-
네이버 플레이스, NVIDIA TensorRT-LLM으로 SLM 기반 vertical 서비스 최적화 (25.6.6)TechStock&Review/AI&Cloud&SW 2025. 6. 6. 12:09

2025년 3월 18일부터 NVIDIA Triton Inference Server는 이제 NVIDIA Dynamo로 바뀌었습니다.📌 NVIDIA Dynamo 란 ??
NVIDIA Dynamo Platform은 2024년 GTC에서 처음 발표된 차세대 AI 인프라 플랫폼으로, 생성형 AI 워크로드(훈련 + 추론 + 배포)를 위한 엔드투엔드 데이터센터 플랫폼.
NVIDIA는 이를 통해 AI 개발자 및 기업들이 모델 훈련부터 추론, 배포까지의 전 과정을 더욱 효율적이고 탄력적으로 수행할 수 있도록 지원하는 서비스 플랫폼.
NVIDIA Triton Inference Server는 NVIDIA Dynamo Platform > NVIDIA Dynamo-Triton 로 이관
https://developer.nvidia.com/dynamo
https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.htmlNAVER는 한국 전역의 수백만 개 업체와 관심 지점에 대한 상세 정보를 제공하는 위치 기반 서비스인 Naver Place를 제공하는 한국의 인기 검색 엔진 기업입니다. 사용자는 다양한 장소를 검색하고, 리뷰를 남기고, 실시간으로 예약 또는 주문을 할 수 있습니다.
NAVER 플레이스 vertical 서비스는 사용성 향상을 위해 소규모 언어 모델(SLM)을 기반으로 하며, 장소, 지도, 여행에 특화되어 있습니다. 이 게시물에서는 NVIDIA와 NAVER가 NVIDIA TensorRT-LLM을 사용하여 SLM 추론 성능을 최적화하여 NVIDIA Triton 추론 서버에서 SLM 기반 vertical 서비스를 구현한 방법에 대한 인사이트를 제공합니다. NAVER가 AI를 활용하는 방식에 대한 자세한 내용은 NAVER Place AI 개발팀 소개를 참조하세요.Small language models for NAVER Place reviews (NAVER Place 리뷰를 위한 소규모 언어 모델)
SLM은 대규모 언어 모델(LLM)에 비해 더 적은 매개변수로 자연어를 이해할 수 있는 AI 모델입니다. SLM은 특정 도메인 작업에 맞춰 적절히 미세 조정될 경우 더 적은 메모리와 연산 능력으로도 효과적으로 작동하는 것으로 알려져 있습니다.
네이버 플레이스는 맞춤형 SLM과 자체 데이터셋을 활용하여 네이버 플레이스 사용자들이 남긴 리뷰를 기반으로 작성된 요약 또는 각 장소의 특징을 설명하는 마이크로리뷰를 제공합니다.
그림 1. 네이버 플레이스 서비스 앱의 리뷰 요약 및 마이크로리뷰 예시. 이미지 제공: 네이버Matching visits with places of interest using an SLM transformer decoder (SLM 변환기 디코더를 사용하여 관심 장소와 방문 일치)
네이버 플레이스는 등록된 장소의 영수증 및 결제 내역을 수집하여 각 장소의 방문 및 리뷰를 네이버 지도에 표시합니다. 이를 위해 네이버 플레이스는 방문 내역과 관심 장소(Places Of Interest: POI)를 매칭하는 시스템을 제공합니다. 또한, 블로그 게시물에서 새로운 POI를 발견하거나 중복 POI를 확인하여 데이터 무결성을 보장하고 서비스 품질을 향상시킵니다.

그림 2. 네이버 플레이스 POI 매칭 서비스 UI는 SLM 변환기 디코더를 통해 활성화됩니다. 이미지 제공: 네이버Adopting NVIDIA TensorRT-LLM for superior inference performance (뛰어난 추론 성능을 위해 NVIDIA TensorRT-LLM 채택)
NVIDIA TensorRT-LLM은 NVIDIA GPU에서 LLM의 추론 성능을 가속화하고 최적화합니다. 처리량을 극대화하기 위해 실시간 배칭을 지원하고, paged KV 캐시 및 chunked 컨텍스트와 같은 자기회귀 모델에 대한 메모리 최적화 방법을 사용하여 메모리 효율성을 향상시킵니다.
