-
AMD vs Nvidia 추론 밴치마크: 누가 승자인가? - 백만 토큰 당 성능 & 비용 (25.5.28)TechStock&Review/AI&Cloud&SW 2025. 5. 28. 23:52
AMD vs NVIDIA Inference Benchmark: Who Wins? – Performance & Cost Per Million Tokens (AMD vs Nvidia 추론 밴치마크: 누가 승자인가? - 백만 토큰 당 성능 & 비용 )
AMD의 AI 서버가 엔비디아보다 총소유비용(TCO) 대비 더 나은 추론 성능을 달성할 수 있다는 주장은 오랫동안 이어져 왔습니다. 저희(SemiAnalysis)는 지난 6개월 동안 엔비디아와 AMD가 제공하는 추론 솔루션에 대한 포괄적인 분석 및 벤치마킹을 통해 이러한 주장을 조사하고 검증했습니다. 간단한 답을 얻을 것으로 예상했지만, 결과는 훨씬 더 미묘하고 놀라웠습니다. 채팅 애플리케이션, 문서 처리/검색, 추론 등 작업별로 성능이 다르게 나타납니다.
GPU를 직접 소유하고 운영하는 하이퍼스케일러와 기업의 경우, 일부 워크로드에서는 Nvidia가 가격 대비 성능이 더 뛰어나고(가격 대비 성능), 다른 워크로드에서는 AMD가 가격 대비 성능이 더 뛰어난 것으로 나타났습니다. Neoclouds에서 6개월 미만의 단기 및 중기 렌털을 사용하는 고객의 경우, Nvidia가 항상 가격 대비 성능 면에서 우위를 점합니다. 이는 AMD Neoclouds의 공급 부족으로 인해 MI300X, MI325X의 시장 렌털 가격이 상승했기 때문입니다. 반면, Nvidia GPU의 경우, H100, H200 등을 제공하는 Neoclouds가 수백 개에 달하여 시장 렌털 가격이 경쟁력을 갖추고 있습니다.
참고로, AMD MI355X는 B200의 경쟁 제품으로, MI325X는 H200의 경쟁 제품으로 여겨집니다. 하지만 나중에 자세히 살펴보겠지만, MI325X는 배송이 지연되어 출시 당시 대부분의 고객이 MI325X 대신 B200을 선택했습니다.
저희는 2024년 12월 AMD 분석보고서 발간 이전 시점인 2024년 3분기부터 AMD와 긴밀히 협력해 왔습니다. AMD는 추론 솔루션의 개발자 경험과 품질을 개선하기 위한 조치를 취했으며, CI(Continuous Integration) 자동화 테스트를 추가했습니다. 거의 6개월이 지난 지금, 재평가가 필요하다고 판단했습니다. 테스트 결과, AMD는 지금까지 의미 있는 변화를 이루었지만 여전히 개선의 여지가 많다고 판단합니다. 본 자료의 후반부에서는 저희가 발견한 문제와 CI 적용 부족에 대해 논의할 예정입니다.
https://semianalysis.com/2024/12/22/mi300x-vs-h100-vs-h200-benchmark-part-1-training/
https://semianalysis.com/2025/04/23/amd-2-0-new-sense-of-urgency-mi450x-chance-to-beat-nvidia-nvidias-new-moat/
최종 목표는 공개적으로 이용 가능하고 매일 최신 소프트웨어로 업데이트되는 단일 통합 대시보드를 구축하여, 장문 컨텍스트 문서 작업, 챗봇 작업, 추론 작업, 에이전트 워크플로 등 여러 주요 시나리오에서 여러 주요 모델을 활용하여 다양한 하드웨어 유형에 대한 추론 성능을 보여주는 것입니다. 이 대시보드는 VLLM, SGLang TensorRT LLM, 그리고 future Dynamo 통합을 포함한 여러 주요 추론 스택을 포괄합니다.Key Insights - 주요 시사점
1. 하드웨어를 구매하고 vLLM/SGLang을 사용하는 고객의 경우, 워크로드 및 지연 요구 사항에 따라 때로는 단일 노드 H200 배포가 비용 대비 성능이 더 좋고, 때로는 단일 노드 MI325X가 비용 대비 성능이 더 좋습니다.
2. 대부분의 테스트 시나리오에서 MI300X는 H200과 비교했을 때 절대 성능과 가격 대비 성능이 모두 떨어졌습니다. Llama3 405B와 DeepSeekv3 670B의 경우, MI300X는 절대 성능과 가격 대비 성능 모두에서 H100을 능가했습니다.
3. 단기 및 중기 계약(6개월 미만)으로 GPU를 임대하는 고객의 경우, Nvidia GPU는 항상 더 나은 성능/가격을 제공합니다. 단기 및 중기 계약으로 AMD GPU 임대를 제공하는 공급업체가 소수에 불과하기 때문입니다. 이로 인해 인위적으로 경쟁이 치열해지고 가격이 상승합니다. 반면 엔비디아 생태계에는 단기 및 중기 임대를 제공하는 100개가 넘는 네오클라우드 공급업체가 있습니다. 이러한 풍부한 공급량 덕분에 경쟁이 치열해지고 비용이 절감됩니다.
4. MI325X는 H200의 경쟁 모델로 계획되었지만, 문제는 MI325X의 대량 출하가 HGX B200 출하가 시작된 지 불과 1분기 후인 2025년 2분기에야 시작되었다는 점이었습니다. 이로 인해 대부분의 공급업체가 MI325X보다 HGX B200을 선택하면서 판매 부진이 발생했습니다.
