-
테슬라 AI 칩 세대 별 성능 비교 (25.9.17)TechStock&Review/AI&Cloud&SW 2025. 9. 17. 08:33
핵심요약
AI5 컴퓨터는 AI4보다 3~4배 더 높은 연산 능력을 제공할 것으로 예상합니다. 테슬라는 QC에 실패한 AI5 칩을 사용하여 'AI5 라이트'로 축소하고, HW3 하네스의 전력 예산에 맞춰 언더클럭하여 AI4보다 훨씬 더 높은 성능을 제공할 것으로 예상합니다. HW3 차량에는 AI5 라이트 개조와 새로운 카메라가 장착될 예정입니다. 어떻게 이런 일이 가능할까요?

🟢 HW3
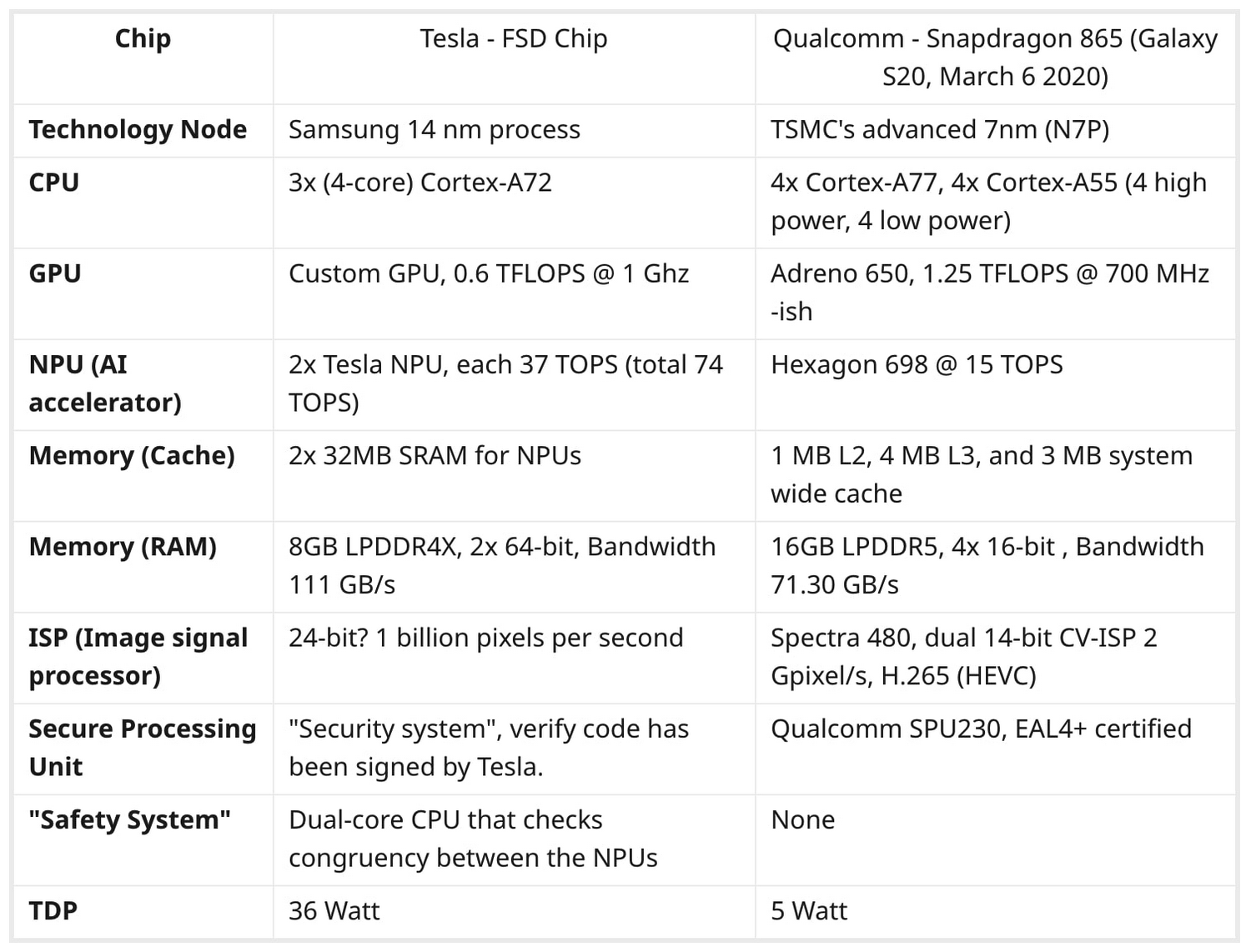
리소그래피: 삼성 14nm 공정.