NAVER 플레이스는 처리량, 첫 번째 토큰까지의 시간(Time To First Token: TTFT), 출력 토큰당 시간(Time Per Output Token: TPOT) 측면에서 다른 LLM 추론 솔루션보다 우수한 성능을 제공하는 TensorRT-LLM을 채택했습니다. TensorRT-LLM은 다양한 입력 길이 및 출력 토큰 시나리오에서 지속적으로 우수한 성능을 제공합니다.
그림3 은 Qwen 모델을 사용하여 측정한 NVIDIA A100 및 NVIDIA H100 GPU에서 다양한 입력 및 출력 토큰 길이에 대한 인기 있는 대체 오픈소스 LLM 추론 라이브러리와 TensorRT-LLM의 처리량을 비교합니다.
그림 3. 다양한 작동 모드에서 TensorRT-LLM과 널리 사용되는 대체 라이브러리의 QPS 비교. 이미지 제공: NAVER
TensorRT-LLM은 decode-prefill light, prefill heavy, decode heavy, decode-prefill heavy 모든 작업 모드에서 대체 라이브러리보다 우수한 성능을 발휘합니다. 그중 SLM을 사용하는 decode heavy 작업 모드가 가장 강력한 성능을 제공합니다. 또한 TensorRT-LLM은 최신 GPU에 최적화된 커널을 제공하기 때문에 NVIDIA Hopper 아키텍처에서 특히 높은 성능을 발휘합니다.
TensorRT-LLM을 사용하여 성능을 평가하는 방법을 알아보려면 NVIDIA/TensorRT-LLM GitHub 저장소에 있는 성능 개요를 참조하십시오. TensorRT-LLM 엔진을 구축하기 위한 기본 튜닝 기법에 대해 자세히 알아보려면 "TensorRT-LLM 성능 튜닝 모범 사례"를 참조하십시오.
https://github.com/NVIDIA/TensorRT-LLMGitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs)
TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and support state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorR...
github.com
Inference optimization: A trade-off between throughput and latency (추론 최적화: 처리량과 지연 시간 간의 균형)
이 섹션에서는 배치 크기와 페이지 KV 캐시, 진행 중 배치와 같은 메모리 최적화 기술을 사용하여 LLM 추론에서 처리량과 지연 시간의 균형을 맞추는 전략을 살펴봅니다.Batch size (배치 사이즈)
LLM 추론 서버는 처리량을 극대화하기 위해 요청을 일괄 처리합니다. 그러나 이로 인해 지연 시간이 길어집니다. 이러한 상충 관계로 인해 배치 크기가 클수록 처리량은 증가하지만, 응답 시간도 길어질 수 있습니다. 따라서 효율성과 사용자 경험 간의 균형을 신중하게 고려해야 합니다(그림 4). 목표 TTFT(초당 처리량) 및 TPOT(초당 처리량)에 따라 배치 크기를 조정하면 특정 서비스 요구 사항에 더욱 잘 부합하도록 시스템 성능을 최적화할 수 있습니다.
