다. 이 명령을 실행하는 데 필요한 전용 하드웨어는 2017년 Volta 아키텍처의 Tesla V100 GPU에 도입된 Tensor Core입니다. Volta 텐서 코어는 Volta 아키텍처 개발의 매우 늦은 시기에 완료되어 테이프 아웃 불과 몇 달 전에 추가되었습니다. 이는 Nvidia가 얼마나 빨리 아키텍처를 전환할 수 있는지를 보여주는 증거입니다.

출처: https://www.youtube.com/watch?v=kLiwvnr4L80&t=869
MMA Instruction Overview - MAA 명령어 Overview
행렬이 주어지면 곱셈 및 누적(Matrix, the Multiply and Accumulate - MMA) 명령어는 D = A * B + C를 계산합니다.
A는 M x K 행렬입니다
B는 K x N 행렬입니다
C와 D는 M x N 행렬입니다.
행렬 모양을 mMnNkK M x N x K로 표시합니다.
전체 계산을 수행하기 위해 먼저 공유 메모리에서 행렬 A, B, C를 스레드 레지스터로 로드하여 각 스레드가 행렬의 일부를 보유하도록 합니다. 두 번째로, 스레드 레지스터에서 행렬을 읽고 텐서 코어에서 계산을 수행한 후 결과를 스레드 레지스터에 저장하는 MMA 명령어를 실행합니다. 마지막으로, 스레드 레지스터의 결과를 다시 공유 메모리에 저장합니다. 전체 계산은 여러 스레드가 공동으로 수행하므로, 각 단계마다 협력하는 스레드 간의 동기화가 필요합니다.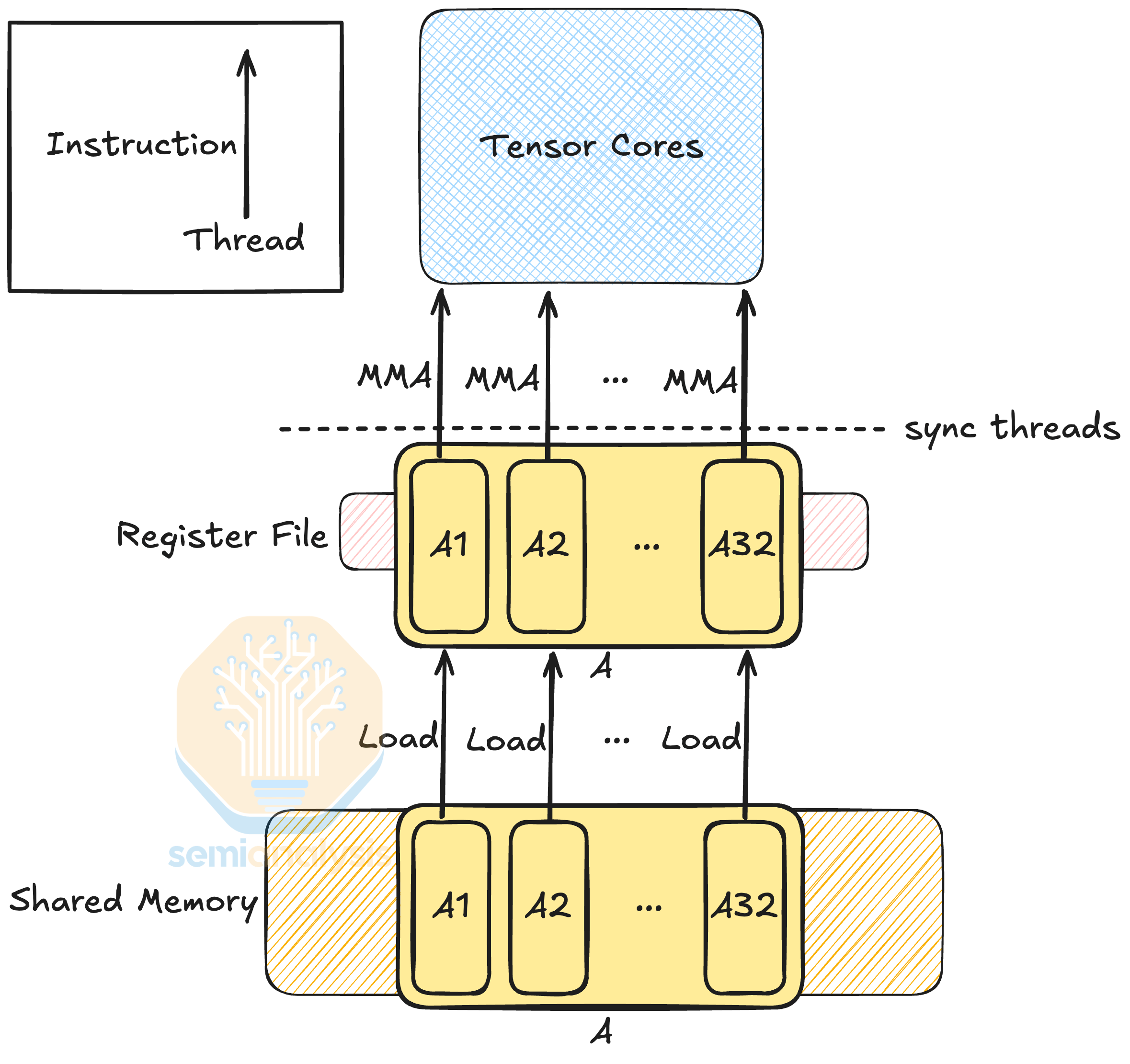
출처: SemiAnalysis
1st Generation Tensor Core – Warp-scoped MMA
Tesla V100 GPU의 SM은 8개의 텐서 코어를 포함하며, 각 코어는 2개씩 그룹화되어 있습니다. 각 텐서 코어는 사이클당 4x4x4 행렬 곱셈에 해당하는 연산을 수행할 수 있으며, 이는 SM당 사이클당 1024 FLOP에 해당합니다.
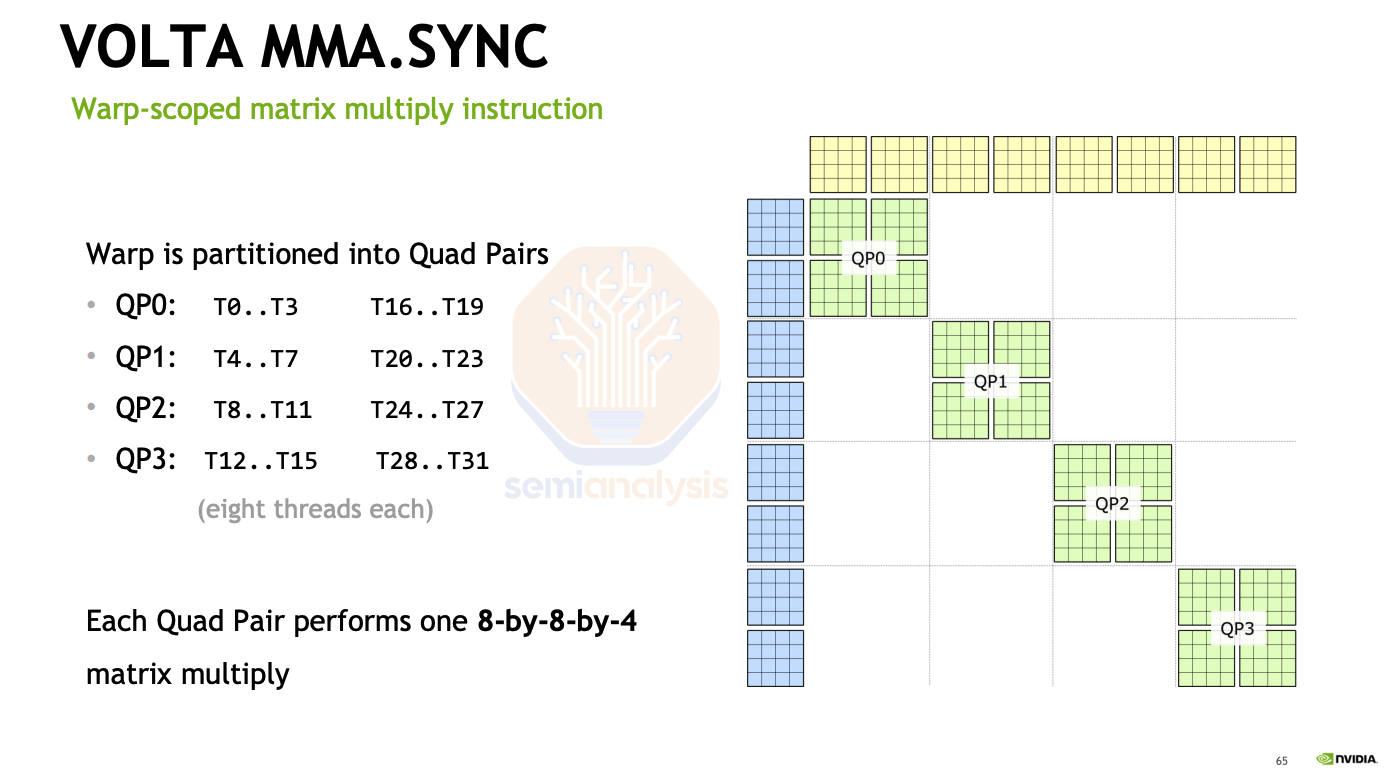
출처:
https://www.olcf.ornl.gov/wp-content/uploads/2019/11/ORNL_Tensor_Core_Training_Aug2019.pdfNVIDIA는 하위 HMMA명령어를 대상으로 PTX 명령어 MMA 를 설계했습니다. Volta 아키텍처에서 MMA 명령어는 8x8x4 행렬 곱셈을 수행하며, 8개의 스레드로 구성된 쿼드페어는 입력 및 출력 행렬을 함께 유지하여 연산에 참여합니다. 여기서 T0은 스레드 0을 나타내고, [T0, T1, T2, T3]과 [T16, T17, T18, T19]는 스레드 그룹이며, 두 스레드 그룹은 쿼드페어를 형성합니다.