5. MI355X는 B200 출하가 시작된 후 2분기 후인 2025년 후반에 출하가 시작될 예정입니다.
6. B200 및 GB200용 소프트웨어는 아직 완전히 개발되지 않았습니다. 예를 들어, FP8 DeepSeek V3는 Tensor-RT LLM(TRT-LLM), vLLM 또는 SGLang에서 제대로 작동하지 않습니다.
7. B200은 현재 배포 가능한 워크로드와 모델 측면에서 압도적인 우위를 점하고 있습니다. MI325와 H200은 성능 면에서도 비교조차 할 수 없습니다.
8. Nvidia의 TRT-LLM 추론 프레임워크는 개발자 경험이 좋지 않은 것으로 알려져 있습니다. TRT-LLM의 PyTorch 백엔드와 huggingface 모델 문자열에서 vLLM과 유사한 한 줄 CLI serve 명령이 출시된 이후 개선되었지만, 개발자 경험 측면에서는 여전히 vLLM이나 SGLang에 미치지 못합니다.
9. TRT-LLM은 DeepSeek에 대한 전체 지원을 추가하고 사전 구축된 TRT-LLM-serve 컨테이너 이미지를 추가해야 합니다.
10. 서빙 프레임워크는 너무 많은 구성 플래그를 제공하여 설정의 조합 폭발을 야기하여 포괄적인 벤치마킹을 거의 불가능하게 만듭니다. AMD는 이전에 환경 변수를 제거하라는 권고에도 불구하고 환경 변수를 추가하여 상황을 악화시켰습니다. 대부분의 사용자는 각 유형의 워크로드에 대해 매우 심층적인 검토 없이는 어떤 플래그와 변수를 사용해야 할지 알 수 없기 때문에 최고의 성능을 얻지 못합니다.
11. Anush (GPU SW Head, X 계정: @AnushElangovan)와 그의 팀은 ROCm SGLang CI Coverage를 Nvidia의 커버리지와 동등하게 만들기 위해 열심히 노력하고 있지만, 아직 갈 길이 멉니다. 현재 AMD 는 NVIDIA와의 커버리지 동등성이 10%에도 미치지 못합니다.
12. AMD는 탄탄한 재정 자원을 활용하여 내부 클러스터 자원에 대한 지출을 늘려야 합니다. 지난 분기 AMD는 자사주 매입에 7억 4,900만 달러를 지출했지만, 내부 R&D 클러스터 자원에는 약 1,300만 달러만 지출했습니다. 풍부한 R&D 클러스터 자원 부족은 엔비디아에 비해 개발자 경험이 부족하고, AI 소프트웨어 분야에서 AMD가 엔비디아와 지속적으로 격차를 보이는 주요 원인입니다. 상당한 규모의 자사주 매입 중 일부라도 재투자하는 것은 자사주 매입을 통한 단기 주주 만족도를 희생하지 않고도 훨씬 더 나은 장기 주주 수익률을 달성할 수 있다고 생각합니다.
13. CI와 수치적 정확도 커널이 부족해 ROCm에서 다양한 평가에서 CUDA에 비해 모델의 점수가 낮습니다.
AMD와 Nvidia가 저희의 독립적인 분석을 지원해 주셔서 매우 감사드립니다. 이 과정 전반에 걸쳐 두 분의 기술 지원은 매우 소중했습니다. 다양한 버그 리포트를 분류하고 수정해 주시고, 결과를 검토하여 올바른 플래그가 활성화되었는지 확인해 주신 Anush Elangovan(AMD AI Czar)과 그의 팀에도 진심으로 감사드립니다(AMD 관련 버그 리포트가 많습니다). Nvidia 측에서는 Ian Buck의 지원에 감사드리며, Kedar Pandurang Potdar와 Sridhar Ramaswamy에게도 감사드립니다. 버그 리포트를 분류하고 수정해 주시고, 또한 지원해 주신 것에도 감사드립니다.
독립적인 벤치마킹과 분석을 가능하게 하는 개방형 생태계를 지원하고 컴퓨팅을 지원 해준 TensorWave, Nebius, Crusoe, DataCrunch, CoreWeave에 감사드립니다.
출처: SemiAnalysisH100 vs MI300X vs H200 vs MI325X vs B200 vs MI355X
추론의 디코딩 단계는 메모리 대역폭에 따라 달라지는 경향이 있습니다. 따라서 중요한 두 가지 주요 시스템 사양은 HBM 용량과 HBM 대역폭입니다. 단일 MI300 노드(1,536GB HBM 용량)가 H100 노드(640GB HBM 용량)보다 확실한 이점이 있는 것을 알 수 있습니다. H100은 단일 노드에 DeepSeek V3 FP8을 넣을 수도 없습니다. NVIDIA는 2024년 3분기에 H200의 양산을 시작하면서 용량 부족을 해결했습니다. H200은 H100의 80GB HBM 용량에 비해 144GB 메모리를 갖추고 있으며 테스트에서 MI300보다 더 나은 성능을 제공합니다. AMD의 H200에 대한 답변은 MI325X였지만 불행히도 너무 늦게 시장에 출시되어 고객이 대신 B200을 구매하기로 선택했습니다.