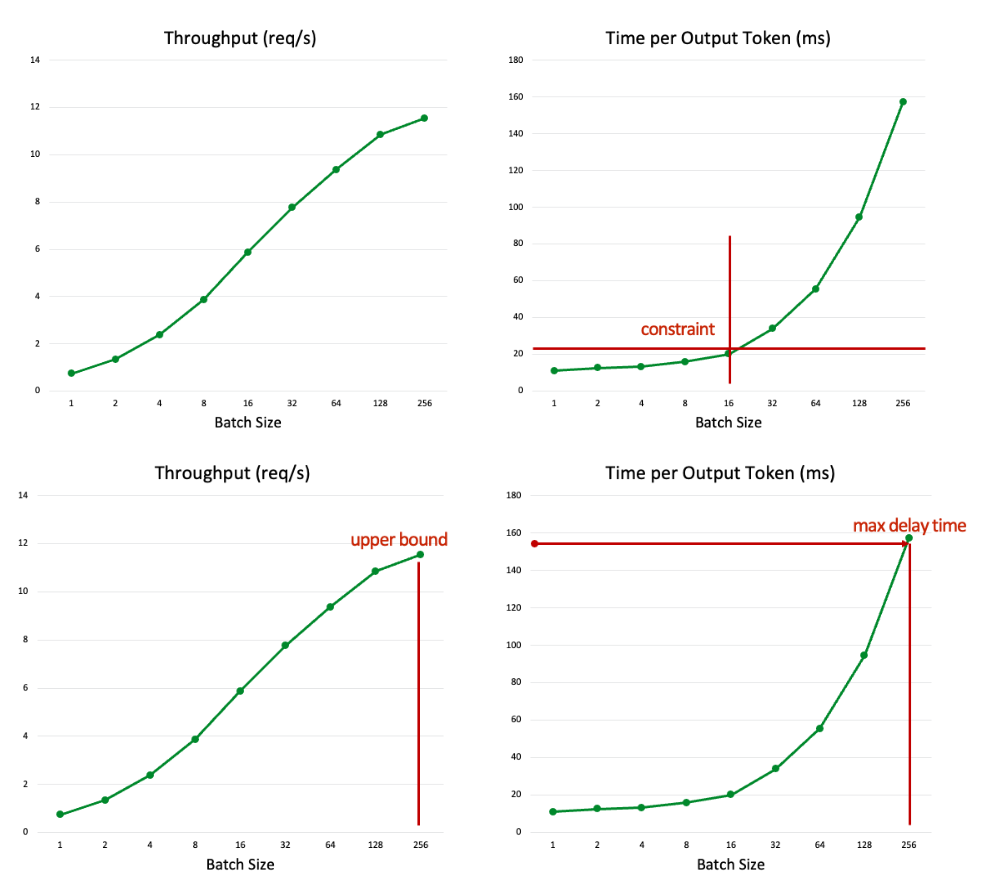
그림 4. 배치 크기에 따른 출력 토큰당 처리량 및 시간. 이미지 제공: NAVER
Paged KV cache and in-flight batching (페이지 KV 캐시 및 비행 중 배칭)
TensorRT-LLM에는 기본적으로 활성화된 paged KV cache 옵션이 포함되어 있어 메모리 효율성을 높이고 상한 배치 크기를 늘려 낮은 지연 시간이 필요한 작업과 높은 처리량을 요구하는 작업을 모두 수용할 수 있습니다. 이 기본 설정은 지연 시간에 민감한 실시간 요청과 높은 처리량을 요구하는 대량 처리 시나리오를 모두 처리할 수 있도록 모델을 원활하게 확장할 수 있도록 하여 더욱 유연하고 강력한 솔루션을 제공합니다.
TensorRT-LLM에서는 처리량을 향상시킬 수 있는 실시간 배칭(In-flight batching) 옵션도 기본적으로 활성화되어 있습니다. 대부분의 작업에서 네이버 팀은 이 두 옵션을 기본값으로 사용합니다.
한 가지 예외는 비교적 작은 모델과 구형 GPU에서 서비스가 매우 낮은 지연 시간을 요구하는 경우입니다. 네이버 플레이스는 매우 낮은 지연 시간이 필요한 특정 사례에서 두 옵션을 끄면 더 나은 성능을 보였습니다. 예를 들어 POI 매칭은 요청을 실시간으로 처리해야 하는 경우로 매우 낮은 지연 시간이 요구되었습니다. 13억 개 파라미터 (1.3B)의 비교적 작은 모델 크기와 비교적 오래된 NVIDIA T4 GPU 아키텍처를 사용하는 이 서비스는 최소 지연 시간을 달성하기 위해 배치 크기 1을 사용하고 배칭 옵션을 꺼야 했습니다.📌 파리미터의 데이터 타입 (FP16, FP8 등) 에 따라 차이는 있지만 Thumb up Rule 에 따라 1억개 파라미터 당 메모리 1G 가 필요하다고 보면 가장 심플하게 계산 할 수 있습니다. 예를들어 1.3B 모델은 1.3G GPU 메모리가 필요하다는 것을 알수 있습니다.