출처: SemiAnalysis. CUTLASS 시각화 도구로 생성됨
데이터 유형 측면에서 Volta 텐서 코어는 NVIDIA의 혼합 정밀도 학습 기법에 따라 FP16 입력과 FP32 누적을 지원합니다. 이 기법은 모델 정확도를 떨어뜨리지 않고 낮은 정밀도에서도 모델을 학습할 수 있음을 보여주었습니다.
MMA 레이아웃을 완전히 이해하려면 Citadel의 마이크로벤치마킹 논문 " 마이크로벤치마킹을 통한 NVIDIA Volta GPU 아키텍처 분석" 을 참조하십시오. Volta Tensor Core MMA의 인터리브 레이아웃 패턴을 확인하려면 "프로그래밍 텐서 코어: CUTLASS를 사용한 네이티브 텐서 코어" 슬라이드를 참조하십시오 . 마지막으로, Volta 아키텍처에 대한 기타 정보는 백서 "NVIDIA Tesla V100 GPU 아키텍처" 를 참조.
https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdfTuring
튜링 아키텍처에는 Volta 텐서 코어의 향상된 버전인 2세대 텐서 코어가 포함되어 있으며 , INT8 및 INT4 정밀도 지원이 추가되었습니다. 튜링 텐서 코어는 새로운 워프 수준 동기식 MMA를 지원하며, 이에 대해서는 다음 섹션에서 자세히 설명하겠습니다. 튜링 텐서 코어는 또한 딥 러닝 슈퍼 샘플링(DLSS)을 지원하여 NVIDIA가 게임 그래픽에 딥 러닝을 적용하기 시작한 계기를 마련했습니다. 관심 있는 독자는 NVIDIA 블로그 게시물 "NVIDIA 튜링 아키텍처 심층 분석" 과 튜링 아키텍처 백서 를 참조.
https://developer.nvidia.com/blog/nvidia-turing-architecture-in-depth/NVIDIA Turing Architecture In-Depth | NVIDIA Technical Blog
Fueled by the ongoing growth of the gaming market and its insatiable demand for better 3D graphics, NVIDIA® has evolved the GPU into the world’s leading parallel processing engine for many…
developer.nvidia.com
Ampere
Asynchronous Data Copy - 비동기 데이터 복사
NVIDIA는 Ampere를 통해 비동기 데이터 복사를 도입했습니다. 이는 전역 메모리에서 공유 메모리로 데이터를 비동기 방식으로 직접 복사하는 방식입니다. Volta에서 전역 메모리에서 공유 메모리로 데이터를 로드하려면 스레드가 먼저 전역 메모리에서 레지스터로 데이터를 로드한 다음 공유 메모리에 저장해야 합니다. 그러나 MMA 명령어는 레지스터 사용량이 높고 데이터 로드 작업과 레지스터 파일을 공유해야 하므로 레지스터 부하가 높아지고 RF에서 데이터를 입출력하는 데 메모리 대역폭이 낭비됩니다.
비동기 데이터 복사는 전역 메모리(DRAM)에서 데이터를 가져와 공유 메모리(선택적 L1 액세스 포함)에 직접 저장함으로써 이 문제를 완화합니다. 이를 통해 MMA 명령어를 위한 레지스터를 더 확보할 수 있습니다. 데이터 로딩 및 계산은 비동기 방식으로 수행될 수 있으며, 프로그래밍 모델 관점에서는 더 어렵지만 더 높은 성능을 제공합니다.
이 기능은 PTX 명령어 스레드 수준 비동기 복사(cp.async)로 구현됩니다( 문서 참조 ). 해당 SASS는 LDGSTS(공유 메모리에 대한 비동기 전역 복사)입니다. 정확한 동기화 방법은 비동기 그룹 및 mbarrier 기반 완료 메커니즘이며, 자세한 내용은 여기를 참조.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=tcgen05%2520cp#data-movement-and-conversion-instructions-non-bulk-copy1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com

Volta는 MMA 연산에 참여하기 위해 8개의 스레드로 구성된 쿼드페어가 필요한 반면, Ampere는 32개의 스레드로 구성된 전체 워프가 필요합니다. MMA 명령어를 워프 전체에 적용하면 Ampere의 스레드 레이아웃이 간소화되고 RF 부하가 줄어듭니다. 예를 들어, 16x8x16 크기의 혼합 정밀도 부동 소수점 연산에 대한 스레드 및 데이터 레이아웃은 다음과 같습니다.

출처: SemiAnalysis. CUTLASS 시각화 도구로 생성됨
NVIDIA는 ldmatrixAmpere에서 향상된 벡터화된 로드 연산을 도입했습니다. 와 같이 mma, ldmatrix는 워프 전체에 적용되므로 여러 스레드가 모여 행렬을 로드합니다. 여러 로드 명령어를 실행하는 것보다 주소 생성 레지스터 사용량이 줄어들어 레지스터 부하가 줄어듭니다. 자세한 내용은 CUDA 설명서를 참조.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-ldmatrix1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
ldmatrixTensor Core의 데이터 레이아웃과 일치하는 레이아웃으로 레지스터에 데이터를 로드합니다. Volta의 인터리브 패턴( Tensor Core 프로그래밍: CUTLASS를 사용한 네이티브 Tensor Core 참조)과 비교했을 때, 더 단순한 스레드와 데이터 레이아웃은 프로그래밍 작업의 편의성을 크게 향상시킵니다. Ampere의 메모리 로딩이 Tensor Core와 어떻게 일관성을 유지하는지 자세히 알아보려면 NVIDIA A100에서 CUDA 커널을 사용하여 Tensor Core의 절대 한계를 뛰어넘는 GTC 발표를 참고.
https://www.nvidia.com/en-us/on-demand/session/gtcsj20-s21745/Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100 | GTC Digital March 2020 | NVIDIA On-Demand
NVIDIA Ampere GPU Architecture pushes the performance envelope by doubling the math throughput of Tensor Cores for mixed precision and also adds support fo
www.nvidia.com
Ampere MMA는 반정밀도 데이터 유형의 사실상 표준이 된 Brain Floating Point Format(BF16)을 지원합니다. BF16은 FP32와 동일한 8비트 지수 범위를 제공하지만, 가수는 7비트로, 저장 공간 비용을 절반으로 줄이면서 FP32 수준의 동적 범위를 제공합니다. 또한 BF16은 혼합 정밀도 학습에서 손실 스케일링의 필요성을 제거합니다.