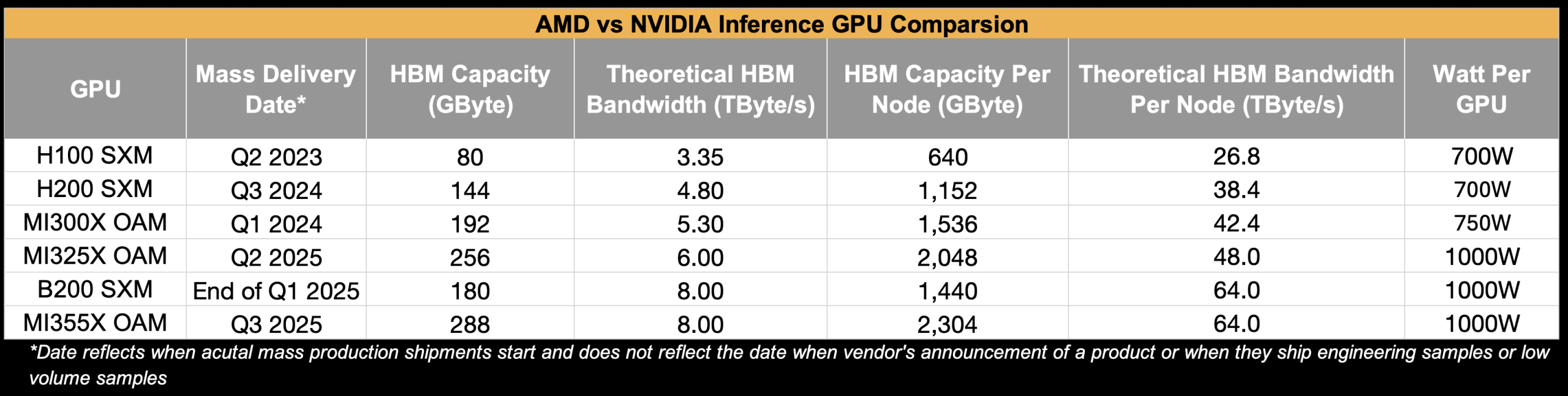
출처: SemiAnalysis
분류 모델 이름 출시
연도아키텍처 공정 메모리
용량메모리 유형 메모리
대역폭TDP
(최대)상호 연결 NVIDIA H100 PCIe 80GB 2023년 3월 Hopper
(GH100)5nm 80GB HBM2e 2.04 TB/s 350W PCIe 5.0 x16 H100 PCIe 96GB 2023년 3월 Hopper
(GH100)5nm 96GB HBM3 3.9 TB/s 700W PCIe 5.0 x16 H100 SXM 80GB 2023년 3월 Hopper
(GH100)5nm 80GB HBM3 3.35 TB/s 700W NVLink (900 GB/s), PCIe 5.0 x16 H200 NVL 2024년 11월 Hopper
(GH100)5nm 141GB HBM3e 4.8 TB/s 600W NVLink Bridge (900 GB/s), PCIe 5.0 x16 H200 SXM 2024년 11월 Hopper
(GH100)5nm 141GB HBM3e 4.8 TB/s 700W NVLink (900 GB/s), PCIe 5.0 x16 B100 2024년 11월 Blackwell (GB102) 5nm
(4NP)192GB HBM3e 8 TB/s 700W PCIe 5.0 x16 B200 SXM 2024년 Blackwell (GB100) 5nm
(4NP)192GB HBM3e 8 TB/s 1000W NVLink (1.8 TB/s), PCIe 5.0 x16 AMD MI250X 2021년 11월 CDNA2 6nm 128GB HBM2e 3.2 TB/s 500W
(560W)Infinity Fabric (400 GB/s), PCIe 4.0 x16 MI300A 2023년 12월 CDNA3 5nm/
6nm128GB HBM3 5.3 TB/s 550W
(760W)Infinity Fabric (128 GB/s), PCIe 5.0 x16 MI300X 2023년 12월 CDNA3 5nm/
6nm192GB HBM3 5.3 TB/s 750W Infinity Fabric, PCIe 5.0 MI325X 2024년 10월 CDNA3 5nm/
6nm256GB HBM3e 6 TB/s 750W Infinity Fabric, PCIe 5.0 출처: 구글 Gemini
https://g.co/gemini/share/6e7bd585ade4
MI325X는 H200과 같은 분기인 2024년 3분기에 출하될 예정이었지만, 지연으로 인해 2025년 2분기에 대량 출하를 시작했습니다. 이로 인해 2025년 1분기부터 고객에게 출시된 HGX x86 B200 SXM과 직접적인 경쟁 관계에 놓이게 되었습니다. 대부분의 고객은 MI325X보다 B200을 구매하기로 결정했으며, 이것이 MI325X가 Meta를 제외하고는 상당한 규모의 하이퍼스케일러 판매량을 기록하지 못한 이유입니다.
명확히 하자면, 생산 지연은 AMD만의 문제가 아닙니다. Nvidia 측에서는 GB200 NVL72가 NVLink 백플레인을 통합하는 문제와 클러스터 운영자에게 제공되는 백플레인 디버깅 도구 부족으로 인해 엄청난 지연에 직면했습니다.Market share of AMD vs Nvidia Datacenter AI GPUs (AMD 대 Nvidia Datacenter AI GPU의 시장 점유율)
AMD의 데이터센터 AI GPU 시장 점유율은 2023년 1분기 이후 꾸준히 증가해 왔습니다. 그러나 2025년 1분기에 엔비디아의 대규모 블랙웰(Blackwell) 출시가 시작되었고, AMD의 블랙웰에 대한 대응 제품은 2025년 3분기에 출시되면서 AMD의 시장 점유율은 2025년 1분기에 하락했습니다. 2025년 2분기에는 AMD의 시장 점유율이 하락할 것으로 예상됩니다. 그러나 올해 말 출시될 AMD의 MI355X와 AMD의 빠른 소프트웨어 개선 속도를 고려할 때, AMD가 올해 말이나 내년 초에 시장 점유율을 어느 정도 회복할 가능성이 있다고 판단합니다.