또한, 배치 크기가 1인 13억 개 파라미터 (1.3B)의 작은 모델 크기를 사용했을 때 컴퓨팅 오버헤드보다 페이징 오버헤드가 더 커져 지연 시간이 증가하고 QPS가 감소했습니다. 이 문제를 해결하기 위해 연구팀은 주어진 조건에서 메모리 오버헤드가 덜 문제가 된다는 점을 고려하여 페이지 KV 캐시 대신 연속 KV 캐시를 채택했습니다. 이러한 선택 덕분에 POI 매칭과 같은 사용 사례에 대한 엄격한 실시간 요구 사항을 충족할 수 있었습니다.Precision Paged KV cache Cache blocks Input/output Max batch_size QPS Latency
(in sec)FP16 On 7,110 500/5 1 6.49 0.154 FP16 Off 7,110 500/5 1 8.39 0.119
표 1. 작은 모델과 배치 크기로 기존 GPU 아키텍처를 활용할 때 특정 조건에서 페이지 KV 캐시가 비활성화되면 더 나은 QPS 및 대기 시간
POI 매칭은 실시간 서비스를 위해 최소한의 지연 시간을 필요로 하지만, 백그라운드 매칭에는 높은 처리량을 요구합니다. 이러한 이유로 현재 각 매칭마다 다른 빌드 옵션을 사용하고 있습니다."build_config": { "max_input_len": 512, "max_output_len": 32, "max_batch_size": 1, "max_beam_width": 1, "max_num_tokens": 4096, ... "plugin_config": { ... "paged_kv_cache": false, ... } }"build_config": { "max_input_len": 512, "max_output_len": 32, "max_batch_size": 8, "max_beam_width": 1, "max_num_tokens": 4096, ... "plugin_config": { ... "paged_kv_cache": true, ... } }Inference optimization: Downstream caching (추론 최적화: 다운스트림 캐싱)
이 섹션에서는 캐싱 기술을 활용하여 다운스트림 추론 작업을 간소화하는 최적화 전략을 살펴봅니다. 접두사 캐싱과 응답 캐싱이 중복 계산을 줄이고 전반적인 효율성을 향상시키는 데 어떻게 도움이 되는지 살펴봅니다.
Prefix caching (접두사 캐싱)
다운스트림 작업에서 생성된 프롬프트는 공통 접두사를 가지므로 모든 요청에 대해 전체 프리필을 계산하는 것은 리소스 낭비입니다. 이를 방지하기 위해 TensorRT-LLM은 메모리 사용량과 연산 부하를 크게 줄일 수 있는 접두사 캐싱을 제공합니다. 자세한 내용은 NVIDIA/TensorRT-LLM GitHub 저장소에서 KV 캐시 재사용을 활성화하는 방법을 참조하세요.
이 접근 방식은 TTFT를 상당히 향상시킬 수 있으며, 입력 길이가 길고 시스템 프롬프트가 공유되며 출력 길이가 짧은 작업에 유용할 수 있습니다. 특히 마이크로리뷰 하나에 평균 40번의 다단계 추론이 필요하고 각 단계가 접두사를 공유하기 때문에 마이크로리뷰에 적합합니다.