Hopper
Thread Block Cluster
SM 수가 증가함에 따라 SM과 전체 GPU 간의 크기 차이가 커졌습니다. CTA(SM에 매핑)와 그리드(전체 GPU에 매핑) 간의 제어를 더욱 세밀하게 제공하기 위해 NVIDIA는 Hopper에 새로운 스레드 계층 구조 수준인 스레드 블록 클러스터를 추가했습니다 . 이 계층 구조는 동일한 그래픽 처리 클러스터(GPC)에 물리적으로 위치한 SM 그룹에 매핑됩니다. 스레드 블록 클러스터는 협력 그리드 배열(CGA)이라고도 하며, CUDA 문서에서는 클러스터라고 합니다( 자세한 내용은 여기를 참조).
https://stackoverflow.com/questions/78510678/whats-cga-in-cuda-programming-model스레드 블록 클러스터 내의 CTA는 동일한 GPC 내의 SM에 공동 스케줄링되며, 기본적으로 SM당 하나의 CTA로 분산됩니다. 이러한 SM의 공유 메모리 파티션은 Distributed Shared Memory(DSMEM)를 형성합니다 . 스레드는 전용 SM 간 네트워크를 통해(L2 캐시를 거치지 않고) 다른 SM에서 낮은 지연 시간으로 공유 메모리에 액세스할 수 있습니다. GPC 하드웨어 실행 장치를 프로그래밍 모델에 노출함으로써 프로그래머는 데이터 이동을 줄이고 데이터 지역성을 향상시킬 수 있습니

출처: GTC 발표 - https://www.nvidia.com/en-us/on-demand/session/gtcspring22-s42663/Inside the NVIDIA Hopper Architecture | GTC Digital Spring 2022 | NVIDIA On-Demand
This talk will cover the details behind NVIDIA’s new Hopper GPU architecture and its first implementation in the NVIDIA H100 GPU.
www.nvidia.com
Tensor Memory Accelerator
데이터 가져오기 효율성을 개선하기 위해 NVIDIA는 각 Hopper SM에 TMA(Tensor Memory Accelerator)를 추가했습니다. TMA는 글로벌 메모리와 공유 메모리 간의 대량 비동기 데이터 전송(대량 비동기 복사)을 가속화하는 전용 하드웨어 장치입니다.
CTA의 단일 스레드는 TMA 복사 작업을 시작할 수 있습니다. TMA는 스레드가 다른 독립적인 작업을 수행할 수 있도록 하여 주소 생성을 처리하고 범위를 벗어난 처리와 같은 추가적인 이점을 제공합니다. PTX에서 해당 명령어는 이며 , 이 CUDA 문서 섹션cp.async.bulk 에 자세히 설명되어 있습니다.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=tcgen05%2520cp#data-movement-and-conversion-instructions-bulk-copy1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
그러나 작은 요청의 경우, TMA 로드는 주소 생성 오버헤드로 인해 일반적인 비동기 데이터 복사보다 지연 시간이 더 깁니다. 따라서 NVIDIA는 프로그래머에게 오버헤드를 상쇄하기 위해 대용량 데이터 복사에 TMA를 사용할 것을 권장합니다. 예를 들어, LLM 추론에서 TMA는 KV 캐시를 작은 청크로 로드하는 워크로드에는 적합하지 않지만, 각 청크가 16바이트의 배수일 때는 잘 작동합니다. 이에 대한 더 구체적인 예는 SGLang 접두사 캐싱 , FlashInfer 3.2.1절, 빠른 디코딩을 위한 하드웨어 효율적 주의 4.2절, ThunderKittens MLA 디코드를 참조.
TMA는 멀티캐스트라는 데이터 로딩 모드도 지원합니다. 멀티캐스트는 TMA가 글로벌 메모리에서 멀티캐스트 마스크로 지정된 스레드 블록 클러스터 내 여러 SM의 공유 메모리로 데이터를 로드하는 방식입니다. 동일한 데이터를 여러 SM에 로드하는 여러 글로벌 메모리 로드를 실행하는 대신, 멀티캐스트는 한 번에 로드를 완료합니다. 구체적으로, 스레드 블록 클러스터 내 여러 CTA는 데이터의 일부를 해당 SMEM에 로드하고 DSMEM을 통해 데이터를 공유합니다. 이를 통해 L2 캐시 트래픽이 감소하고 결과적으로 HBM 트래픽도 감소합니다. 자세한 내용은 Jay Shah의 TMA 튜토리얼을 참조.
https://research.colfax-intl.com/tutorial-hopper-tma/CUTLASS Tutorial: Mastering the NVIDIA® Tensor Memory Accelerator (TMA)
TMA (Tensor Memory Accelerator) is a new feature introduced in the NVIDIA Hopper™ architecture for doing asynchronous memory copy between a GPU’s global memory (GMEM) and the shared me…
research.colfax-intl.com

출처: SemiAnalysis, GTC 발표 - https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s51413/4th Generation Tensor Core – Warpgroup-level Asynchronous MMA (4세대 텐서 코어 - 워프그룹-레밸 비동기 MMA)
NVIDIA는 Hopper를 통해 새로운 유형의 MMA인 WarpGroup-Level MMA( wgmma)를 도입했습니다. wgmma워프그룹 전체에 적용되며, 이는 4개의 워프로 구성된 워프그룹이 집합적으로 MMA 연산을 수행함을 의미합니다. wgmma더 다양한 형태를 지원합니다. 예를 들어, 혼합 정밀도 MMA는 를 지원하며 m64nNk16, 여기서 N은 8에서 256까지의 8의 배수가 될 수 있습니다. 는 wgmma.mma_async새로운 SASS 세트로 축소됩니다. GMMA또 다른 예로, 반정밀도 wgmma명령어는 를 축소합니다.HGMMAMMA 모양과 데이터 유형에 대한 자세한 내용은 이 CUDA 문서 섹션을 참조.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=tcgen05%2520cp#asynchronous-warpgroup-level-matrix-shape1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
워프그룹의 모든 스레드는 출력 행렬을 각자의 레지스터에 공동으로 저장하지만, Hopper Tensor Core는 레지스터 대신 공유 메모리에서 피연산자를 직접 로드하여 레지스터 공간과 대역폭을 절약할 수 있습니다. 구체적으로, 피연산자 행렬 A는 레지스터 또는 공유 메모리에 상주할 수 있는 반면, 피연산자 행렬 B는 공유 메모리를 통해서만 접근할 수 있습니다. 자세한 내용은 CUDA 문서의 wgmma 섹션을 참조하십시오.wgmma완료 메커니즘, SMEM 레이아웃 등이 있습니다.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html?highlight=tcgen05%2520cp#asynchronous-warpgroup-level-matrix-instructions1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com

출처: SemiAnalysis데이터 유형 측면에서 wgmmaHopper는 FP32 누적을 지원하는 8비트 부동 소수점 데이터 유형(E4M3 및 E5M2)을 도입했습니다. 실제로 누적 경로는 22비트 고정 소수점 형식(가수, 부호, 지수 비트 13비트)으로 구현되어 실제 32비트 누적에 비해 동적 범위가 제한되었습니다. 텐서 코어 정밀도가 낮아졌기 때문에, 훈련 정확도를 제한하지 않기 위해 모든 N_c 누적은 CUDA 코어에서 수행되어야 합니다. ( 본 논문 3.3.2절 참조 ) 이렇게 정밀도가 낮아진 누적은 효율성을 향상시키지만 정확도는 떨어집니다.
https://arxiv.org/abs/2412.19437DeepSeek-V3 Technical Report
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and Deep
arxiv.org
Hopper 아키텍처에 대한 자세한 내용은 다음을 참조.
