-
H100 vs GB200 NVL72 학습 벤치마크 – 전력, TCO 및 신뢰성 분석, 시간 경과에 따른 소프트웨어 개선 (25.8.22)TechStock&Review/AI&Cloud&SW 2025. 8. 22. 08:31
H100 vs GB200 NVL72 학습 벤치마크 – 전력, TCO 및 신뢰성 분석, 시간 경과에 따른 소프트웨어 개선

프론티어 모델 학습은 GPU와 AI 시스템을 한계에 몰아넣었고, 비용, 효율성, 전력 소비, TCO 대비 성능, 그리고 안정성이 효과적인 학습 논의의 핵심이 되었습니다. Hopper와 Blackwell의 비교는 엔비디아가 생각하는 것만큼 간단하지 않습니다.
이 보고서에서는 2,000개 이상의 H100 GPU에 대한 벤치마크 실행 결과를 제시하고, Model Flops Utilization(MFU), 총 소유 비용(Total Cost of Ownership / TCO), 그리고 100만 토큰당 학습 비용 데이터를 분석합니다. 또한 에너지 사용량에 대해 논의하고, 학습된 각 토큰에 소비된 유틸리티 줄(Joule) 단위의 에너지를 검토하고 이를 미국 가구의 연간 평균 에너지 사용량과 비교하여 사회적 맥락에서 전력 효율을 재구성합니다. 또한 GPU 클러스터를 128대의 H100에서 2,048대로 확장하고 다양한 버전의 Nvidia 소프트웨어에서 이 분석 결과를 보여줍니다.
이 보고서의 후반부에서는 Llama4 400B MoE와 DeepSeek 670B MoE에서 GB200 NVL72 벤치마크 결과를 분석하고, 이 데이터를 H100의 이전 결과와 비교할 것입니다. 신뢰성 문제를 고려했을 때 GB200 NVL72의 달러당 성능 이점이 지속되는지 논의할 것입니다.
낮은 신뢰성과 엔지니어링 시간 손실로 인한 다운타임은 성능 대비 TCO 계산에서 포착할 주요 요인 중 하나입니다. 소프트웨어가 지속적으로 발전하고 신뢰성 문제가 해결됨에 따라 현재 GB200 NVL72에서 대규모 학습을 수행한 사례는 없습니다. 즉, Nvidia의 H100과 H200, 그리고 Google TPU만이 프런티어 규모의 학습을 성공적으로 완료하는 데 사용되고 있습니다. 현재로서는 프런티어 랩과 CSP의 최첨단 운영자조차도 GB200 NVL72에서 대규모 학습을 수행할 수 없습니다.
하지만 모든 새로운 아키텍처는 생태계가 아키텍처를 효과적으로 활용하기 위해 소프트웨어를 늘리는 데 시간이 필요합니다. GB200 NVL72의 증가 속도는 이전 세대보다 약간 느리지만, 큰 차이는 아니며, 연말까지 GB200 NVL72 소프트웨어가 상당히 개선될 것으로 확신합니다. 더 큰 규모의 스케일업을 염두에 두고 공동 설계되는 프런티어 모델 아키텍처와 더불어, 연말까지 GB200 NVL72를 사용하면 상당한 효율성 향상을 기대할 수 있습니다.
신뢰성 측면에서는 엔비디아가 파트너와 더욱 긴밀히 협력하여 신속하게 해결해야 할 상당한 과제가 계속 있겠지만, 우리는 생태계가 이러한 신뢰성 과제를 해결하기 위해 신속하게 리소스를 집결할 것으로 생각합니다.벤치마킹 및 분석 방법론
벤치마킹 및 분석을 위해 NVIDIA DGXC 벤치마킹 팀의 새로운 DGX 클라우드 벤치마킹 스크립트를 활용했습니다. 이 스크립트는 8×400Gbit/s InfiniBand 네트워킹으로 구성된 NVIDIA 내부 H100 EOS 클러스터에서 실행됩니다. 이러한 결과는 Neocloud와 고객 간의 서비스 수준 계약(SLA)을 정의할 때 Neocloud 환경을 비교할 수 있는 공식 참조 번호로 사용됩니다.
클라우드는 NVIDIA에 벤치마크를 제출할 수 있으며, 이러한 EOS 참조 번호를 충족하면 NVIDIA Exemplar Cloud 인증을 획득할 수 있습니다. 곧 출시될 ClusterMAXv2는 서비스 품질을 평가할 때 공급업체의 Exemplar Cloud 자격을 중점적으로 평가할 것입니다. Exemplar Cloud 자격은 공급업체가 대규모 GPU 배포를 위한 다양한 워크로드에 걸쳐 참조 성능 수치를 제공할 수 있음을 입증하는 지표이기 때문입니다.