전력: 최대 90W, 12V에서 7.5A. 배선 하네스에 의해 제한됨.
컴퓨팅: 각각 12개의 CPU 코어를 탑재한 칩 2개, 카메라 입력(ISP) 처리를 위한 Gen1 이미지 신호 프로세서(ISP), 그리고 AI 추론(NPU)을 2.0GHz에서 실행하는 2개의 Tesla Gen1 신경망 처리 장치(NPU)
메모리: NN 연산 중 빠른 온칩 데이터 액세스를 위한 32MB 온칩 SRAM.
또한, 최대 대역폭 68GB/s의 4266MT/s 속도를 제공하는 8GB 온보드 LPDDR4 RAM.
성능: 최대 36 TOPS(초당 조 연산). HW3 컴퓨터는 이러한 칩 2개를 사용하여 총 72 TOPS를 제공.
Nvidia Drive Uses 1000 Watts But Tesla HW3 FSD Chip Uses 36 Watts | NextBigFuture.com
In October 2017 Nvidia and partner development companies announced the Drive PX Pegasus system, based upon two Xavier CPU/GPU devices and two post-Volta
www.nextbigfuture.com
🟢 AI4
리소그래피: 삼성 7nm 공정. HW3보다 최대 두 배 높은 전력 효율을 제공할 것으로 예상됩니다.
전력: 최대 170W로 추정. 16V에서 10.6A. (HW3보다 88% 향상)
컴퓨팅: 각각 2.35GHz에서 20개의 CPU 코어를 탑재한 칩 2개, 향상된 Gen2 ISP(고해상도 카메라 입력용), 2.2GHz에서 작동하는 Tesla Gen2 NPU 3개
메모리: 온칩 SRAM 용량 증가, 더 크고 복잡한 신경망 모델을 지원하기 위해 칩당 64MB 이상으로 추정.
또한, 16GB LPDDR5 RAM(최대 대역폭 88GB/s, 최대 6400MT/s 추정)을 사용합니다.
성능: 최대 약 180 TOPS(초당 연산량)로 추정. AI4 컴퓨터는 이러한 칩 2개를 탑재하여 최대 360 TOPS의 연산량을 제공합니다.

🟢 성능 추정치를 제정신으로 확인하기 위해 간단한 계산을 좀 해 보겠습니다.
코어 수, 코어 아키텍처, 명령어 세트 등 모든 것을 그대로 두고 기존 칩을 7nm 공정으로 축소하고 90W로 언더클럭하면 HW3의 약 두 배 성능(144 TOPS)을 얻을 수 있습니다. 테슬라가 전력 예산을 90W에서 170W로 늘렸다는 것을 알고 있으니, 88%를 더해 보겠습니다. 그러면 270 TOPS가 됩니다. 아키텍처 개선, 코어 8개 추가, NPU 1개 추가, 메모리 및 대역폭 증가를 고려하면 33% 더 향상될 것이라고 예상하는 것도 무리는 아닙니다. 따라서 AI4 의 계산능력은 360 TOPS라는 추정치는 제게는 상당히 타당해 보입니다.🟢 AI5 (대부분 이론적인 내용)
리소그래피: TSMC 3nm N3P 공정. AI4의 전력 효율을 최대 두 배까지 높일 수 있을 것으로 예상됩니다.
전력: AI4와 동일하거나 약간 높을 것으로 예상됩니다. 이 실험에서는 200W(16V에서 12.5A)를 사용할 것입니다. 아마도 AI4에서 개량 가능성에 대한 뼈아픈 교훈을 얻었을 것입니다.
메모리: 아직 정확히 알 수는 없지만, 추측하자면 AI4의 두 배일 것으로 예상됩니다. 32GB LPDD5
(최대 대역폭 115GB/s, 7200MT/s로 작동할 것으로 예상되며, 이는 대부분의 최신 게이밍 노트북과 스마트폰에 사용됩니다).