- GTC 발표: https://www.nvidia.com/en-us/on-demand/session/gtcspring22-s42663/Inside the NVIDIA Hopper Architecture | GTC Digital Spring 2022 | NVIDIA On-Demand
This talk will cover the details behind NVIDIA’s new Hopper GPU architecture and its first implementation in the NVIDIA H100 GPU.
www.nvidia.com
- NVIDIA 블로그 게시물 개요: https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
NVIDIA Hopper Architecture In-Depth | NVIDIA Technical Blog
Everything you want to know about the new H100 GPU.
developer.nvidia.com
- 백서: https://resources.nvidia.com/en-us-data-center-overview/gtc22-whitepaper-hopper
NVIDIA H100 Tensor Core GPU Architecture Overview
A high-level overview of NVIDIA H100, new H100-based DGX, DGX SuperPOD, and HGX systems, and a H100-based Converged Accelerator. This is followed by a deep dive into the H100 hardware architecture, efficiency improvements, and new programming features.
resources.nvidia.com
- 마이크로 벤치마킹: https://arxiv.org/abs/2402.13499
Benchmarking and Dissecting the Nvidia Hopper GPU Architecture
Graphics processing units (GPUs) are continually evolving to cater to the computational demands of contemporary general-purpose workloads, particularly those driven by artificial intelligence (AI) utilizing deep learning techniques. A substantial body of s
arxiv.org
- 마이크로 벤치마킹: https://arxiv.org/abs/2501.12084
Dissecting the NVIDIA Hopper Architecture through Microbenchmarking and Multiple Level Analysis
Modern GPUs, with their specialized hardware like tensor cores, are essential for demanding AI and deep learning applications. This study presents a comprehensive, multi-level microbenchmarking analysis of the NVIDIA Hopper GPU architecture, delving into i
arxiv.org
Hopper GPU를 프로그래밍하는 방법에 대한 예는 다음을 참조.
- GTC 발표: https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s51119/?playlistId=playList-43cec6e2-ef10-488a-aba2-6ef775db065aOptimizing Applications for Hopper Architecture | GTC Digital Spring 2023 | NVIDIA On-Demand
We’ll take a deep dive into Hopper GPU Architecture, with practical code examples on how to optimize your application for NVIDIA H100 GPU
www.nvidia.com
- CUTLASS 발표: https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s51413/
Developing Optimal CUDA Kernels on Hopper Tensor Cores | GTC Digital Spring 2023 | NVIDIA On-Demand
NVIDIA’s H100 introduces fourth-generation Tensor Cores to GPU computing, with over twice the peak performance of the previous generation
www.nvidia.com
- Colfax 블로그 게시물: https://research.colfax-intl.com/cutlass-tutorial-wgmma-hopper/
CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs
No series of CUDA® tutorials is complete without a section on GEMM (GEneral Matrix Multiplication). Arguably the most important routine on modern GPUs, GEMM constitutes the majority of compute done…
research.colfax-intl.com
Blackwell
Tensor Memory
극심한 레지스터 압박은 Hopper에게 가해지지 않았고, 이는 Tensor Core 연산에 특화된 새로운 메모리인 Tensor Memory(TMEM) 의 탄생으로 이어졌습니다 . 모든 SM에서 TMEM은 128개의 행(레인)과 512개의 열로 구성된 4바이트 셀을 가지며, 총 256KB입니다. 이는 SM의 레지스터 파일 크기와 같습니다.
TMEM은 제한된 메모리 접근 패턴을 가지고 있습니다. 구체적으로, 전체 TMEM에 접근하려면 워프그룹이 필요하며, 워프그룹 내의 각 워프는 특정 레인 세트에만 접근할 수 있습니다. 메모리 접근 패턴을 제한함으로써 하드웨어 설계자는 접근 포트 수를 줄여 칩 공간을 절약할 수 있습니다. 반면, 이러한 설계는 에필로그 연산을 수행하려면 워프그룹이 필요하다는 것을 의미합니다. 공유 메모리와 달리, 프로그래머는 TMEM을 할당, 할당 해제, TMEM 내부/외부로의 데이터 복사 등 명시적으로 관리해야 합니다.
출처: GTC 발표 https://www.nvidia.com/en-us/on-demand/session/gtc25-s72720/
Programming Blackwell Tensor Cores with CUTLASS | GTC 25 2025 | NVIDIA On-Demand
The release of CUTLASS 3.8 enables programmers to write optimized Tensor Core kernels for the NVIDIA Blackwell architecture
www.nvidia.com
CTA Pair
스레드 블록 클러스터에 있는 두 CTA는 Thread Block Cluster 에서 CTA 순위가 마지막 비트만큼 다를 경우(예: 0과 1, 4와 5) CTA 쌍을 형성합니다. CTA 쌍은 두 개의 SM으로 구성된 텍스처 처리 클러스터(TPC)에 매핑되며, 다른 TPC와 결합하여 GPC를 형성합니다. Blackwell Tensor Core 연산이 CTA 쌍 단위로 수행될 때, 두 CTA는 입력 피연산자를 공유할 수 있습니다. 이러한 공유는 SMEM 용량과 대역폭 요구 사항을 모두 줄입니다.