앞서 언급한 벤치마크는 NeMo Megatron-LM을 사용하여 수행되었지만, GPU의 많은 최종 사용자가 NeMo Megatron-LM에만 의존하지 않는다는 점을 감안하여 DGXC 벤치마킹 팀은 TorchTitan과 같은 기본 Torch DTensor 프레임워크로 적용 범위를 확장할 계획입니다.
앞서 언급한 벤치마크는 NeMo Megatron-LM을 사용하여 수행되었지만, GPU의 많은 최종 사용자가 NeMo Megatron-LM에만 의존하지 않는다는 점을 감안하여 DGXC 벤치마킹 팀은 TorchTitan과 같은 기본 Torch DTensor 프레임워크로 적용 범위를 확장할 계획입니다.
이러한 벤치마크 세트를 만들고 GPU 클라우드 산업을 발전시키는 데 도움이 되는 참조 번호를 제공한 Nvidia DGCX 벤치마킹 팀에 감사드리고 싶습니다!H100 및 GB200 NVL72 Capex, Opex, 총소유비용 분석
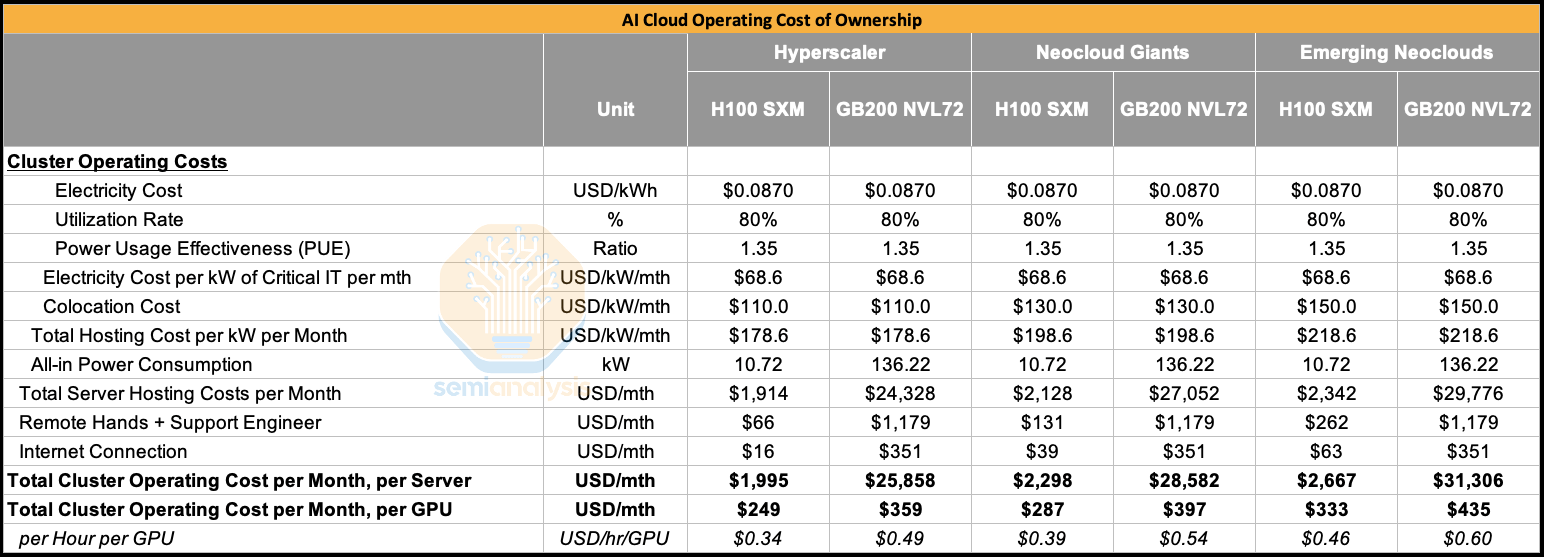
H100 서버 가격은 지난 18개월 동안 다소 하락하여 서버당 약 19만 달러로 나타났습니다. 스토리지, 네트워킹 및 기타 항목을 포함하여 일반적인 하이퍼스케일러의 경우 서버당 총 초기 자본 비용은 최대 25만 달러입니다.
GB200 NVL72의 경우, 일반적인 하이퍼스케일러의 랙 스케일 서버만 해도 310만 달러입니다. 네트워킹, 스토리지 및 기타 항목을 모두 포함하면 랙당 약 390만 달러가 소요됩니다.
하이퍼스케일러부터 네오클라우드 거대 기업, 신흥 네오클라우드까지 세 가지 구매자 유형을 비교했을 때, GB200 NVL72의 GPU당 총 자본 비용은 H100의 GPU당 총 자본 비용의 약 1.6배~1.7배에 달합니다.