그러나 캐싱은 가장 최근에 사용된 것(LRU) 전략을 기반으로 하기 때문에 매우 다양한 시스템 프롬프트가 포함된 작업의 경우 캐싱 성능이 저하되고 관리 오버헤드가 증가하여 접두사 캐싱이 효율적으로 작동하지 않을 수 있습니다.Response caching (응답 캐싱)
NVIDIA Triton Inference Server의 기능인 응답 캐싱은 비효율적이고 중복된 추론을 방지하는 데 도움이 될 수 있습니다. Triton은 모델 이름, 모델 버전 및 모델 입력을 포함하는 추론 요청의 해시 값을 사용하여 응답 캐시에 액세스합니다. 응답 캐싱은 다항 샘플링 디코딩과 같이 의도적으로 재추론이 필요한 경우를 제외하고는 원활하게 작동합니다. 실시간으로 제공되는 POI 매칭에서는 초당 4~5회의 캐시 적중이 발생하여 연산 부하가 17% 감소합니다. 자세한 내용은 Triton 응답 캐시 문서를 참조하십시오.
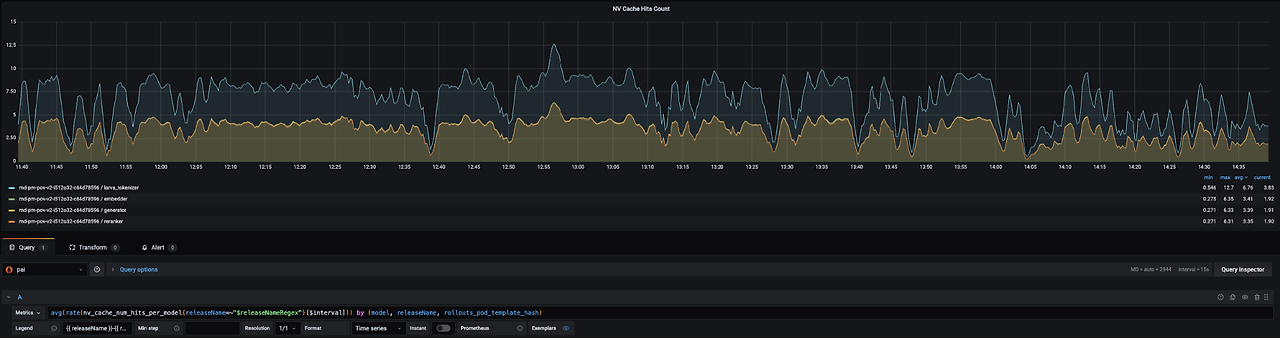
그림 5. POI 매칭 서비스에 대한 응답 캐시 히트. 이미지 제공: NAVER
Serving TensorRT-LLM with Triton (Triton을 사용하여 TensorRT-LLM 제공)
TensorRT-LLM으로 구축된 SLM 엔진은 Triton 추론 서버에서 제공됩니다. Triton은 토큰화, 후처리 또는 다단계 추론 파이프라인을 구성하기 위한 앙상블 모델 및 비즈니스 로직 스크립팅(Business Logic Scripting : BLS)과 같은 기능을 제공합니다. 네이버 플레이스는 특정 사용 사례에 필요한 유연성을 제공하기 때문에 BLS를 선택했습니다. 이 섹션에서는 네이버 플레이스가 Triton BLS의 장점과 사용성을 어떻게 극대화했는지 설명합니다.
Improve usability with well-defined request/response schema (명확하게 정의된 요청/응답 스키마로 사용성 향상)
Triton 모델은 pb_tensor (protobuffer tensor) 형식으로 데이터를 교환합니다. 통신 효율성 및 LLM 추론 최적화를 위해 선택된 BLS 구조에는 전처리 및 후처리 코드가 포함되어 있으며, 이는 pb_tensor 데이터 형식을 NumPy 배열로 변환한 후 다시 pb_tensor로 변환하는 과정을 포함합니다.
이 과정에는 두 가지 어려움이 있습니다. 첫째, 각 모델의 IO 데이터가 검증되지 않으면 런타임에 유효하지 않은 데이터 형식이나 누락된 필수 필드가 발견되어 디버깅이 어려워집니다. 둘째, 전처리와 후처리가 모두 BLS에 통합되어 코드가 더욱 복잡해지고, 모델 간에 호출 종속성이 있는 경우 확장 및 유지 관리가 더욱 어려워집니다.