출처: SemiAnalysis Accelerator Model, AMD Earnings, Nvidia EarningsInference Benchmark Methodology (추론 벤치마트 방법론)
Inference Benchmark Methodology – Online Throughput vs Latency (추론 벤치마크 방법론 – 온라인 처리량 대 지연 시간)
벤치마크를 실제 추론 워크로드에 최대한 근접하게 만들기 위해, 저희의 추론 벤치마킹 방법론은 기존 오프라인 벤치마킹 방식이 아닌, 주어진 구성에 대한 사용자당 엔드투엔드 지연 시간과 온라인 처리량을 비교 분석하는 데 중점을 둡니다. 실제 지연 시간 영향을 고려하지 않고 이상적인 조건에서 처리량(Throughput)을 측정하는 오프라인 벤치마크와 달리, 저희의 접근 방식은 시스템이 동시에 처리하는 사용자 수와 각 사용자가 경험하는 지연 시간(Latency) 간의 상충 관계를 명확하게 포착합니다. 동시 사용자 수를 점진적으로 증가시킴으로써 지연 시간이 어떻게 증가하는지 측정하여 운영 조건과 사용자 경험을 직접적으로 반영하는 현실적인 처리량 지표를 도출할 수 있습니다.
먼저 이해하기 위해 주요 지표와 이러한 지표의 정의에 대해 설명하겠습니다.
처리량(Throughput)은 특정 기간 내에 완료된 작업량을 측정합니다. 예를 들어, 각 GPU가 초당 처리할 수 있는 토큰의 수를 나타냅니다. 처리량이 높을수록 시스템은 더 많은 요청을 동시에 처리할 수 있어 전체 용량, 효율성 및 수익이 증가합니다.
지연 시간(Latency)은 단일 요청을 완료하는 데 걸리는 시간, 즉 요청이 접수된 순간부터 최종 응답이 전달될 때까지 걸리는 시간을 의미합니다. 지연 시간이 짧을수록 응답 속도가 빨라지고 사용자 경험이 향상됩니다. 저희 프레임워크에서는 아래에 정의된 엔드투엔드(E2E) 지연 시간에 중점을 둡니다.
추론 벤치마킹에서 이 두 지표는 상관관계가 있습니다. 동시 요청을 더 많이 추가하여 처리량을 늘리면 일반적으로 개별 사용자가 경험하는 지연 시간이 증가합니다. 시스템이 많은 동시 사용자를 처리할수록 리소스가 더 많이 소모되어 개별 요청의 대기 시간이 길어지기 때문입니다. 반대로, 낮은 지연 시간을 최적화하면 응답 속도를 유지하기 위해 동시에 처리되는 요청 수가 줄어들기 때문에 전체 처리량이 제한되는 경우가 많습니다.
적절한 구성을 선택하려면 처리량과 대기 시간 간의 균형을 이해하는 것이 필수적입니다. 대화형 애플리케이션은 반응성 있는 사용자 경험을 위해 낮은 대기 시간을 우선시하는 반면, 일괄 처리 작업은 요청당 대기 시간이 늘어나더라도 높은 처리량을 우선시합니다.
Time to First Token(TTFT)은 사용자가 요청을 보낸 후 생성된 첫 번째 토큰을 받을 때까지 발생하는 초기 지연 시간을 나타내며, 전체 입력 프롬프트 토큰을 미리 채우는 데 걸리는 시간을 반영합니다.
Time Between Output Tokens(TBOT)은 초기 토큰이 생성된 후 연속적인 토큰 간의 지연 시간을 정량화하여 안정 상태 추론 성능을 포착합니다.
엔드투엔드(E2E) 지연 시간은 E2E 지연 시간 = TTFT + (출력 시퀀스 길이 * TBOT)로 계산됩니다. 이는 요청 처리 시 발생하는 다양한 지연 원인을 모두 반영하기 때문에 사용자 경험을 분석하는 데 선호하는 지표입니다. 이는 GPU당 처리량과 TBOT만 비교하는 일부 분석과는 대조적입니다.
출처: SemiAnalysis
기존의 오프라인 벤치마크는 지연 상호작용과 동시성 효과를 무시하여 현실적인 사용자 조건을 모델링하지 못하고, 결과적으로 실제 운영 환경과 동떨어진 지나치게 낙관적인 처리량 수치를 생성합니다. 오프라인 벤치마크가 처리량 대 배치 크기를 분석할 경우, GPU당 처리량이 동일한 배치 크기에서도 AI 칩마다 지연 시간이 매우 다를 수 있기 때문에 결과가 정확하지 않습니다.
Offline Throughput Benchmark, 출처: Signal65Inference Benchmark Methodology – Model Selection (추론 밴치마크 방법론 - 모델 선택)
실제 운영 워크로드에는 두 가지 주요 모델 범주가 있습니다. Dense architectures 와 sparse Mixture-of-Experts(MoE) 아키텍처입니다.
고밀도 모델 (dense model)의 경우, 중간 규모의 FP16 배포를 대표하는 FP16 정밀도에서 Llama3 70B를 테스트했고, 대규모 고밀도 시나리오를 위해 FP8 정밀도에서 Llama3 405B를 테스트했습니다.
sparse MoE 모델을 벤치마킹하기 위해 FP8 정밀도의 DeepSeekV3 670B를 선택했습니다. 산술 강도, 근사 활성, 총 매개변수 수, 메모리 접근 패턴 측면에서 DeepSeekV3의 모델 아키텍처는 OpenAI의 4o/4.1/o1/o3/o4 모델 아키텍처와 같은 프런티어 폐쇄 모델과 매우 유사합니다. 따라서 DeepSeek은 OpenAI의 내부 모델 아키텍처를 벤치마킹하기에 가장 적합한 대리 모델입니다.Inference Benchmark Methodology – Input/Output Token Lengths (추론 밴치마크 방법론 - 입출력 토큰 길이)
우리는 현실적인 추론 시나리오와 성능 특성을 반영하기 위해 입력 및 출력 토큰 길이의 세 가지 조합을 벤치마킹했습니다.