역자주: 추론 성능은 Nividia 자체 밴치마크 테스트 결과 GB200 의 추론 성능은 2.4 ~ 2.5배 수준으로 평가됨

TensorRT-LLM 추론 라이브러리를 사용하는 경우 3.4 배의 초당 토큰 아웃풋 제공
https://github.com/NVIDIA/TensorRT-LLM?tab=readme-ov-fileGitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs)
TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and support state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorR...
github.com

DeepSeek-R1, Llama 3.1 405B, and Llama 3.3 70B 모델 추론 성능은 2.4배 ~ 3배 NVIDIA Blackwell Delivers World-Record DeepSeek-R1 Inference Performance | NVIDIA Technical Blog
NVIDIA announced world-record DeepSeek-R1 inference performance at NVIDIA GTC 2025. A single NVIDIA DGX system with eight NVIDIA Blackwell GPUs can achieve over 250 tokens per second per user or a…
developer.nvidia.com

gpt-oss-120B on a DGX system with 8xB200 (NVIDIA) 성능. 낮은 수준의 비용으로 가능 뻐른 출력 속도와 충분한 저지연 성능
https://x.com/NVIDIAAIDev/status/1958318499387892018
https://developer.nvidia.com/blog/delivering-1-5-m-tps-inference-on-nvidia-gb200-nvl72-nvidia-accelerates-openai-gpt-oss-models-from-cloud-to-edge/Delivering 1.5 M TPS Inference on NVIDIA GB200 NVL72, NVIDIA Accelerates OpenAI gpt-oss Models from Cloud to Edge | NVIDIA Techn
NVIDIA and OpenAI began pushing the boundaries of AI with the launch of NVIDIA DGX back in 2016. The collaborative AI innovation continues with the OpenAI gpt-oss-20b and gpt-oss-120b launch.
developer.nvidia.com

출처: semianalysis
두 시스템의 운영 비용(OCO)을 비교한 결과, GB200 NVL72의 GPU당 운영 비용(Opex)은 H100보다 크게 높지 않은 것으로 나타났습니다. 비용 차이는 GB200 NVL72의 GPU당 전체 전력 소비량이 H100보다 높다는 사실에서 비롯됩니다. 이는 GB200 칩이 칩당 1,200W를 소비하는 반면 H100은 700W를 소비한다는 사실에 기인합니다.
출처: semianalysis
총소유비용(TCO)을 산출하기 위해 자본지출(CAPEX)과 운영비용(OPEX)을 모두 고려하면 GB200 NVL72의 TCO는 H100의 TCO보다 약 1.6배 높습니다. 즉, H100 대비 TCO 대비 성능 우위를 확보하려면 GB200 NVL72가 H100보다 최소 1.6배 더 빨라야 합니다.

츨처: semianalysis Nvidia가 ML 커뮤니티를 위해 더 잘할 수 있는 세 가지
벤치마크와 결과를 자세히 살펴보기에 앞서, Nvidia에 대한 세 가지 주요 제안을 제시하겠습니다.
첫째, 엔비디아가 벤치마킹 활동을 확대하고 투명성을 더욱 강화할 것을 권고합니다. 엔비디아가 GPU 클라우드 산업 전반의 기준을 지속적으로 높이기 위해서는 하이퍼스케일러 파트너와 엔비디아 클라우드 파트너(NCP) 모두에 대한 벤치마킹을 수행하고 데이터를 공개적으로 제공해야 합니다. 이를 통해 머신러닝 커뮤니티의 누구든 수천만 달러 또는 수억 달러 규모의 계약을 체결하기 전에 벤치마킹 데이터를 의사 결정 과정에 반영할 수 있습니다.
예를 들어, ClusterMAX 평가 시스템의 첫 번째 릴리스에서 GCP의 기존 a3-mega H100은 O(Llama 70B) 크기 학습에서 평균 MFU보다 10%, 전문가 예비 모델 O(8x7B) 혼합에서 평균 MFU보다 15-20% 낮은 성능을 보였다고 지적했습니다 .
https://semianalysis.com/2025/03/26/the-gpu-cloud-clustermax-rating-system-how-to-rent-gpus/#google-cloudThe GPU Cloud ClusterMAX™ Rating System | How to Rent GPUs
The ClusterMAX™ Rating System and content within this article were prepared independently by SemiAnalysis. No part of SemiAnalysis’s compensation by our clients was, is, or will be directly or indi…
semianalysis.com
따라서 최종 사용자는 시장 평균과 동일한 달러당 성능을 달성하기 위해 GCP에 평균 임대료보다 10-20% 낮은 비용을 지불해야 합니다. Hyperscaler 및 NCP 제공업체 전반에 걸쳐 벤치마크 결과 세트를 공개적으로 사용할 수 있게 되면 공정한 계약 가격 협상이 크게 용이해지고 의사 결정이 가속화될 것입니다. 이를 통해 광범위하고 비용과 시간이 많이 소요되는 개념 증명 실행이 필요 없어져 양측 모두 상당한 시간과 비용을 절약할 수 있습니다.