Tensor Core 5th Generation MMA텐서 코어 5세대 MMA 명령어( tcgen05.mmaPTX)는 행렬 저장을 위해 레지스터를 사용하지 않도록 완전히 변경되었습니다. 피연산자는 이제 공유 메모리와 텐서 메모리에 저장됩니다.
구체적으로, MMA가 D = A * B + D를 계산한다고 가정해 보겠습니다. 스레드 레지스터를 사용하지 않으면 복잡한 데이터 레이아웃이 제거되고 에필로그 연산과 같은 다른 작업을 위한 스레드 레지스터 공간이 확보됩니다. wgmma워프 그룹을 사용하여 MMA 연산을 시작하는 것과 달리, tcgen05.mma는 단일 스레드 시맨틱을 가지므로 단일 스레드가 MMA 연산을 시작합니다. 따라서 워프가 MMA 연산을 실행하는 역할을 하지 않습니다.
출처: SemiAnalysis
주목할 만한 MMA 변형 중 하나는 MMA.2SM으로, 두 개의 SM을 사용하여 MMA 작업을 공동으로 수행합니다. MMA.2SM은 CTA 쌍 수준에서 실행되며, tcgen05.mma단일 스레드 시맨틱을 가지므로 CTA 쌍의 리더 CTA에 있는 단일 스레드가 MMA.2SM을 실행합니다. 여기서는 데이터 경로 구성 레이아웃 A를 보여줍니다. 레이아웃 A는 MMA.2SM이 1SM 버전( 레이아웃 D ) 에 비해 M 차원을 두 배로 늘렸기 때문에 두 SM이 서로 다른 행렬 A와 D 타일을 로드합니다. 또한, MMA.2SM은 행렬 B를 분할하여 로드되는 데이터 양을 절반으로 줄입니다.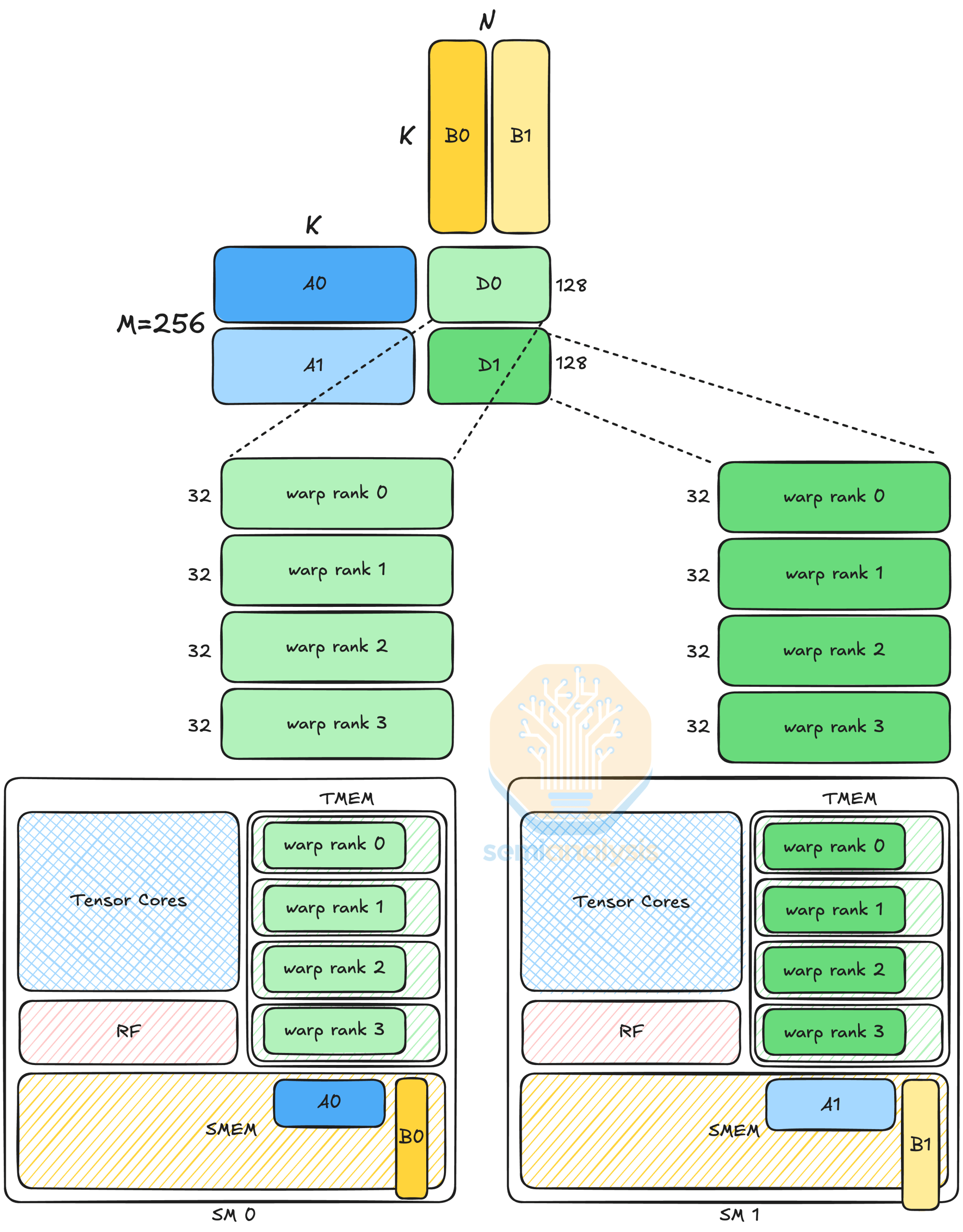
출처: SemiAnalysis, GTC 발표 - https://www.nvidia.com/en-us/on-demand/session/gtc25-s72720/Programming Blackwell Tensor Cores with CUTLASS | GTC 25 2025 | NVIDIA On-Demand
The release of CUTLASS 3.8 enables programmers to write optimized Tensor Core kernels for the NVIDIA Blackwell architecture
www.nvidia.com
행렬 B는 두 SM에서 공유되므로 타일 B0과 B1은 DSMEM을 통해 통신해야 합니다. DSMEM과 SMEM 사이에 대역폭 차이가 있지만, 더 작은 타일을 로딩하기 때문에 조정에 미치는 영향은 미미합니다. 하지만 Blackwell에서는 TPC 내 SM 간의 통신 대역폭이 DSMEM보다 높을 것으로 예상되므로, MMA.2SM은 이를 활용하여 더 나은 성능을 달성합니다.
5세대 텐서 코어는 일반적인 행렬 곱셈 외에도 합성곱 연산을 수행할 수 있습니다. 컬렉터 버퍼를 통해 가중치 고정 패턴을 지원하며, 이 버퍼는 재사용을 위해 행렬 B를 캐시합니다. 자세한 내용은 CUDA 설명서 와 해당 가중치 고정 MMA 명령어를tcgen05.mma 참조.
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tcgen05-mma1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tcgen05-mma-instructions-mma-ws
1. Introduction — PTX ISA 8.8 documentation
While the specific resources available in a given target GPU will vary, the kinds of resources will be common across platforms, and these resources are abstracted in PTX through state spaces and data types. PTX includes built-in opaque types for defining t
docs.nvidia.com
지원되는 데이터 유형 측면에서 Blackwell은 MXFP8, MXFP6, MXFP4를 포함한 마이크로스케일링 부동 소수점 형식(MXFP)을 지원합니다. 자세한 내용은 아래 문서를 참조.
https://arxiv.org/abs/2310.10537Microscaling Data Formats for Deep Learning
Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer t
arxiv.org
Blackwell은 또한 MXFP4보다 정확도가 높은 것으로 알려진 NVIDIA 자체 NVFP4 형식을 지원합니다. 이는 더 작은 블록 크기, 다른 스케일링 계수 데이터 형식, 그리고 2단계 양자화 방식( GitHub 이슈 참조 ) 때문일 가능성이 높습니다 . 데이터 형식 비교는 이 문서를 참조.
https://arxiv.org/abs/2505.19115FP4 All the Way: Fully Quantized Training of LLMs
We demonstrate, for the first time, fully quantized training (FQT) of large language models (LLMs) using predominantly 4-bit floating-point (FP4) precision for weights, activations, and gradients on datasets up to 200 billion tokens. We extensively investi
arxiv.org
Blackwell의 경우, FP8과 FP6의 이론적 처리량이 동일하므로 텐서 코어에서 물리적 회로를 공유한다고 생각합니다. 반면, CDNA4는 FP6 유닛이 FP4와 데이터 경로를 공유하기 때문에 FP8보다 FP6 처리량이 두 배 더 높습니다. UDNA는 FP6 유닛이 FP8과 데이터 경로를 공유하도록 전환할 것으로 예상됩니다.
Side Note: Structured Sparsity - 사이드 노트: 구조화된 희소성
Ampere는 2:4 구조적 희소성을 특징으로 하며, 이는 이론적으로 텐서 코어 처리량을 두 배로 증가시킵니다. 이는 가중치 행렬을 가지치기하여 4개의 요소 중 2개가 0이 되도록 함으로써 달성됩니다. 이 형식에서는 0인 요소를 제거하여 행렬을 압축하고, 추가 메타데이터 인덱스 행렬을 통해 해당 요소의 위치를 기록하여 메모리 사용량과 대역폭을 약 절반으로 줄입니다.중국 엔지니어들이 작성한 마이크로벤치마킹 논문 에 따르면 , Ampere의 구조화된 희소성은 명령어 수준에서 큰 크기의 MMA 연산을 2배 빠르게 수행할 수 있습니다. 또한 Hopper에서 구조화된 희소성 wgmma명령어는 2배 빠른 속도를 달성하고 가중치를 로드하는 데 사용되는 메모리 대역폭을 최대 2배 절약할 수 있음을 보여줍니다.
https://arxiv.org/abs/2501.12084Dissecting the NVIDIA Hopper Architecture through Microbenchmarking and Multiple Level Analysis
Modern GPUs, with their specialized hardware like tensor cores, are essential for demanding AI and deep learning applications. This study presents a comprehensive, multi-level microbenchmarking analysis of the NVIDIA Hopper GPU architecture, delving into i
arxiv.org
안타깝게도 2:4 구조화된 희소성 GEMM 커널은 호퍼에서 밀도가 높은 커널에 비해 2배에 가까운 속도 향상을 달성할 수 없습니다. 이는 모델 정확도를 유지하면서 구조화된 가지치기를 수행하는 데 어려움이 있고, cuSPARSELt 커널이 최적화되지 않았으며, TDP 제한이 있기 때문입니다. 중국 AI 연구실과 소수의 서구권 실험 논문을 제외하고 , 대부분의 AI 연구실은 프로덕션 추론에서 2:4 구조화된 희소성을 무시하고 양자화 및 증류에 집중합니다. Meta는 Llama에서 이를 실험하고 있지만, 이 역시 많은 경우 막다른 길입니다.