첫 번째 시나리오는 4K 입력과 1K 출력 토큰 시나리오를 사용합니다. 이는 대규모 프리필 (prefill) 일반 행렬 곱셈(GEMM) 연산을 특징으로 하는 요약 작업을 대표합니다. 이 시나리오는 컴퓨팅에 크게 의존하기 때문에, 컴퓨팅 집약적인 프리필에서 지속적으로 뛰어난 성능을 보이는 NVIDIA GPU와 같은 아키텍처에 유리합니다.
1k 입력과 1k 출력 토큰을 특징으로 하는 두 번째 시나리오는 번역이나 대화 워크로드에 긴밀하게 부합하며 사전 채우기와 디코딩 성능 요구 사항의 균형을 맞춥니다.
마지막으로, 1k 입력 및 4k 출력 토큰 시나리오를 테스트합니다. 이는 많은 추론 토큰을 출력하는 추론 집약적 작업을 대표하며, 이는 일반적으로 성능이 계산량보다는 메모리 대역폭에 의해 제한됨을 의미합니다. 이 세 가지 입출력 길이 시나리오를 모두 평가하면 다양한 추론 워크로드에서 모델 및 하드웨어 성능에 대한 포괄적인 이해를 얻을 수 있습니다.
향후 워크로드가 진화하고 더 많은 데이터가 수집됨에 따라 이러한 비율을 업데이트할 예정입니다.Inference Benchmark Methodology – Inference Engines (추론 밴치마크 방법론 - 추론 엔진)
Llama3 70B 및 405B에 대한 추론 벤치마킹을 위해 vLLM을 주요 추론 엔진으로 선택했습니다. 많은 사용자가 더 나은 성능으로 인해 QWEN으로 전환하고 있지만, Llama3는 여전히 가장 많이 사용되는 모델입니다. vLLM은 이러한 모델에 가장 널리 채택된 추론 프레임워크입니다. 최적화된 성능, 사용 편의성 및 견고성으로 인해 NVIDIA와 AMD 모두에서 보증하고 적극 권장합니다. H200 GPU 플랫폼의 경우, vLLM과 함께 TensorRT-LLM(TRT-LLM)을 추가로 평가했습니다. TensorRT-LLM은 초기 C++ 기반 구현으로 인해 최적이 아닌 사용자 경험을 제공했지만, NVIDIA는 12월에 vLLM 및 SGLang과 기능 및 사용 스타일이 유사한 Python 기반 버전을 출시했습니다. 그러나 최근 테스트 결과, 이 Python 기반 TensorRT-LLM 구현의 전반적인 사용자 경험과 성숙도는 여전히 vLLM에 미치지 못하지만, 지속적인 개선을 통해 이러한 격차를 줄이고 있습니다. 완전성을 위해 두 구현 모두 벤치마킹했습니다.
TRT-LLM은 새로운 파이썬 파이토치(PyTorch) 백엔드, 추론 인스턴스 실행을 위한 간편한 한 줄 명령줄 인터페이스, 그리고 OpenAI 호환 HTTP 서버를 통해 사용이 훨씬 편리해졌습니다. 하지만 여전히 많은 문제가 있습니다. 예를 들어 DeepSeek가 TRT-LLM에서 제대로 작동하지 않고, Nvidia도 아직 파이썬 TRT-LLM-serve 도커 이미지를 공개하지 않아 소스에서 설치하는 데 많은 시간을 낭비하고 있습니다. TRT-LLM 팀에서 DeepSeek V3 구현을 수정하고 TRT-LLM-serve 도커 이미지를 공개할 것을 권고합니다.📌 역자주: 드라이버 지원 및 딥러닝 라이브러리와 연계가 잘되는 Nvidia의 경우에도 드라이버 직접 설치 보다는 도커 이미지 사용을 권장할 정도로 Nvidia 드라이버 설치는 배보다 배꼽이 큰 셋업 절차 중 하나

출처: semianalysis
반면, 훨씬 더 큰 DeepSeek 670B 모델의 경우, 추론 엔진으로 SGLang을 선택했습니다. SGLang은 DeepSeek 670B 배포에 가장 널리 권장되고 채택되는 추론 프레임워크이며, 대규모 모델 크기를 효율적으로 처리하는 능력과 DeepSeek 규모의 추론 워크로드에 내재된 복잡성으로 인해 Nvidia와 AMD로부터 강력한 지지를 받았습니다.Inference Benchmark Methodology – Parallelism Strategies (추론 밴치마크 방법론 - 병렬처리 전략)
벤치마킹 방법론에서는 각 GPU 아키텍처와 테스트 시나리오에서 허용되는 모든 실제 텐서 병렬 처리(Tensor Parallelism / TP) 구성을 체계적으로 평가합니다. 예를 들어, 405B 모델을 벤치마킹할 때 AMD의 MI300X는 TP=4와 TP=8 구성을 모두 지원하는 반면, NVIDIA의 H100은 메모리 및 성능 제약으로 인해 일반적으로 TP=8만 지원합니다. 각 병렬 처리 구성에 대해 처리량과 지연 시간을 측정하여 성능 루프라인을 구축합니다. 이를 통해 주어진 지연 시간 요구 사항에 대해 최대 처리량을 제공하는 최적의 텐서 병렬 처리 전략을 파악합니다. 이러한 포괄적인 접근 방식을 통해 각 GPU 플랫폼 및 모델 시나리오에 맞춰 가장 효율적이고 성능이 뛰어난 병렬 처리 설정을 정확하게 결정할 수 있습니다.