Nvidia에 대한 두 번째 권고 사항은 많은 사용자가 NeMo-MegatronLM 대신 FSDP2 및 DTensor를 사용하는 네이티브 PyTorch를 선호하기 때문에 벤치마킹 초점을 NeMo-MegatronLM 이상으로 확장해야 한다는 것입니다. NeMo-MegatronLM을 사용하는 한 가지 장점은 언제든지 네이티브 PyTorch에서 아직 사용할 수 없는 많은 성능 기능이 NeMo-MegatronLM에 있다는 것입니다.
최신 기능이 NeMo-Megatron에 먼저 출시되는 것은 타당하지만, 이러한 모든 기능은 최대 한 달 후에 네이티브 PyTorch로 업스트림되어야 합니다. 이를 위해 더 많은 Nvidia 엔지니어가 NeMo에 더 많은 기능을 추가하는 대신 PyTorch 코어 개발에 할당되어야 합니다. Nvidia가 벤치마킹 초점을 PyTorch를 사용하는 실행을 포함하도록 확장하는 것은 이 이니셔티브와도 완벽하게 부합합니다.
엔지니어가 NeMo를 최적화하는 대신 TorchTitan을 최적화해야 합니다. 새로운 NeMo AutoModel 라이브러리는 Megatron-LM 외에도 네이티브 PyTorch FSDP2 백엔드를 지원하므로 바람직한 방향으로 나아가는 한 걸음입니다. 눈에 띄는 부분은 네이티브 PyTorch 3D+ 병렬 처리와 DTensor를 통한 병렬 처리 기능의 부재이며, 많은 사전 학습 기능이 빠져 있고 대부분의 기능은 미세 조정을 위한 것입니다.
세 번째 권고 사항은 엔비디아가 GB200 NVL72 백플레인용 진단 및 디버깅 도구 개발을 지속적으로 가속화해야 한다는 것입니다. 안타깝게도, 광범위한 번인 공정 이후에도 NVLink 구리 백플레인은 여전히 신뢰성이 부족합니다. GB200 NVL72 운영자들은 백플레인 관련 오류 진단 및 디버깅에 사용되는 도구가 뒤떨어져 있고 최적화되지 않았다는 사실 때문에 이 문제가 더욱 악화된다고 호소합니다.
엔비디아는 GB200 NVL72 랙을 고객에게 인도하기 전에 ODM/OEM 파트너 전반에 걸쳐 더욱 엄격한 승인 테스트를 시행함으로써 상황을 개선할 수 있습니다.GPT-3 175B 토큰/초/GPU, 학습 성능 및 전력. 2024년 1월부터 2024년 12월까지 비용 개선
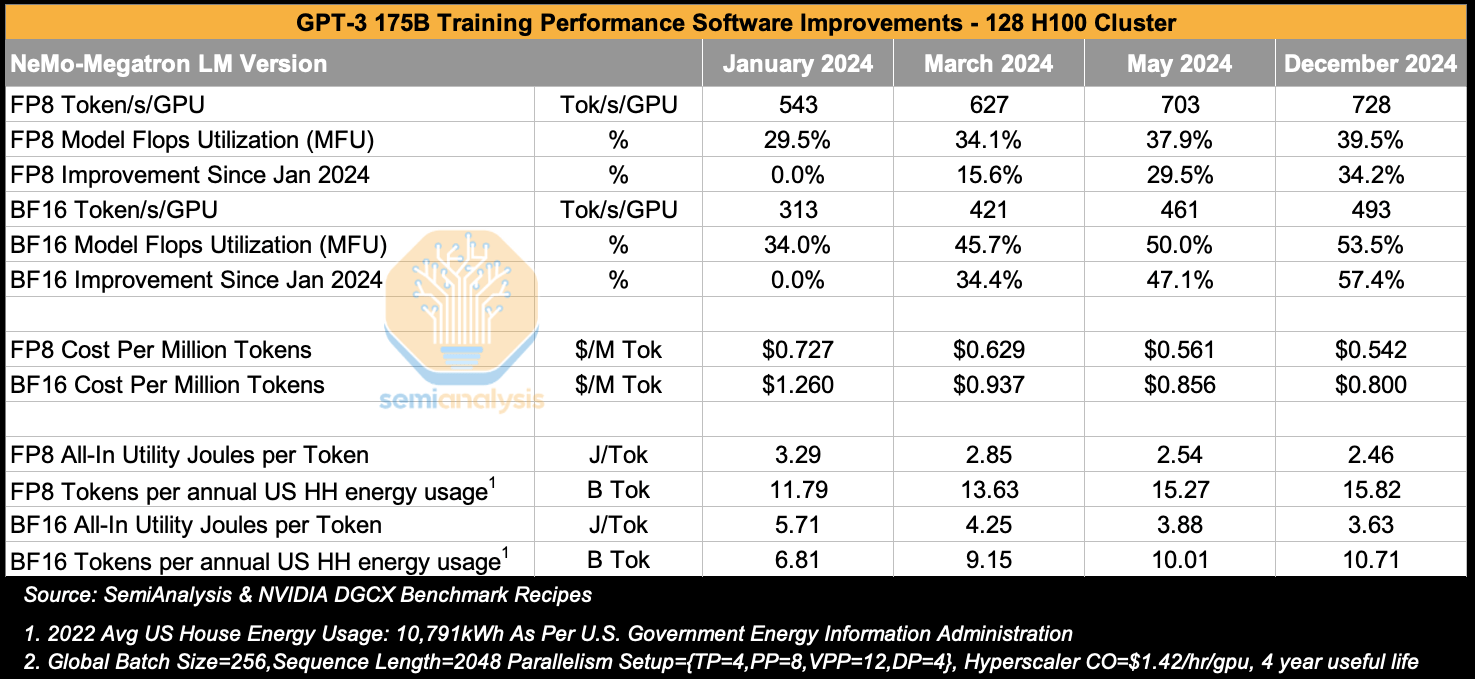
아래 표에는 128개의 H100 클러스터에서 GPT-3 175B를 다양한 시점에 학습시킨 벤치마크 실행 결과가 나와 있습니다. 2024년 1월부터 2024년 12월까지 다양한 NeMo-Megatron LM 버전에 대한 결과를 표시하기로 했습니다. 이는 H100 대량 배치 시작 후 각각 1년과 2년을 나타냅니다.