이러한 어려움은 특히 여러 모델을 연결해야 하는 경우 런타임 오류를 줄이고 코드 관리를 간소화하기 위해 명확하게 정의된 요청/응답 스키마의 필요성을 강조합니다. 또한, 전체 파이프라인에서 데이터 형식을 일관되게 유지하면 디버깅의 어려움을 크게 줄이고 더욱 원활한 통합을 보장합니다. 예를 들어, 그림6 에서 볼 수 있듯이 POI 매칭은 복잡한 파이프라인을 거칩니다.
그림 6. BLS의 POI 매칭 추론 파이프라인. 이미지 제공: NAVER
이러한 어려움을 극복하기 위해 NAVER 플레이스 팀은 다음과 같은 접근 방식을 생각해냈습니다.Standardizing IO schema management (IO 스키마 관리 표준화)
NVIDIA Python 데이터 클래스를 기반으로 Pydantic을 사용하여 IO 스키마를 정의했습니다. 이를 통해 데이터 검증이 더욱 쉬워졌습니다. 이를 통해 모든 Triton 모델의 요청과 응답에서 구조적 일관성을 유지하고 데이터 검증을 향상시킬 수 있습니다. 이 단계에서 명확하게 정의된 스키마를 사용함으로써 개발자는 데이터 문제를 조기에 감지하고 추론 파이프라인 전체에서 일관된 데이터 구조를 유지할 수 있으며, 궁극적으로 디버깅 오버헤드를 줄이고 전반적인 안정성을 향상시킬 수 있습니다.
예를 들어, 다음 코드 예제와 같이 Triton 요청의 입력 데이터 형식을 관리하고 데이터 검증을 수행하기 위해 BlsRequest라는 클래스를 정의했습니다.# NOTE: Because Triton uses pb_tensor and Numpy objects, # it is required to declaratively manage the fields that are not defined as Python default types. # For this, we added tTe json_schema_extra field of Pydantic to explicitly manage data types. class BlsRequest(TritonFieldModel): name: Optional[str] = Field(None, json_schema_extra={'data_type': "TYPE_STRING"}) subname: Optional[str] = Field(None, json_schema_extra={'data_type': "TYPE_STRING"}) biznum: Optional[str] = Field(None, json_schema_extra={'data_type': "TYPE_STRING"}) address: Optional[List[str]] = Field(None, json_schema_extra={'data_type': "TYPE_STRING"}) tel: Optional[List[str]] = Field(None, json_schema_extra={'data_type': "TYPE_STRING"}) @root_validator(pre=True) def check_all_fields_empty(cls, values): if not any(bool(v) for v in values.values()): raise ValidationError("All fields cannot be empty", model=cls.__name__)Modularize IO type conversion by model (모델별 IO 유형 변환 모듈화)
각 모델의 IO 데이터 변환 프로세스를 캡슐화하고, pb_tensor와 Pydantic 간의 변환을 위한 공통 함수를 만들어 기본 Triton Python 모델에 적합하도록 했습니다. 이를 통해 내부 데이터 변환 프로세스에 대한 걱정 없이 일관된 방식으로 모델을 호출할 수 있습니다.
다음 코드 예제는 Pydantic Request 객체를 받아 Triton pb_tensor로 변환한 다음, 모델 추론 결과를 Pydantic Response 객체로 반환하는 함수입니다.def _infer_model(self, request_model, response_model_cls, model_name, request_model, **infer_kwargs): # Converts Pydantic Request to Triton pb_tensors. pb_tensors = self.convert_pydantic_to_pb_tensors(request_model, batch_inference) # Runs model inference. infer_request = pb_utils.InferenceRequest( model_name=model_name, inputs=pb_tensors, requested_output_names=response_model_cls.get_field_names(), **infer_kwargs, ) infer_response = infer_request.exec() # Converts Triton Response(pb_tensors) to Pydantic Response. return self.convert_pb_tensors_to_pydantic(response, response_model_cls)
다음 코드 예제는 _infer_model을 사용하여 모델을 호출합니다. GeneratorRequest 클래스와 GeneratorResponse 클래스만 선언하면 복잡한 데이터 변환이나 모델 호출 과정은 잊을 수 있습니다.def infer_generator(self, request, text_input, max_tokens): response_model_cls = schema.GeneratorResponse request_model = schema.GeneratorRequest(text_input=text_input, max_tokens=max_tokens) return self._infer_model( request=request, model_name="generator_bls", request_model=request_model, response_model_cls=response_model_cls, )Modularizing the BLS business logic and enhance testability (BLS 비즈니스 로직을 모듈화 및 테스트 가능성 향상)
NAVER 팀은 BLS의 비즈니스 로직, 전처리 및 후처리 코드를 다음과 같은 방식으로 모듈화하여 결합도를 낮추었습니다. 이를 통해 코드의 복잡성을 줄이고 테스트 및 유지 관리 용이성을 향상시킬 수 있습니다.