단일 노드 시나리오만 테스트한다는 점에 유의하십시오. 모든 주요 AI 연구소에서 운영 환경에 사용되는 분리형 디코드 및 분리형 프리필 기술이 도입되면서 다중 노드 추론이 사실상의 프런티어 표준이 되었습니다. 안타깝게도 분산 디코드/프리필 기능은 현재 AMD의 오픈 소프트웨어 스택에서는 사용할 수 없으며, Nvidia 시스템에서만 사용할 수 있습니다.Inference Benchmark Methodology – How to Interpret the Data (추론 밴치마크 방법론 - 데이터 해석 방법)
추론 벤치마크 데이터는 달러당 성능과 각 GPU 유형 간의 상대적 성능이라는 관점에서 살펴봐야 합니다. 각 GPU 유형에 대한 각 특정 데이터 포인트의 미세 최적화(예: FP16 모델에 FP8 KV-캐시 사용 또는 최대 배치 토큰 미세 최적화)를 통해 절대적 성능을 지속적으로 개선할 수 있는 방법이 있지만, 이는 전체 곡선이 아닌 해당 데이터 포인트만 최적화합니다. 따라서 독자 여러분께서 달성된 절대적 성능보다는 각 GPU 유형 간의 상대적 성능에 집중하시기를 권장합니다.
또한, H200을 다른 GPU 유형과 비교할 때, TRT-LLM 추론 프레임워크와 vLLM을 사용했을 때의 H200 결과도 함께 제공합니다. TRT-LLM은 vLLM보다 더 강력한 성능을 제공하지만 개발자 경험은 부족합니다. TRT-LLM H200 성능 곡선만 보는 대신 vLLM H200과 TRT-LLM H200 모두의 데이터 포인트를 함께 살펴보시기를 권장합니다.
재현성을 위해 시도한 정확한 vLLM 및 SGLang 버전을 사용하여 벤치마크를 DockerHub 에 공개했습니다.
Throughput Vs Latency Results (처리량 대 지연 시간 결과)
Llama3 70B FP16 Throughput Vs Latency Results (Llama3 70B FP16 처리량 대 지연 시간 결과)

출처: semianalysis
위 그림은 1k 출력/1k 입력 시나리오에서 LLaMA 3 70B를 처리한 결과를 보여주며, 이는 번역 및 채팅 애플리케이션에 적용됩니다. vLLM을 적용한 H100과 H200은 저지연 시나리오에서 두 AMD GPU보다 성능이 우수하지만, MI325X는 더 높은 배치 크기/높은 동시성에서 Nvidia 설정을 간신히 앞지르며 Nvidia 설정을 능가합니다.
텐서 병렬(TP) 크기와 관련하여, 저지연 시나리오에서는 TP=8이 우세한 반면, 더 높은 배치 크기/높은 동시성에서는 TP=2 또는 TP=4가 가장 높은 처리량을 제공합니다. AMD GPU의 경우, TP=1은 최고의 성능을 제공하지 못하며, 높은 동시성에서 MI325X만이 유일한 예외입니다. 이는 높은 동시성에서 통신량이 충분히 커서 HBM에서 데이터를 로드하는 것과 NVLink를 통해 데이터를 통신하는 것의 성능 차이가 나타나기 때문이라고 생각합니다. MI325X의 TP=1 데이터 포인트는 높은 HBM 대역폭의 이점을 보여줍니다.
전반적으로 TRT-LLM을 탑재한 H200(H200-TRT로 표시)이 벤치마크에서 대부분 우위를 점하고 있습니다. 이는 NVIDIA가 자사 하드웨어에 대한 전문성을 바탕으로 성능 튜닝에 많은 노력을 기울인 결과라고 생각합니다.
출처: semianalysis
LLaMA 3 70B에서 추론 관련 워크로드(입력 1k, 출력 4k)의 경우, H100은 다른 모든 GPU보다 성능이 크게 저하되어 GPU당 초당 약 900토큰으로 빠르게 정점에 도달합니다. 반면, MI325X는 다른 모든 GPU보다 정점에 도달하는 시간이 더 길어 약 450초의 지연 시간으로 가장 높은 처리량을 보입니다. 이는 vLLM을 적용한 H200이 낮은 지연 시간 영역에서는 MI325X보다 성능이 뛰어나지만, 높은 동시성 영역에서는 MI325X보다 우수한 이유를 설명합니다. 300초 미만의 지연 시간 시나리오에서는 다음과 같이 성능 순위(최상부터 최악까지)가 명확하게 나타납니다.