벤치마크 설정은 4개의 데이터 복제본을 가진 128개의 H100을 사용합니다. 각 데이터 복제본은 32개의 GPU로 구성되며, 각 계층 텐서는 4개의 GPU에 걸쳐 NVLink 도메인을 사용하여 병렬화된 후 파이프라인으로 처리됩니다(즉, TP=4).
H100의 경우 전체 NVLink 도메인 월드 크기인 8개의 GPU에 맞춰 TP=8로 설정하는 것이 최선이라고 생각할 수 있지만, GPT-3 175B 모델의 경우 연산 강도가 더 높으므로 TP=4를 사용하는 것이 더 좋습니다.
자세히 설명하자면, GPT3 175B의 히든 차원은 12,288입니다. 즉, TP=8을 사용하면 K 감소량은 1,536으로 줄어듭니다. 반면, TP=4를 사용하면 히든 차원은 3,072가 됩니다.
벤치마크의 시퀀스 길이는 원래 GPT-3 논문 설정을 따르며 , 2,048개의 시퀀스 길이와 256개의 샘플로 구성된 글로벌 배치 크기를 사용합니다. 즉, 모델은 각 옵티마이저 단계 전에 500k(글로벌 배치 크기 * 시퀀스 길이) 토큰을 인식하게 됩니다.
출처: semianalysis
BF16 MFU를 살펴보면, 12개월 동안 MFU가 34%에서 54%로 상당히 향상되었으며, 이는 CUDA 스택 전반의 소프트웨어 개선만으로 학습 처리량이 57% 향상되었음을 의미합니다. 이러한 향상은 NVIDIA CuDNN/CuBLAS 엔지니어들이 더욱 최적화된 융합 wgmma 커널을 개발하고, NCCL 엔지니어들이 통신에 더 적은 SM을 사용하는 더욱 최적화된 콜렉티브를 개발하는 등 여러 개선 사항의 결과입니다. 결국 중요한 것은 전체 소프트웨어 스택 최적화입니다.
FP8 MFU도 같은 추세를 보이는데, 같은 기간 동안 29.5% MFU에서 39.5% MFU로 개선되어 소프트웨어 향상만으로 처리량이 34% 향상되었습니다.
역자 주: Nvidia 드라이버, CUDA 컴파일러 & 라이브러리 등 SW 생태계 또한 꾸준하게 성능개선과 효율화를 진행하고 있어서 다른 경쟁자와 차별되는 점이다. 다만 빠른 기술 발전으로 인해 SW 버전별 호환성은 과거 인텔 & 마이크로소프트 대비 아쉬운 점으로 지적되고 있다. 따라서 대부분 AI 클라우드 엔지니어들은 Nvidia 에서 HW 모델별로 구성한 Docker 이미지를 적극사용하고 있다.
비용으로 돌아가서, 임대 마진을 제외한 GPU당 비용이 시간당 1.42달러라고 가정하면, FP8에서 GPT-3 175B를 학습하는 비용이 2024년 1월에 학습된 토큰 100만 개당 72센트에서 2024년 12월에는 토큰 100만 개당 54.2센트로 감소한 것을 알 수 있습니다. 즉, 원래 학습 토큰 수인 300B를 사용할 때 GPT-3 175B를 학습하는 비용이 2024년 1월 218,000달러에서 2024년 12월에는 162,000달러로 감소했다는 의미입니다.