- 전처리 및 후처리 모듈화 및 단위 테스트 도입
* 모델 학습, 전처리 및 후처리 코드의 비즈니스 로직을 모듈화하여 재사용
* Triton 런타임 없이도 Python 런타임에서 독립적으로 실행되도록 테스트 코드를 설계하여 각 모델의 전처리 및 후처리 검증 - BLS의 역할 재정의
* BLS는 모델 호출 및 엔드 투 엔드 테스트만 담당합니다. 이를 통해 시스템의 확장성을 유지하고 새로운 요구 사항이 추가되더라도 BLS 코드에 미치는 영향을 최소화할 수 있습니다. - CI 도입
* 비즈니스 로직, 전처리 및 후처리 코드에 대한 CI 테스트 파이프라인을 구축했습니다. 이를 통해 모델 학습 프로세스 중 변경 사항이 서비스 제공에 영향을 미치지 않는지 신속하게 검증할 수 있습니다. 이러한 테스트를 CI 파이프라인에 통합하면 문제를 조기에 감지하고 신속하게 해결할 수 있어 서비스 제공 프로세스를 방해하지 않고 안정적인 업데이트를 보장할 수 있습니다.
이러한 접근 방식을 통해 데이터 검증, 코드 유지 관리, 개발 생산성 향상이라는 목표를 효과적으로 달성하여 Triton 기반 LLM 서비스 제공 개발의 생산성을 향상시켰습니다.Summary (요약)
네이버 플레이스는 NVIDIA TensorRT-LLM을 활용하여 LLM 엔진을 성공적으로 최적화하고 NVIDIA Triton 추론 서버의 사용성을 개선했습니다. 이러한 최적화를 통해 GPU 활용도를 극대화하여 전반적인 시스템 효율성을 더욱 향상시켰습니다. 이 모든 과정을 통해 여러 SLM 기반 수직 서비스를 최적화하여 네이버 플레이스를 더욱 사용자 친화적으로 만들었습니다. 이러한 경험을 바탕으로 추가적인 수직 모델을 개발하고 서비스에 적용할 예정입니다.
원문:Spotlight: NAVER Place Optimizes SLM-Based Vertical Services with NVIDIA TensorRT-LLM | NVIDIA Technical Blog
NAVER is a popular South Korean search engine company that offers Naver Place, a geo-based service that provides detailed information about millions of businesses and points of interest across Korea.
developer.nvidia.com
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
젠슨 황의 2025 GTC 파리 키노트: AI, 양자 컴퓨팅, 로보틱스의 미래 (25.6.14) (3) 2025.06.14 Tesla Dojo에서 결함 컴퓨팅 노드 탐지 방법 및 효율화 (25.6.12) (2) 2025.06.11 AMD vs Nvidia 추론 밴치마크: 누가 승자인가? - 백만 토큰 당 성능 & 비용 (25.5.28) (4) 2025.05.28 화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답 (25.5.7) (9) 2025.05.07 마이크로소프트 데이터센터 동결 과 전략의 변화 (25.5.1) (0) 2025.05.01 - 전처리 및 후처리 모듈화 및 단위 테스트 도입