1. TensorRT-LLM을 적용한 H200
2. H200
3. MI325X
4. MI300X
5. H100
출처: semianalysis
LLaMA 3 70B를 요약과 유사한 워크로드(입력 4k, 출력 1k)에 사용할 경우, 프리필(prefill)이 많은 워크로드 특성상 일반적으로 Nvidia GPU가 유리합니다. 30초 지연 시간 이후에는 H100이 MI300X를 능가하고, vLLM을 적용한 H200이 MI325X를 앞지르는 것을 확인할 수 있습니다. 그러나 MI325X의 TP=1 구성은 높은 동시성에서 다시 한번 빛을 발하며 vLLM을 적용한 H200보다 우수한 성능을 보여줍니다. TensorRT LLM을 적용한 H200은 20초부터 모든 지점에서 가장 높은 처리량을 제공하며 여전히 독보적인 성능을 보여줍니다.Llama3 405B FP8 Throughput Vs Latency Results (Llama3 405B FP8 처리량 대 지연 시간 결과)
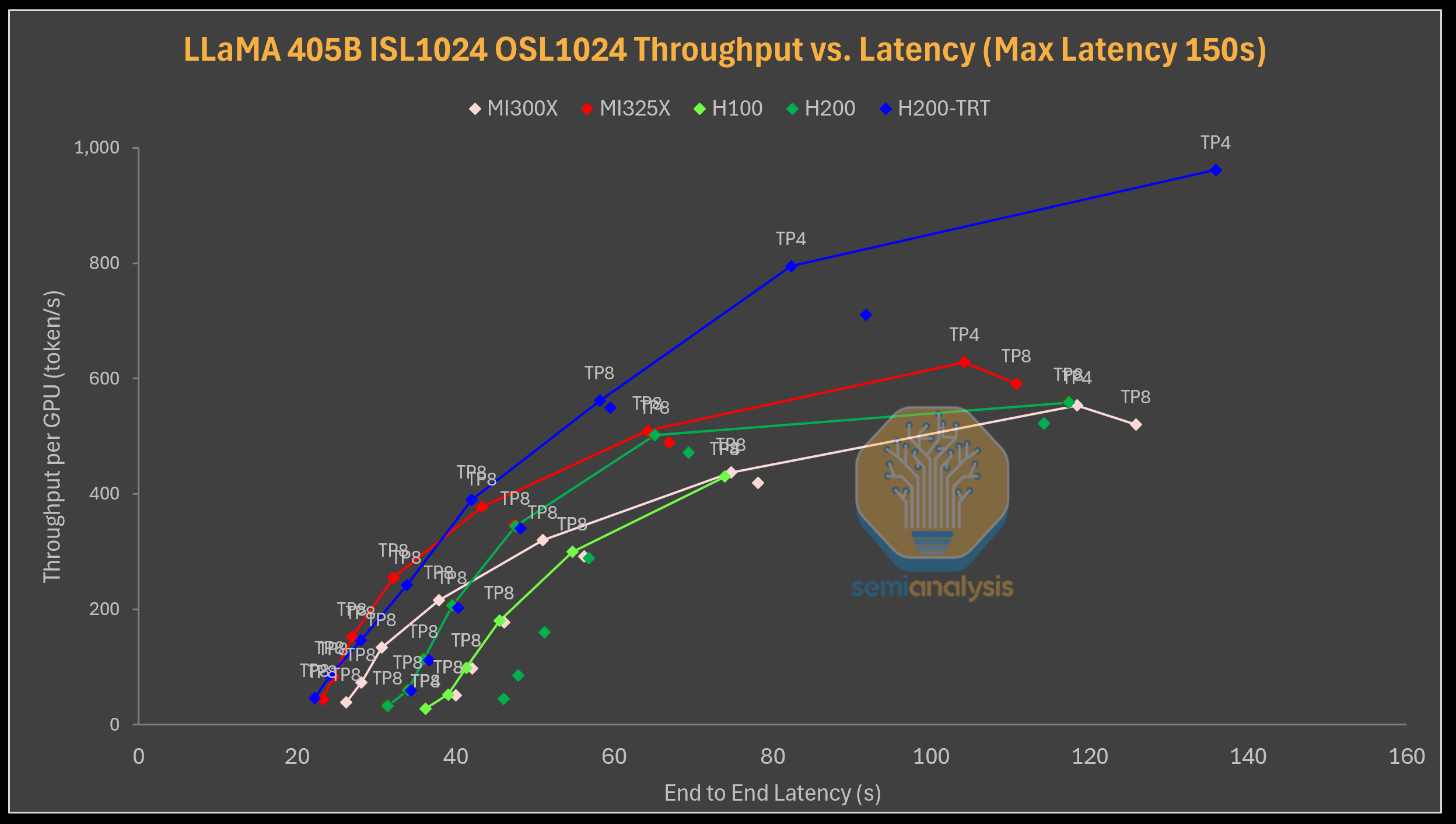
출처: semianalysis
LLaMA 3 405B를 1k 입력 및 1k 출력으로 처리하는 경우, 대부분의 설정이 빠르게 정체되는 것을 확인할 수 있습니다. 40초 미만의 지연 시간에서 MI325X와 MI300X는 H100보다 성능이 뛰어나며, 놀랍게도 vLLM을 사용하는 H200보다 성능이 뛰어납니다. 전반적으로 MI325X는 vLLM을 사용하는 H200뿐만 아니라 MI300X와 H100보다 지속적으로 우수한 성능을 보입니다. H100은 150초 지연 시간 제약 하에서 초당 400개의 토큰 처리에 거의 도달하지 못합니다. 이는 대규모 고밀도 모델을 처리할 때 메모리 대역폭의 중요성을 보여줍니다.
한편, TensorRT LLM을 사용하는 H200은 다시 한번 경쟁 제품들을 압도합니다. 150초 지연 시간 하에서 GPU당 초당 거의 1,000개의 토큰을 처리할 수 있으며, 높은 동시성에서도 정체 현상은 나타나지 않습니다. TensorRT-LLM은 메모리 사용을 더 잘 제어할 수 있기 때문에 더 높은 메모리 활용도를 유지하고 성능을 개선할 수 있다고 생각합니다.
출처: semianalysis
추론 워크로드(1k 입력, 4k 출력)에 LLaMA 3 405B를 적용하면 메모리 바운드의 영향을 확인할 수 있습니다. 예를 들어, H100은 동급 모델 대비 절반에도 못 미치는 처리량을 제공합니다. 또한 vLLM을 적용한 H200은 MI300X보다 성능이 떨어지고, 더 높은 동시성(더 많은 연산을 수행하는)에서만 MI300X를 추월합니다. 그러나 이는 vLLM을 적용한 H200이 MI325X와 경쟁하는 데 도움이 되지 않습니다. MI325는 모든 시나리오에서 H100, MI300X, 그리고 vLLM을 적용한 H200보다 우수한 성능을 보입니다.