마지막으로 GPT-3 학습에 소모되는 전력을 분석합니다. GPU, CPU, 네트워킹, 스토리지 및 기타 구성 요소를 포함한 128개의 H100 클러스터에 대한 총 전력 소모량을 추정합니다. 그런 다음 일반적인 코로케이션 데이터 센터의 전력 사용 효율(PUE)을 곱하여 토큰당 총 전력 소비량(J/Token)을 도출합니다.
고등학교 물리 수업시간을 다시 회상해보면, 줄(Joule)은 1뉴턴의 힘이 물체를 힘의 방향으로 1미터 움직일 때 하는 일과 같은 에너지 단위입니다. 60W 백열전구를 1초 동안 켜면 60J(와트(W)는 초당 에너지 소비량 단위)이 소모되고, 시간당 216kJ의 에너지가 소비됩니다. 에너지 단위를 표현하는 또 다른 방법으로는 와트시(watt-hours) 또는 kilowatt-hours를 사용하는 것이 있는데, 이는 기기의 전력에 사용 시간을 곱한 값입니다.
2022년 미국 가구의 연평균 에너지 소비량은 10,791kWh, 즉 약 38,847,600,000J 이었습니다. 이 10,791kWh를 연간 8,760시간으로 나누면 1년 평균 1,232W의 전력을 소모하게 됩니다. 이는 GB200 GPU 하나가 사용하는 1,200W보다 조금 더 많은 양입니다!
2024년 12월 버전의 NVIDIA 소프트웨어를 사용할 때, 학습된 각 토큰은 FP8의 경우 2.46J, BF16의 경우 3.63J의 에너지를 소비하는 것으로 나타났습니다. 만약 미국 가구의 평균 연간 에너지 소비량과 동일한 에너지 예산이 있다면, FP8 토큰 158억 개를 학습시킬 수 있습니다. 이 계산을 더 확장하여, GPT3 175B에서 3,000억 개의 토큰을 학습시키려면 FP8의 경우 미국 가구 19개에 해당하는 연간 에너지 소비량, BF16의 경우 28개에 해당하는 연간 에너지 소비량이 필요합니다.
GPT-3의 총 학습 비용이 16만 2천 달러이고 19가구의 연간 에너지 소비량은 과도하다고는 할 수 없지만, 미국에서 AI 학습으로 인한 에너지 소비가 급증한 것은 수많은 실험과 실패한 학습 때문인 듯합니다.약한 스케일링 vs 강한 스케일링
강력한 스케일링과 약한 스케일링은 다양한 문제 설정(예: 다양한 배치 크기)에 대한 컴퓨팅 리소스 확장의 성능 향상을 설명합니다.
강력한 확장은 모델 크기와 전역 배치 크기를 동일하게 유지하면서 컴퓨팅 리소스를 확장하는 것을 의미합니다. 이 경우, 컴퓨팅 단계를 병렬화하여 얻을 수 있는 속도 향상을 설명하는 암달의 법칙을 사용하여 강력한 확장의 속도 향상을 정량화할 수 있습니다.
반면, 약한 스케일링은 더 큰 문제를 일정한 시간에 해결하기 위해 컴퓨팅 리소스를 확장하는 것을 의미합니다. AI 학습은 학습 작업에 사용되는 GPU 수를 확장하여 모델 크기와 전역 배치 크기(수렴 정도에 따라 다름)를 확장할 수 있으므로 본질적으로 약한 스케일링을 활용합니다.

출처: SemiAnalysis, Performance and Scalability – SCENET Summer School Llama3 405B 토큰/초/GPU, 백만 토큰당 비용, 토큰당 줄(Joule) vs GPU 수(약한 스케일링)
이 벤치마크에서는 클러스터에서 H100 GPU의 수를 늘릴 때 Llama3 405B의 학습 성능이 어떻게 달라지는지 살펴봅니다. 이는 약한 확장의 예입니다.
아래 표에서 GPU 클러스터 크기를 576개의 H100에서 2,304개의 H100으로 늘렸을 때 FP8 MFU와 BF16 MFU가 모든 크기에 걸쳐 각각 43% MFU와 54% MFU로 맴도는 것을 볼 수 있습니다.
Llama 3 Herd of Models Paper 에 게재된 학습 실행에서 연구진은 16k H100을 사용하여 Llama 3 405B를 학습시켰고, 유사한 병렬
처리 전략을 사용하여 사전 학습에서 41%의 BF16 MFU를 달성했습니다.
위의 사전 학습 실행에서는 8,192의 시퀀스 길이를 사용했지만, 중간 학습 컨텍스트 확장의 경우 각 샘플의 시퀀스 길이는 8,192가 아닌 131,072입니다. 이렇게 길어진 시퀀스 길이는 16개 노드에 걸친 컨텍스트 병렬 처리를 필요로 하며, 링 어텐션에 필요한 추가 통신으로 인해 MFU가 38%로 떨어집니다.