더욱이, 정확도 손실을 0으로 유지하면서 2:4 FP8 구조적 희소성 또는 4:8 FP4 구조적 희소성으로 성능 향상을 보여준 폐쇄형 또는 개방형 모델이 부족하고, 구조적 프루닝에 전념하는 리소스도 전반적으로 부족합니다 . NVIDIA는 SOTA 개방형 모델이 추론에 구조적 프루닝을 활용할 수 있다는 것을 지속적으로 보여주지 않는 한, 기조연설과 마케팅 자료에서 Jensen math 의 구조적 희소성 실패를 멈추어야 합니다. 좋은 첫 번째 단계는 DeepSeek에서 구조적 희소성을 수행하고, NVFP4와 같은 증류 및 양자화와 같은 다른 기법을 통해 성능이 향상될 수 있음을 보여주는 것입니다.
https://semianalysis.com/2025/03/19/nvidia-gtc-2025-built-for-reasoning-vera-rubin-kyber-cpo-dynamo-inference-jensen-math-feynman/#jensen-math-changes-every-yearNVIDIA GTC 2025 – Built For Reasoning, Vera Rubin, Kyber, CPO, Dynamo Inference, Jensen Math, Feynman
The Reasoning Token Explosion AI model progress has accelerated tremendously, and in the last six months, models have improved more than in the previous six months. This trend will continue b…
semianalysis.com

출처: https://developer.nvidia.com/blog/exploiting-ampere-structured-sparsity-with-cusparselt/NVIDIA는 5세대 텐서 코어에서 NVFP4 데이터 유형에 대해 쌍별 4:8 구조적 희소성을 도입했습니다. 이 방식에서는 8개 요소를 4개의 연속된 쌍으로 그룹화하고, 그중 정확히 두 쌍은 0이 아닌 값을 포함해야 하며 나머지 두 쌍은 0으로 프루닝됩니다. NVFP4는 하위 바이트 데이터 유형이기 때문에 이러한 제약 조건 때문에 NVIDIA가 쌍별 4:8 패턴을 채택하게 되었다고 생각합니다. 4:8 희소성은 이전의 2:4 패턴보다 더 관대해 보일 수 있지만, 추가된 쌍별 요구 사항은 실제로 프루닝(pruning) 중에 모델 정확도를 유지하려는 ML 엔지니어에게 더 완화된 제약 조건은 아닙니다.

출처: https://docs.nvidia.com/cuda/parallel-thread-execution/_images/fp4-metadata-example.pngTensor Core Size Increases - 텐서 코어 사이즈 증가
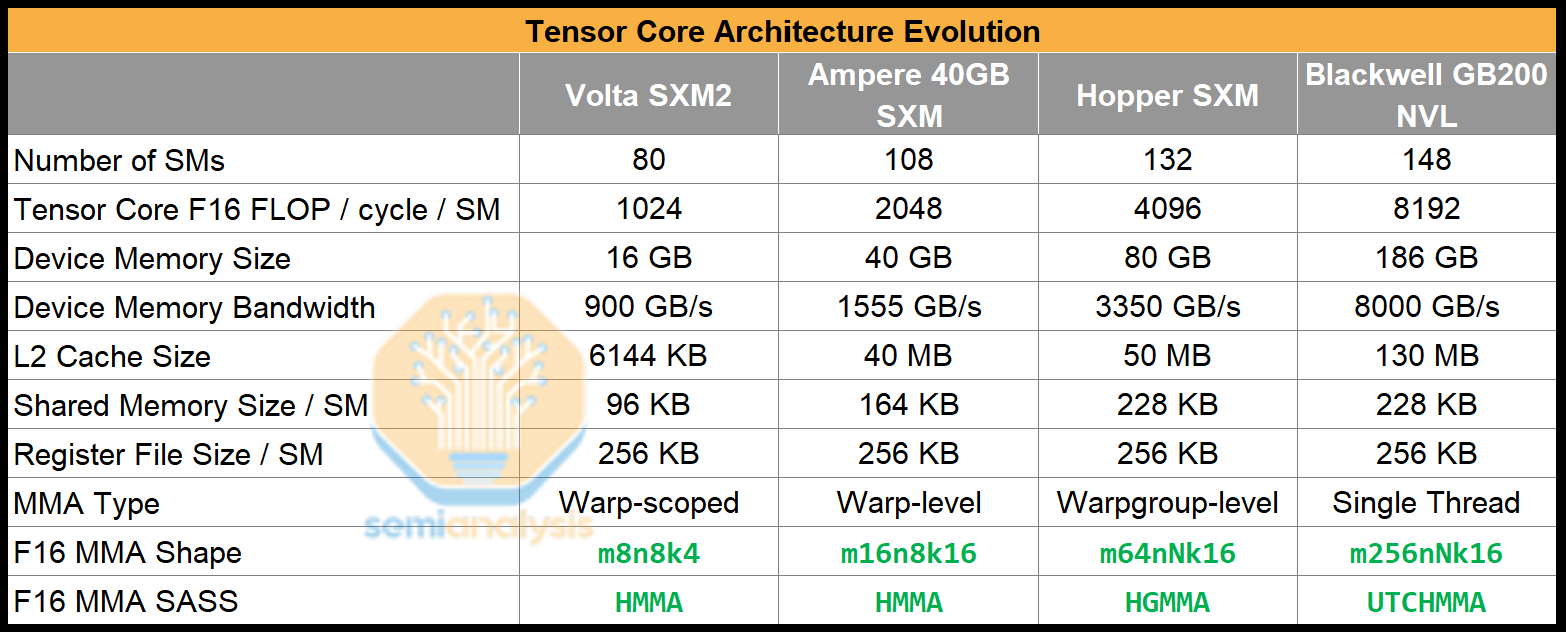
출처: SemiAnalysis, NVIDIA
여러 세대에 걸쳐 NVIDIA는 텐서 코어 수보다 텐서 코어 크기를 더 적극적으로 확장해 왔습니다. NVIDIA는 코어 수보다 텐서 코어 크기를 확장하는 것이 행렬 곱셈의 성능 특성에 더 적합하기 때문에 이를 선택했습니다. 구체적으로, 문제 크기를 확장할 때 행렬 곱셈 연산은 3차 함수로 증가하는 반면, 데이터 이동은 2차 함수로 증가합니다. 즉, 연산 강도는 선형적으로 증가합니다. O(n) 연산 강도와 데이터 이동이 연산보다 비용이 더 많이 든다는 사실이 텐서 코어 크기 증가의 원인이 되었습니다.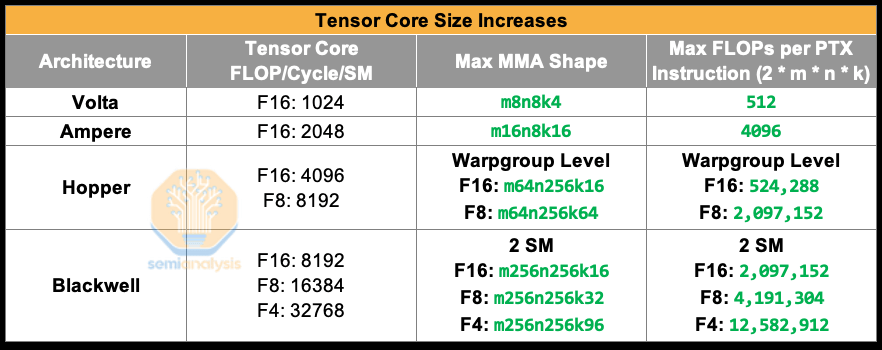
출처: SemiAnalysis, NVIDIA
하지만 코어 크기와 코어 수를 확장하면 양자화 효과가 감소합니다. 특히, 코어 수가 많으면 타일 양자화 효과가 발생하고 , 코어 크기가 크면 파동 양자화 효과가 발생합니다. 파동 양자화 효과는 작업 단위의 수가 작업자 수로 완전히 나누어 떨어지지 않을 때 발생하며, 이로 인해 최종적으로 더 작은 작업 배치를 처리할 때 사용률이 떨어집니다. 텐서 코어 크기를 늘리면 본질적으로 작업 단위 크기가 증가하여 작은 행렬의 사용률이 낮아집니다( ThunderKittens 블로그 게시물 참조 ).