성능: 코어 수와 같은 구체적인 정보는 아직 없지만, 3nm 노드와 전력 제약을 고려할 때 온라인에서는 AI4보다 3~5배 향상된 것으로 추정됩니다. 이 가정을 적용하면 최대 이론 성능은 칩당 540~900 TOPS이며, 보드당 총 1080~1800 TOPS가 됩니다.
🟢 성능 추정치를 좀 더 정확하게 확인하기 위해 간단한 계산을 좀 더 해 보겠습니다.
다시 한번 AI4 칩부터 시작해서 3nm 공정으로 축소하고 170W로 오버클럭해 보겠습니다. 그러면 AI4보다 성능이 약 두 배 향상된 720 TOPS를 얻을 수 있습니다. 제 가정을 적용해서 전력 예산을 200W(17% 증가)로 늘린다고 가정해 보겠습니다. 그러면 최대 840 TOPS까지 올라갑니다. 엘론 머스크는 AI5에 매우 만족하는 것 같으니, 관대하게 CPU 및 NPU 아키텍처 개선, 더 높은 대역폭과 더 많은 메모리 용량을 위해 45%를 더 추가하겠습니다. 그러면 1218 TOPS가 됩니다. 3~5배의 추정치 중 낮은 쪽, 3.4배 더 빠른 속도에 가까워서 정상성 검증을 통과했습니다. 그렇다면 일론 머스크가 주장 (All in Summit - 25.9.10) 하는 AI4 대비 10배 성능 향상은 어떨까요? 죄송하지만, 제 정상성 검증과는 크게 어긋납니다.
https://www.youtube.com/watch?v=qeZqZBRA-6Q&t=740s
아마도 일론 머스크는 칩이 제약 없이 작동할 때 무엇을 할 수 있는지를 의미했을 것입니다. 전력 소비량이 증가하면 차량의 주행 거리가 줄어든다는 것을 기억하세요. 냉각과 같은 다른 문제도 있습니다. 그래서 저는 이 칩들이 200W를 넘지 않을 것으로 예상합니다.
하지만 Cortex와 같이 무제한 전력 및 냉각 기능을 갖춘 AI 학습 데이터 센터에서는 이 보드를 500W 이상으로 쉽게 끌어올릴 수 있습니다. 이렇게 하면 그가 언급한 10배의 성능 향상에 근접하게 될 것입니다. 죄송하지만, AI5 차량에서 10배의 컴퓨팅 성능을 얻을 수는 없습니다.
아니면 주행 성능이 10배 향상되는 것을 의미했을까요? 더 많은 매개변수를 가진 더 큰 모델을 실행하는 데 있어 제약 요인은 순수 컴퓨팅보다는 메모리 용량과 대역폭이기 때문에 그럴 가능성이 있습니다.🟢 HW3의 한계
테슬라 엔지니어들이 아무리 노력해도 (그리고 아마도 지금도 노력하고 있을 것입니다), HW3의 한계는 FSD NN 모델의 매개변수 크기를 v12 이상으로 늘리기에는 너무 큽니다. 여기서 가장 큰 제약 요인은 RAM 크기일 것입니다. 더 큰 AI 모델을 로드하려면 더 많은 RAM이 필요합니다. RAM에 맞지 않으면 아무리 높은 컴퓨팅 성능을 가지고 있어도 실행되지 않습니다. 마찬가지로, 더 큰 모델을 저장할 수 있는 충분한 저장 공간이 필요한데, HW3 컴퓨터에서는 이 또한 제한될 수 있습니다.
HW3 차량에는 또 다른 한계가 있습니다. 바로 카메라 품질과 해상도입니다. 현재 AI4 카메라 제품군은 훨씬 뛰어납니다.🟢 HW3 개량 - AI5 라이트
추측할 수 있듯이, 그리고 일론 머스크가 공개적으로 언급했듯이, HW3 차량은 "완전 자율주행"(레벨 5 자율주행을 의미)이라는 약속을 이행하기 위해 하드웨어 업그레이드가 필요할 가능성이 높습니다. 이러한 업그레이드는 어떤 모습일까요?
