-
Tesla Dojo에서 결함 컴퓨팅 노드 탐지 방법 및 효율화 (25.6.12)TechStock&Review/AI&Cloud&SW 2025. 6. 11. 23:30

핵심요약
- Tesla Dojo 개요: Tesla의 머신러닝 학습 슈퍼컴퓨터 Dojo는 노드 결함으로 인한 Silent Data Corruptions (SDCs) 발생 가능성이 있으며, 이를 방치하면 모델 학습 오류를 초래.
- differential fuzzing 적용: differential fuzzing 기법으로 결함 노드 모니터링을 진행, 무작위 명령어 실행 후 결과 비교로 오류 탐지.
- 효율성 개선: 개별 노드 페이로드 실행과 레지스터 상태 XOR 저장으로 탐지율을 최대 10배 향상.
- Stress 도구 배포: "Stress" 도구로 결함 노드 탐지 성공, Google/Meta와 유사한 결함률 기록, 디자인/소프트웨어 버그도 발견.
Dojo는 Tesla가 설계 및 구축한 ML 학습 슈퍼컴퓨터입니다. 대부분의 다른 최신 마이크로프로세서와 마찬가지로 일부 Dojo 노드는 제조 결함 또는 노화로 인해 발생하는 Silent Data Corruptions (SDC)을 유발할 수 있습니다. 이러한 SDC는 신속하게 감지되지 않으면 고객에게 심각한 부정적인 영향을 미칠 수 있습니다. Dojo의 경우, SDC를 유발하는 단일 노드로 인해 몇주에 걸친 학습이 부정확해지거나 모델 파라미터 최적값 수렴 속도가 느려질 수 있습니다. 모델이 학습된 후에는 이러한 문제를 감지하는 것이 사실상 불가능합니다.
이 글에서는 Dojo 노드의 현장 모니터링에 differential fuzzing을 적용하기 위한 진행 중인 작업을 소개합니다. 기본 알고리즘, 효과적이고/또는 효율적으로 만들기 위한 여러 수정 사항, 그리고 배포의 예비 결과에 대해 설명합니다. 1,000개당 감지된 불량 부품 수는 Google 및 Meta에서 보고한 수치와 유사합니다.
Dojo D1 다이(칩) 하나는 2D 그리드로 연결된 354개의 노드(코어)로 구성됩니다. 25개의 다이가 5x5 그리드(트레이닝 타일)로 유사하게 연결됩니다. 따라서 하나의 트레이닝 타일은 354*25 = 8,850개의 노드로 구성됩니다.
📌 Dojo 칩 구성 레이아웃 구성 요약
354개 노드(코어) 를 2D 그리드로 연결 > Dojo D1 다이 칩 1개
25개 Dojo D1 다이 칩을 5x5 그리드로 연결 > 트레이닝 타일 1개
즉 354*25개의 노드(코어) > 1개 트레이닝 타일
각 노드에는 1.25MB의 SRAM이 있으며, 각 노드의 데이터와 코드가 저장됩니다. 한 노드는 다른 노드의 데이터에 직접 액세스할 수 없으며, 원격 로드 명령을 실행한 후 semaphore 대기를 수행해야 합니다.📌 semaphore wait 란 ??
컴퓨팅에서 semaphore wait 는 세마포어(semaphore)라는 동기화 기법에서 사용하는 연산입니다. 이는 여러 스레드나 프로세스가 공유 자원에 접근할 때 충돌을 피하도록 제어하는 데 사용됩니다. Dojo 클러스터링 컴퓨팅에서는 각 노드간 메모리 접근이 안되기 때문에 다른 노드의 계산이 끝날때까지 동기화를 위해 대기를 해야 합니다. 이를 semaphore wait 라고 합니다.
트레이닝 타일은 트레이닝 타일과 데이터를 주고받을 수 있는 서버 호스트에 연결됩니다. 트레이닝 타일 노드 간 통신 대역폭은 호스트 트레이닝 타일 대역폭보다 훨씬 높습니다. 각 다이는 소수의 비활성화된 노드를 허용할 수 있습니다.