https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#wave-quanthttps://hazyresearch.stanford.edu/blog/2025-03-15-tk-blackwell

출처: SemiAnalysis
산술 강도의 선형적 증가는 MMA 형태의 증가에도 영향을 미칩니다. 더 큰 MMA 형태는 피연산자 공유 세분성을 향상시킵니다. 특히, 더 적은 수의 큰 타일을 실행하면 데이터 재사용성이 향상되어 RF 및 SMEM의 메모리 사용량과 대역폭이 절약됩니다. Blackwell 이전 아키텍처의 경우, 이로 인해 MMA 연산을 함께 수행하는 스레드 수가 증가했습니다. 8개 스레드로 구성된 쿼드 페어(Volta)에서 32개 스레드로 구성된 워프(Ampere)로, 그리고 128개 스레드로 구성된 워프 그룹(Hopper)으로 증가했습니다.Memory Size Increase- 메모리 크기 증가
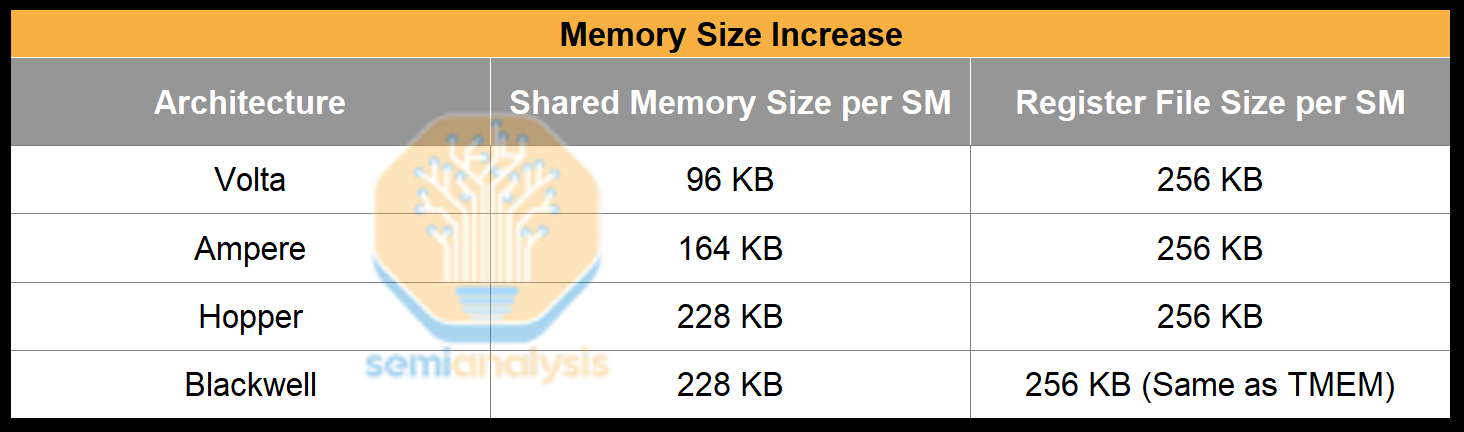
출처: SemiAnalysis, NVIDIA
공유 메모리는 거의 모든 세대에서 증가했지만, 레지스터 파일 크기는 변하지 않았습니다. 그 이유는 Tensor Core 처리량 증가에 더 깊은 스테이징 버퍼가 필요하기 때문입니다.
텐서 코어는 글로벌 메모리가 로드할 수 있는 속도보다 훨씬 빠르게 데이터를 소비하기 때문에, 스테이징 메모리를 사용하여 데이터를 버퍼링합니다. 이를 통해 메모리 로딩이 MMA 작업보다 먼저 실행될 수 있습니다. 텐서 코어 처리량은 세대마다 두 배로 증가했지만, 글로벌 메모리 로드 지연 시간은 감소하지 않고 오히려 증가했습니다. 따라서 더 많은 데이터를 버퍼링하려면 스테이징 메모리 크기를 늘려야 합니다. 이를 구현하기 위해 NVIDIA는 텐서 코어의 스테이징 메모리로 공유 메모리를 선택했습니다. 이는 공유 메모리가 증가했지만 레지스터 파일 크기는 변하지 않은 이유를 설명합니다.
하지만 Blackwell의 공유 메모리 크기는 Hopper보다 증가하지 않았습니다. tcgen05 MMA는 두 개의 SM을 활용할 수 있기 때문에 각 SM의 공유 메모리는 피연산자의 절반만 로드하면 됩니다. 따라서 Blackwell의 공유 메모리 크기는 사실상 두 배가 되었습니다.
NVIDIA의 스테이징 메모리 선택은 피연산자 위치가 레지스터에서 공유 메모리로 점차 이동한 이유도 설명합니다. NVIDIA는 텐서 코어 처리량 증가를 지원하기 위해 Blackwell에 TMEM을 추가했습니다. TMEM은 텐서 코어에 더 가깝게 배치되므로 전력 효율이 더 높습니다. 또한, 별도의 메모리를 사용하면 텐서 코어 saturation을 위한 총 메모리 대역폭이 증가합니다.
모든 피연산자 중에서 행렬 D는 항상 TMEM에 저장됩니다. 행렬 D는 행렬 A와 B보다 더 자주 접근되므로 이 설계를 통해 TMEM의 전력 효율성을 활용할 수 있습니다. 예를 들어, 단순 타일 행렬 곱셈에서 타일을 계산할 때, 행렬 D의 타일은 2Kt번 접근됩니다(Kt번은 읽고 Kt번은 씁니다. Kt는 K 차원의 타일 개수입니다). 반면 행렬 A의 타일과 행렬 B의 타일은 한 번만 접근합니다.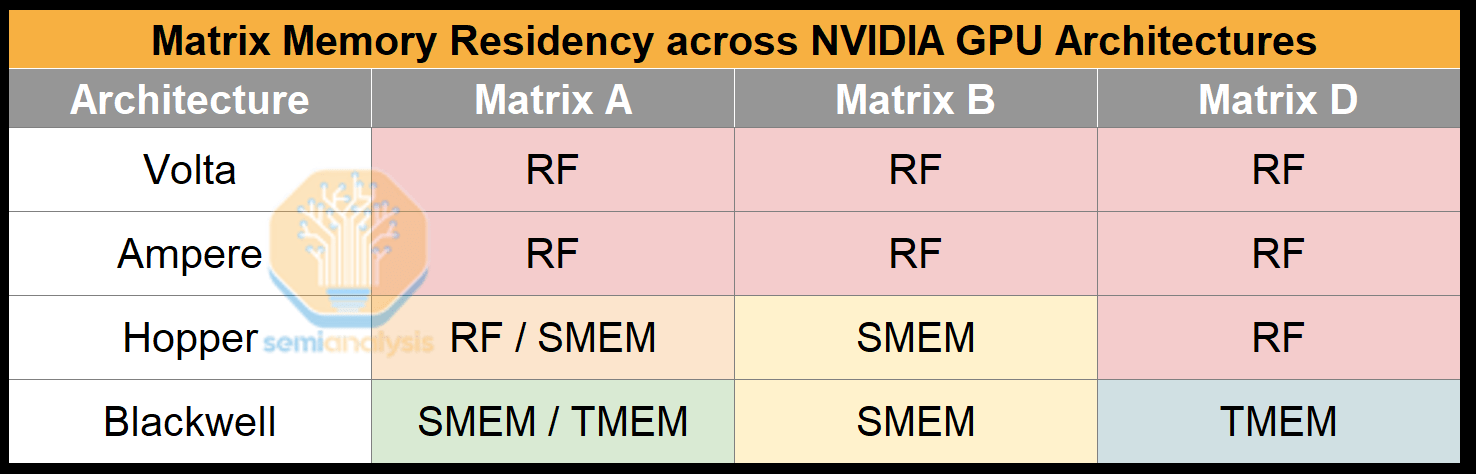
출처: SemiAnalysis, NVIDIA
Asynchrony of MMA Instruction - MMA 명령어의 비동기화

출처: SemiAnalysis, NVIDIA
"H"는 UTCHMMA,HGMMA,HMMA 16비트 형식이므로 반정밀도를 의미하고, "Q"는 8비트가 전정밀도(32비트)의 4분의 1이므로 4분의 1정밀도(8비트)를 의미합니다. "O"는 FP4 QGMMA,UTCQMMA처럼 32비트의 8분의 1을 의미하는 "8진수(Octal)"를 의미합니다 .UTCOMMA
MMA 명령어는 겉보기에 동기에서 비동기로 전환된 것처럼 보였습니다. 실제로 MMA 명령어는 SASS 수준에서 중첩의 필요성 때문에 점차 비동기화되었습니다.LDSM지침.