테슬라가 AI4 컴퓨터를 그냥 장착하고 사업을 접을 수 없는 이유는 무엇일까요? 위에서 언급했듯이, 90W의 전력 제한으로 인해 AI4 컴퓨터는 최대 88%의 성능을 잃어 79 TOPS(최고 성능)만 남을 수 있습니다. 최악의 경우이고, 칩의 효율이 전력 소모량 감소로 향상되는 경향이 있으므로 그보다 더 높을 가능성이 높지만, 그렇다고 해도 대형 FSD 모델을 구동하기에는 충분하지 않을 것입니다.
제 생각에는 테슬라가 AI5를 기다리고 있는 것 같습니다. 1218 TOPS로 시작하는 것은 테슬라에게 몇 가지 선택지를 제공합니다. 칩을 90W로 언더클럭하면 최소 536 TOPS를 얻을 수 있습니다. 이는 AI4보다 높은 수치입니다. HW3 차량은 현재 출시된 모든 AI4 모델을 구동할 수 있습니다. 하지만 테슬라는 그보다 좀 더 영리할 수 있습니다. 칩을 제조할 때 실리콘 웨이퍼에 제조 결함이 발생할 수밖에 없습니다. 출시된 칩 중 일부는 품질 관리 테스트를 통과하지 못해 일반적으로 폐기되어야 합니다. 하지만 엔비디아와 같은 회사들은 영리하게 이러한 결함을 활용합니다.
RTX 5080을 예로 들어 보겠습니다. 이 제품은 GB203 칩을 모두 사용합니다. GB203이 RTX 5080 QC 테스트에 실패하더라도, 칩의 일부 기능이 정상 작동하는 한, 결함 영역을 비활성화하여 칩의 일부를 잘라내고 더 느린 RTX 5070 TI라는 이름으로 판매할 수 있습니다. 테슬라 역시 QC 테스트에 실패한 AI5 칩 중 일부를 잘라내 AI5 lite 또는 AI4.5와 같은 이름으로 출시할 수 있습니다.
결과는 어떨까요? 첫째, 테슬라는 버려질 수 있었던 불량 칩을 다시 사용할 수 있습니다. 둘째, 잘라낸 칩을 사용하고 언더클럭킹을 통해 90W의 전력 목표를 달성하면서도 AI4 컴퓨터의 성능을 훨씬 뛰어넘을 수 있습니다.
AI5 lite가 장착된 차량은 별도의 노력 없이 최신 AI4 FSD 모델을 즉시 구동할 수 있습니다. 향후 테슬라는 엔지니어링을 통해 AI5 모델보다 작지만 AI4 모델보다는 큰 AI5 lite 모델을 출시할 수 있습니다. 또 다른 옵션은 전체 AI5 모델을 프레임 속도를 낮추어 실행하는 것입니다. FSD가 최상의 성능을 낼 수 있는 방식입니다. 테슬라 옵션을 제공하며, 좋은 옵션입니다!
🟢카메라이제 남은 문제는 하나, 바로 카메라입니다. 제 생각에는 쉬운 문제입니다. 기존 카메라를 빼고 새 카메라를 끼우면 됩니다. 카메라 배선을 교체하지 않고는 불가능하다는 주장을 들어본 적이 있습니다. 설득력 있는 이유는 아직 듣지 못했습니다. AI4 보드가 HW3 보드와 다른 카메라 커넥터를 사용했기 때문인 것 같습니다. 하지만 이 문제는 쉽게 해결할 수 있습니다. 어댑터를 사용하거나 기존 커넥터를 AI5 Lite 보드에 연결하면 됩니다. 해결되었습니다.
끝까지 읽어주셔서 감사합니다. 즐겁게 읽으셨기를 바랍니다.
참조 원문:
https://x.com/RobGrieves/status/1964867445765910532
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
iPhone 17 A19 칩 AI 추론 성능 벤치마크 (25.9.24) (2) 2025.09.24 Claude - 최근 3가지 이슈에 대한 사후 분석 (25.9.19) (0) 2025.09.19 Oracle 이 AI 컴퓨팅 시장에서 승리하는 방법 (25.8.27) (7) 2025.08.27 Gemini AI의 숨겨진 효율성, 구글은 어떻게 측정하고 개선했을까? (25.8.25) (6) 2025.08.25 H100 vs GB200 NVL72 학습 벤치마크 – 전력, TCO 및 신뢰성 분석, 시간 경과에 따른 소프트웨어 개선 (25.8.22) (6) 2025.08.22