테슬라 AI 팀은 간단한 differential fuzzer로 작업을 시작했습니다. 먼저, 간단한 제약 조건을 가진 무작위 명령어 시퀀스인 페이로드를 생성합니다. 일부 명령어는 제외되고, 특정 SRAM 주소만 쓰기 가능하며, 제어 흐름은 페이로드 내에서 유지되고, 무한 루프나 긴 루프는 발생하지 않습니다.
그런 다음, 페이로드와 작은 러너 코드를 트레이닝 타일의 모든 노드에 분배하고 실행을 시작하여 완료될 때까지 기다린 후 각 노드의 결과를 수집하고, 비교한 후 불일치가 발생하면 오류를 보고합니다.
전체 프로세스는 1초도 채 걸리지 않지만, 노드당 약 1MB의 코드만 실행하는데, 이는 이론적으로 가능한 것보다 약 1000배 느립니다. 대부분의 시간은 호스트-트래이닝 타일 통신에 사용됩니다.
다음 단계는 페이로드 전송 시간과 실행 시간 간의 비율을 줄이는 것이었습니다. 하나의 무작위 페이로드를 생성하여 모든 노드에 배포하는 대신, 각각 0.5MB 명령어를 포함하는 8,850개(354*25개 노드 수, 즉 1개의 트레이닝 타일)의 페이로드를 생성하여 각 노드에 하나씩 업로드했습니다.
그런 다음, 각 노드는 타일의 다른 모든 노드를 순회하며 페이로드를 다운로드하고 실행했습니다. 대부분의 데이터 전송은 타일 내에서 이루어지므로 트레이닝 타일-호스트 대역폭에 의존하지 않습니다. 전체 프로세스는 여전히 몇 초가 걸리지만, 이번에는 0.5MB * 8,850 = 4.4GB의 명령어를 실행합니다. 이 단계에서 첫 번째 결함 노드를 감지하기 시작했습니다.
실행 과정을 설명하기 위해 세 개의 노드로 구성된 시스템을 생각해 보겠습니다. 시작 전에 모든 노드의 SRAM에는 동일한 러너 코드, 세 개의 실행 결과를 저장하는 작은 영역, 세 개의 서로 다른 페이로드(각각 0.5MB), 그리고 0.5MB의 빈 공간이 있습니다.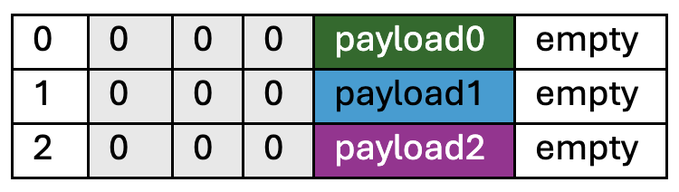
기동 후 각 노드는 노드 0의 SRAM에서 페이로드0을 빈 공간에 복사하고, 이를 실행하여 계산 결과인 R0을 SRAM의 "결과" 섹션에 저장합니다. 결과는 레지스터 파일의 해시값과 SRAM의 일부입니다.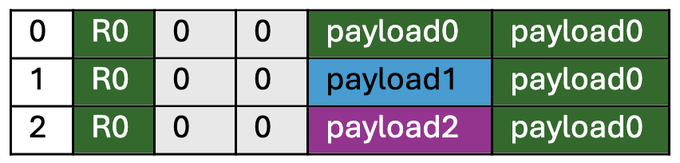
그런 다음 각 노드는 payload1을 복사하고 실행한 다음 payload2를 복사하고 실행합니다.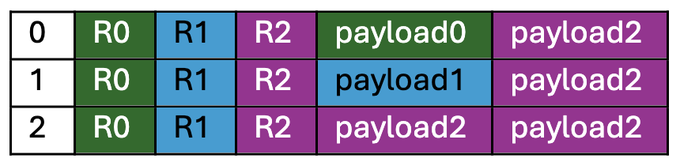
실행이 끝나면 각 노드 SRAM의 "결과" 섹션에는 각 페이로드(R0, R1, R2)의 실행 결과가 저장됩니다. 이 "결과" 섹션은 호스트에 의해 다운로드되어 비교됩니다.