SASS 수준에서 MMA 작업에는 LDSM공유 메모리에서 레지스터 파일로 매트릭스 타일을 로드하기 위한 하나의 명령어를 실행한 다음 두 개의 명령어를 실행하는 것이 포함됩니다.HMMAMMA 수행 지침. 실행 중에 두 가지HMMA명령어는 비동기적으로 실행되며, 하드웨어 연동을 통해 레지스터 사용을 차단합니다. 하드웨어 연동은 LDSM 명령어의 중복을 허용하지 않으므로, 하나 LDSM와 두 개의 명령어를 순차적으로 실행하는 것은 불가능합니다.HMMA명령어는 명령어 실행 파이프라인에 작은 버블을 생성합니다. 그러나 텐서 코어가 너무 빨라져 이 버블은 무시할 수 없는 수준의 성능 손실을 초래하며, 이로 인해 MMA에 비동기 완료 메커니즘이 필요하게 됩니다.
Hopper는 비동기 완료 메커니즘인 commit과 fence를 지원합니다 wgmma. HGMMA명령어가 실행될 때 레지스터 사용을 보호하는 하드웨어 인터록이 없습니다. 대신 컴파일러는 LDSM다음 MMA를 예약하고 사용합니다.FENCE다음 HGMMA대기를 유지하라는 명령입니다. Blackwell을 사용하면 MMA 작업이 완전히 비동기적으로 수행됩니다. 텐서 메모리( tcgen05.ld / tcgen05.st / tcgen05.cp )에 로드하는 명령은 모두 명시적으로 비동기적입니다.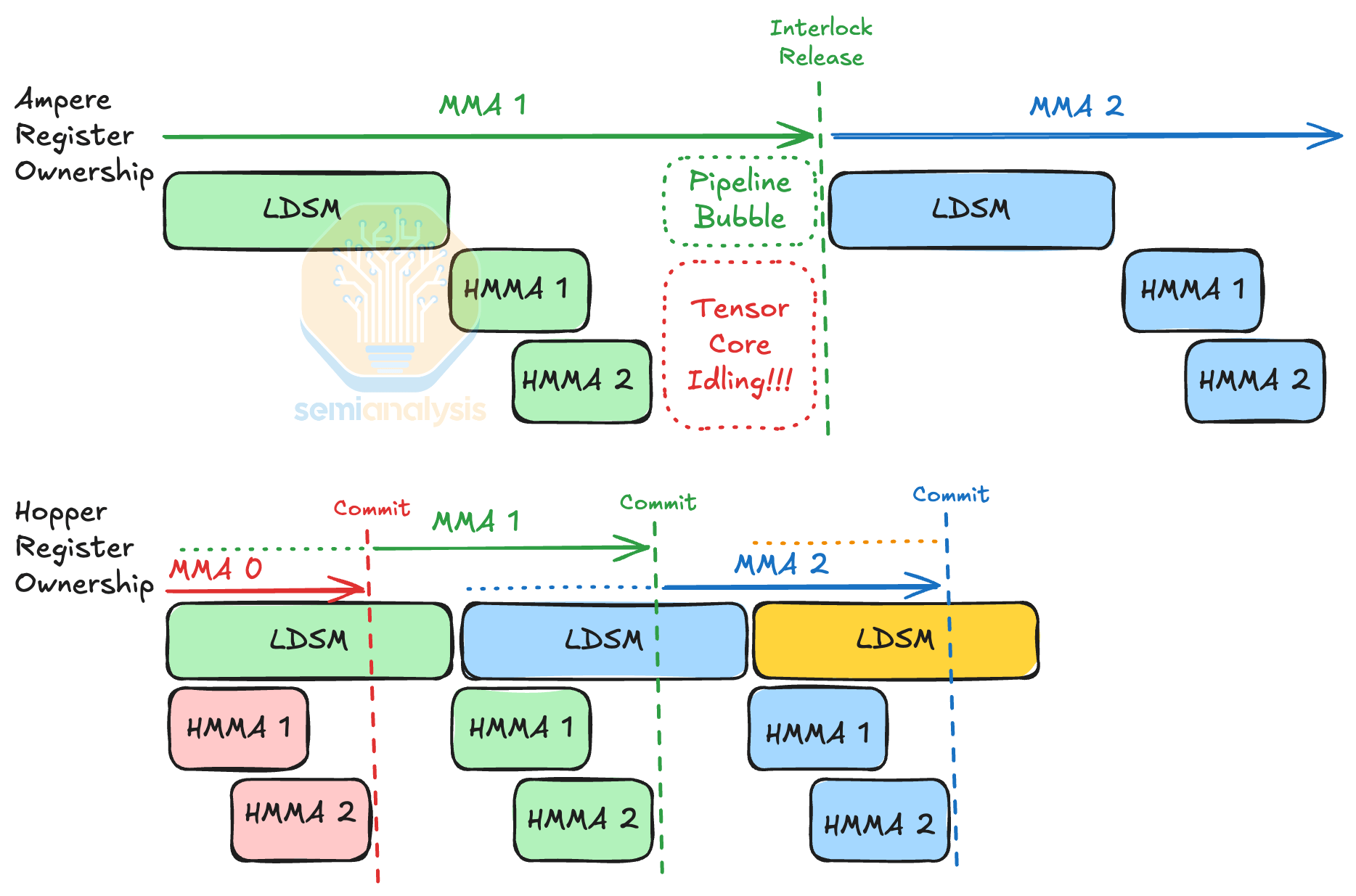
출처: SemiAnalysisData Type Precision Reduction - 데이터 타입 정확도 축소

출처: SemiAnalysis, NVIDIA
NVIDIA는 각 세대의 NVIDIA Tensor 코어를 통해 16비트부터 4비트까지 낮은 정밀도의 데이터 유형을 계속해서 추가해 왔습니다. 이는 딥 러닝 워크로드가 낮은 정밀도에 대한 내성이 매우 높기 때문입니다. 특히 추론의 경우, 학습보다 더 낮은 정밀도를 사용할 수 있습니다. 낮은 정밀도는 전력 효율이 높고, 실리콘 바닥 공간을 덜 차지하며, 더 높은 컴퓨팅 처리량을 달성합니다. 새로운 세대에서는 NVIDIA가 실리콘 면적과 전력 예산 내에서 낮은 정밀도의 데이터 유형을 우선시하기 위해 FP64 지원을 중단하는 모습도 볼 수 있습니다.
흥미롭게도, 우선순위는 정수 데이터 유형 지원에도 영향을 미쳤습니다. Hopper 이후 INT4 데이터 유형은 더 이상 지원되지 않으며, Blackwell Ultra에서는 INT8 컴퓨팅 처리량이 더 낮습니다. 이는 저정밀도 정수 데이터 유형의 인기가 늦어졌기 때문입니다. Turing은 INT8과 INT4를 지원했지만, 새로운 추론 양자화 방법이 LLM(저정밀도 선형 모델)을 제공하기 위해 INT4의 간결성을 활용할 수 있게 된 것은 4년 후였습니다. 당시 NVIDIA는 이미 Hopper에서 INT4를 더 이상 지원하지 않았습니다 wgmma.
다음으로, 프로그래밍 모델이 어떻게 발전했는지, 즉, 고점유에서 단일 점유로의 전환, 명시적 비동기 실행의 증가, 그리고 이러한 디자인이 NVIDIA의 강력한 확장성과 어떤 관련이 있는지에 대해 알아보겠습니다.원문 게시글:
https://semianalysis.com/2025/06/23/nvidia-tensor-core-evolution-from-volta-to-blackwell/
NVIDIA Tensor Core Evolution: From Volta To Blackwell
In our AI Scaling Laws article from late last year, we discussed how multiple stacks of AI scaling laws have continued to drive the AI industry forward, enabling greater than Moore’s Law grow…
semianalysis.com
반응형'TechStock&Review > SemiConduct' 카테고리의 다른 글
메모리 장벽의 확장: HBM의 부상과 로드맵 (25.8.14) (12) 2025.08.14 HBM 개발사: AI 시대를 연 메모리 혁명의 전개 과정 (25.7.4) (7) 2025.07.04 화웨이의 야심작, Ascend 910C 칩 & CloudMatrix384 시스템의 흥미로운점 (2025.6.21) (4) 2025.06.21 중국의 반도체 굴기 - EUV 장비, 독자 개발의 현주소와 미래 (25.6.15) (0) 2025.06.15 반도체 경쟁의 패자, 니콘의 화려한 부활? 제조업의 판도를 바꿀 'NXG 600' 이야기 (25.6.14) (4) 2025.06.14