출처: semianalysis
총 학습 비용을 살펴보면, 사전 학습 실행, 즉 15T 토큰에 걸쳐 Llama 3 405B를 학습하는 데 2,304개의 H100 클러스터를 사용하는 BF16을 사용하여 학습할 경우 토큰 백만 개당 1.95달러가 소요됩니다. 이는 사전 학습 단계만으로도 2,910만 달러에 달하며, DeepSeek과 같은 전문가 모델을 혼합하여 학습할 경우 학습 실행당 500만 달러에 불과한 비용보다 훨씬 높습니다.
물론, 이 비용은 단일 최종 성공적인 교육 실행에 드는 비용과 그 최종 단계에 도달하기 위해 필요한 많은 실험 비용, 그리고 연구원 고용 비용을 비롯한 여러 비용을 반영한다는 점을 다시 한번 강조합니다.
Llama3 405B는 총 매개변수 개수 측면에서 GPT3 175B보다 약 2.3배 더 크므로 토큰당 올인 유틸리티 줄(Joule) 은 Llama 3 405B가 토큰당 8.8줄, GPT3 175B가 토큰당 3.6J로 약 2.3배 더 큽니다.
즉, 미국 가구의 평균 연간 소비량과 동일한 에너지로 Meta는 Llama3에서 44억 개의 토큰, BF16에서 405억 개의 토큰을 학습시킬 수 있습니다. 15T 토큰을 사용하여 수렴까지 학습하려면 Meta는 미국 가구 3,400개 전체의 연간 소비량과 동일한 양의 에너지가 필요합니다.Llama3 70B 학습 성능 토큰/초/GPU, 백만 토큰당 비용, 토큰당 줄(Joule) vs GPU 수(약한 스케일링)
다음으로, 다양한 클러스터 크기에 대한 Llama3 70B 학습 성능을 살펴봅니다.
클러스터 크기를 H100 64개에서 H100 2,048개로 늘리면 FP8의 성능이 10% 감소하여 64개 GPU의 38.1%에서 2,048개 GPU의 35.5%로 떨어지는 것을 볼 수 있습니다.
MFU가 이렇게 크게 감소한 것은 매우 흥미롭습니다(백분율 기준 - 낮은 MFU 기반을 고려하면 매우 중요한 부분입니다). 데이터 복제본당 배치 크기는 확장 시에도 변하지 않고 병렬 처리 전략도 변경되지 않기 때문입니다. 모든 실행은 여전히 TP=4, PP=2, 그리고 context parallel=2를 사용합니다. 유일한 실질적인 변화는 데이터 복제본을 추가하는 것입니다.
흥미로운 점은 BF16의 경우 MFU 감소폭이 1-2%에 불과해 훨씬 작다는 것입니다. 64개의 H100에서는 MFU가 54.5%였지만, 2,408개의 GPU에서는 53.7%로 감소했습니다.

출처: semianalysis
Llama3 405B는 Llama3 70B보다 5.7배 더 크며, 다른 고밀도 모델과 마찬가지로 필요한 FLOP 수는 매개변수 수에 따라 선형적으로 증가합니다. 따라서 Llama 3 405B를 학습하는 데 드는 비용은 Llama 3 70B보다 5.7배 더 높아야 합니다. 실제로 약 2,000 H100 스케일에서 Llama3 405B는 BF16을 사용하여 백만 토큰당 비용 측면에서 5.4배 더 비쌉니다.