초당 실행되는 명령어 수를 더욱 늘리기 위해 반복 작업 사이에 레지스터와 메모리 상태를 정리하지 않고 각 페이로드를 여러 번 실행합니다. 이를 통해 명령어 시퀀스를 무작위로 지정하는 것 외에도 입력 데이터도 무작위로 지정할 수 있으며, 약간의 속도 저하가 발생합니다.
마지막으로, 알려진 결함에 대한 페이로드의 민감도를 분석했습니다. 다음 명령어 시퀀스가 페이로드의 일부라고 가정해 보겠습니다.
이 경우 결함이 있는 MUL을 놓치게 됩니다. 저희의 해결책은 수백 개의 명령어마다 레지스터 상태를 전용 SRAM 위치에 XOR 연산하는 것입니다. 이렇게 하면 탐지율이 최대 10배까지 향상되지만(여러 알려진 결함 노드에서 측정), 속도 저하도 미미합니다.
Stress라는 이 도구 (tool)은 Dojo 클러스터에 배포되어 정기적인 현장 모니터링을 수행합니다. 이 도구를 통해 Google 및 Meta에서 보고된 결함율과 유사한 결함 노드를 다수 발견했습니다. 저희는 수십 개의 결함 노드에서 탐지 속도를 분석했습니다. 적중 시간(Time-to-Hit)은 정규 분포를 보이는 것으로 보입니다.
대부분의 결함은 첫 번째 적중 시 1GB에서 100GB 사이의 페이로드 명령어를 실행해야 하며(즉, 몇 초에서 몇 분 정도), 일부 결함은 더 빨리 발견될 수 있으며, 일부 결함은 1000GB 이상의 페이로드 명령어를 실행해야 합니다(즉, 몇 시간의 실행 시간).
결함이 발견되면 해당 노드는 비활성화되고, 대부분의 경우 다이는 완전히 작동합니다. 결함이 있는 노드 외에도 Stress는 코너 케이스 설계 버그 하나를 발견했는데(소프트웨어에서 해결할 수 있었습니다), 저수준 소프트웨어에서 여러 버그를 발견했습니다.
향후 작업에는 실리콘 이전 테스트 (pre-silicon test), 사전 배포 초기 테스트 (early pre-deployment test)에 Stress를 적용하고, 거의 완벽한 RTL 커버리지를 확보하고, 현장 모니터링을 확장하고, 시간 경과에 따른 노화의 영향을 측정하는 것이 포함됩니다. 또 다른 잠재적인 변경 사항은 Dojo 노드에서 직접 무작위 명령어 시퀀스를 생성하는 것입니다. 현장 테스트 외에도, 출시 전과 출시 과정에서 Stress를 사용하여 향후 칩의 검증을 진행하고 있습니다.
원문 출처:
https://x.com/Tesla_AI/status/1930686196201714027X의 Tesla AI님(@Tesla_AI)
Detecting defective compute nodes in Tesla Dojo
x.com
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
DeepSeek 출시 128일 이후.. (25.7.8) (8) 2025.07.08 젠슨 황의 2025 GTC 파리 키노트: AI, 양자 컴퓨팅, 로보틱스의 미래 (25.6.14) (3) 2025.06.14 네이버 플레이스, NVIDIA TensorRT-LLM으로 SLM 기반 vertical 서비스 최적화 (25.6.6) (5) 2025.06.06 AMD vs Nvidia 추론 밴치마크: 누가 승자인가? - 백만 토큰 당 성능 & 비용 (25.5.28) (4) 2025.05.28 화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답 (25.5.7) (9) 2025.05.07