전력 소비 측면에서, FP8의 경우 H100 2,408개로 학습할 때 토큰당 에너지 소비량이 64개로 학습할 때보다 10% 더 많은 것으로 나타났습니다. FP8에서 H100 64개를 사용하여 Llama 3 70B를 15T 토큰으로 수렴하도록 학습시키는 경우, 미국 가구 440개당 연간 에너지 소비량에 해당하는 에너지만 사용하지만, H100 2,048개로 학습하는 경우 미국 가구 472개당 연간 에너지 소비량에 해당하는 에너지가 필요합니다.시간 경과에 따른 Llama3 8B 학습 성능
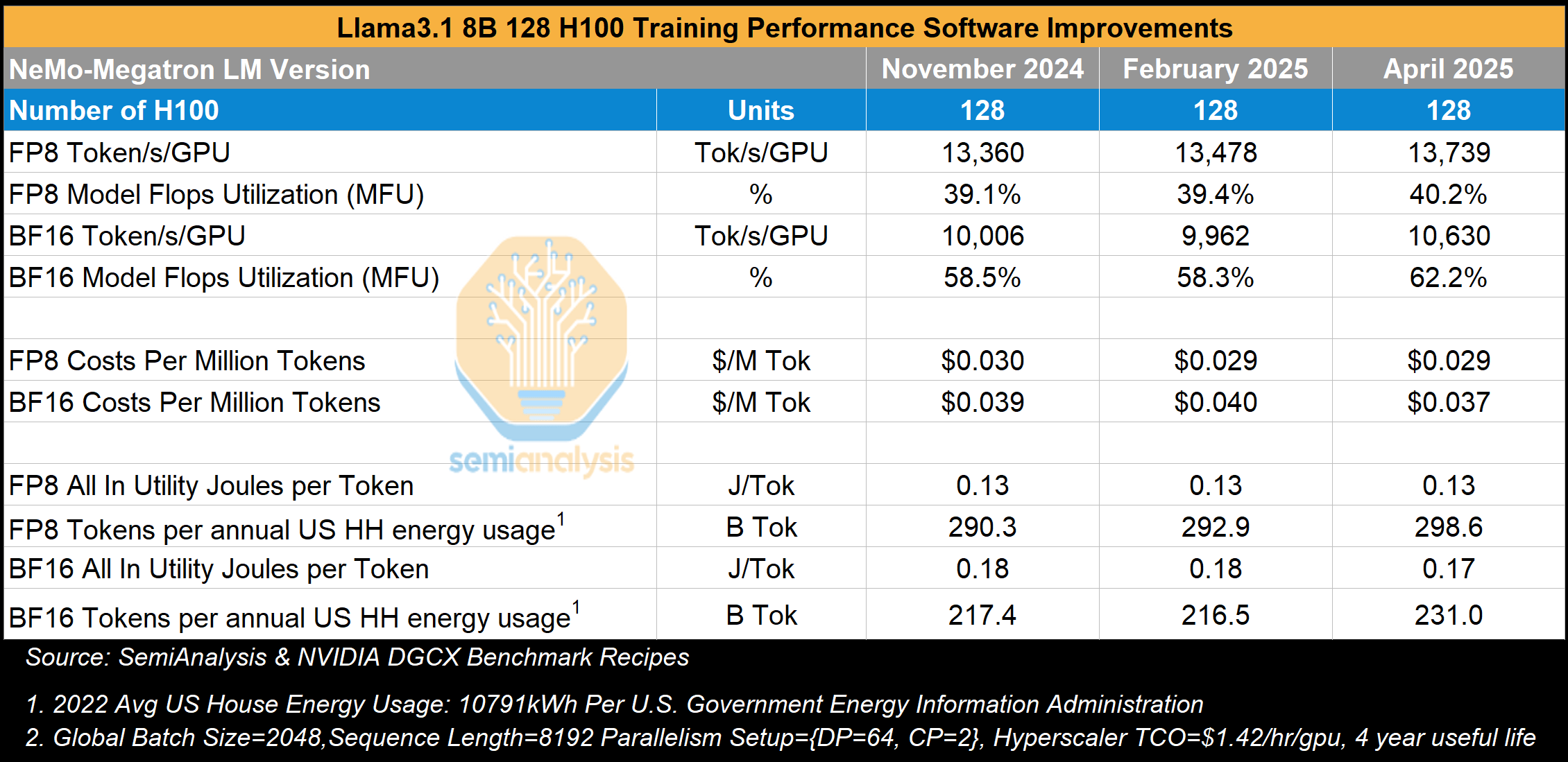
Llama3 405B 및 Llama3 70B와 같은 더 큰 모델은 모두 텐서 병렬 처리, 파이프라인 병렬 처리, 데이터 병렬 처리를 사용하지만, Llama3 8B를 학습할 때는 NVLink 도메인 내 각 GPU 쌍에 대해 8,192 시퀀스 길이에 대한 컨텍스트 병렬 처리만 필요하고, 데이터 병렬 처리를 사용하여 다른 GPU 쌍으로 작업을 분산합니다.
이 분석에서는 스택 전반의 소프트웨어 개선이 학습 성능에 어떤 영향을 미쳤는지 측정하기 위해 시간에 따른 학습 성능도 살펴봅니다. 2024년 11월부터 2025년 4월까지 성능이 소폭 향상되었음을 알 수 있으며, 후자는 Hopper가 대량 배포를 시작한 지 23개월 후입니다.
출처: semianalysis
원문 출처
https://semianalysis.com/2025/08/20/h100-vs-gb200-nvl72-training-benchmarks/
H100 vs GB200 NVL72 Training Benchmarks – Power, TCO, and Reliability Analysis, Software Improvement Over Time
Frontier model training has pushed GPUs and AI systems to their absolute limits, making cost, efficiency, power, performance per TCO, and reliability central to the discussion on effective training…
semianalysis.com
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
Oracle 이 AI 컴퓨팅 시장에서 승리하는 방법 (25.8.27) (7) 2025.08.27 Gemini AI의 숨겨진 효율성, 구글은 어떻게 측정하고 개선했을까? (25.8.25) (6) 2025.08.25 CUTLASS CuTe 라이브러리와 메모리 주소 Layout (25.8.11) (6) 2025.08.11 GPT-5 출시 와 논란 (25.8.10) (10) 2025.08.10 Meta Superintelligence (25.7.18) (7) 2025.07.18