TensorRT-LLM을 적용한 H200은 MI325X 대비 유사한 지연 시간에서 최대 1.5배의 처리량을 제공하는 뛰어난 기술력을 다시 한번 보여줍니다. 이는 vLLM이 최적과는 거리가 멀다는 것을 보여주며, vLLM이 TensorRT-LLM을 주요 경쟁자로 간주하는 이유이기도 합니다.
출처: semianalysis
위 그래프를 바탕으로, 대규모 고밀도 모델 처리가 AMD GPU의 강점임을 알 수 있습니다. 특히 MI325X는 모든 지연 시간 시나리오에서 경쟁 제품을 압도하고, MI300X는 약 250초 지연 시간에서 vLLM을 적용한 H200보다 우수한 성능을 보였습니다. 반면, H100은 초당 약 350토큰, vLLM을 적용한 H200은 초당 600토큰으로 정체기를 보였습니다. 다른 경우와 마찬가지로, TensorRT-LLM을 적용한 H200이 50초 지연 시간 이후에는 다른 모든 구성보다 훨씬 뛰어난 성능을 보이며, 압도적인 우위를 점했습니다.
요약과 같은 워크로드를 위한 대규모 고밀도 모델 실행은 워크로드가 사전 채우기에 집중되어 있음에도 불구하고 여전히 메모리 제약을 받으며, 그래프에서 그 효과를 확인할 수 있습니다.
이것이 AMD가 대규모 모델 처리에 MI300X와 MI325X를 선택한 이유입니다.DeepSeekV3 670B FP8 Throughput Vs Latency Results (DeepSeekV3 670B FP8 처리량 대 지연 시간 결과)
DeepSeekv3 670B의 경우 SGLang 추론 프레임워크를 사용하고 H200, MI300, MI325X를 테스트합니다. H100은 DeepseekV3 670B를 단일 노드에 통합할 수 없으므로 테스트하지 않습니다.
번역 및 채팅 애플리케이션 시나리오(1k 입력 1k 출력)의 경우, H200이 모든 지연 시간 수준에서 MI300X보다 우수한 것으로 나타났습니다. MI325X는 25초에서 35초 사이의 짧은 지연 시간 범위에서만 H200과 경쟁합니다. 나머지 지연 시간 범위에서는 H200이 우세합니다. 높은 상호작용성을 요구하는 낮은 지연 시간 환경에서는 모델 복제본당 동시 사용자가 4~16명일 때 H200이 확실한 우위를 보입니다.
출처: semianalysis
추론 테스트 시나리오(입력 1k/출력 4k)에서 H200이 모든 지연 시간 범위에서 MI300보다 우수한 것을 확인할 수 있습니다. 하지만 MI325X는 100초 이상의 지연 시간 범위에서 H200보다 우수합니다. 100초 미만의 지연 시간 범위에서는 H200이 확실한 우위를 보입니다.
출처: semianalysis
요약 작업 시나리오(입력 4k, 출력 1k)를 살펴보면, H200과 MI300X를 비교해도 같은 결과가 나타납니다. H200은 모든 지연 시간 범위에서 MI300X를 압도합니다. MI325X의 경우, 25초의 지연 시간 이후부터 MI325X가 H200을 앞지르기 시작합니다. 온라인에서 지연 시간이 더 짧은 사용 사례에서는 H200이 MI300X와 MI325X를 능가합니다.
출처: semianalysis
대부분 애플리케이션에 필요한 낮음 및 중간 대기 시간에서 H200은 MI300X 및 MI325X보다 우수하므로 OpenAI와 같은 랩에서는 대신 H200을 선택합니다.TCO per Hour Per GPU – Self Owned and Operated Clusters (GPU당 시간당 TCO – 자체 소유 및 운영 클러스터)
Total Cost of Ownership(TCO : 총소유비용)을 고려할 때, AMD와 NVIDIA GPU 중 하나를 선택하려면 자본 지출과 지속적인 운영 비용을 신중하게 평가해야 합니다. AMD의 MI300X 및 MI325X GPU는 일반적으로 NVIDIA의 H100 및 H200 GPU에 비해 시간당 총 비용이 낮습니다.
각 지연 시간 및 모델 테스트 시나리오에 대해, 아래 표와 같이 총소유비용을 고려한 후 AMD와 NVIDIA의 성능을 파악하기 위해 백만 토큰당 비용 단위로 달러당 성능을 계산했습니다. 아래 그래프는 아래 표의 TCO를 기반으로 생성되었으며, 자체 사용을 위해 GPU를 구매하는 고객의 총 비용을 나타냅니다. Neoclouds에서 GPU를 임대하는 고객의 비용 구조를 나타내는 것은 아닙니다.
본 보고서의 마지막 부분에서는 자본지출(CAPEX), 운영지출(OPEX), TCO 계산 구조에 대한 자세한 재무 분석 및 전략적 고려 사항을 자세히 살펴보겠습니다.
출처: semianalysisLlama3 70B FP16 Cost Per Million Tokens

출처: semianalysis
ultra-low latency 추론의 경우 MI325X와 MI300X는 Llama3 70B 채팅 및 번역 작업(1k 입력/1k 출력)에서 달러당 성능 면에서 다른 모든 GPU를 능가합니다.
출처: semianalysis
좀 더 넓은 관점에서 지연 시간을 고려해 보면, 지연 시간이 20초를 초과하면 가격 차이가 나타나기 시작합니다. AMD GPU는 vLLM을 탑재한 H100과 H200보다 비용 효율성이 떨어지지만, 지연 시간이 증가함에 따라 MI325X는 높은 동시성에서 뛰어난 성능을 발휘하기 때문에 H200보다 경제적입니다.
출처: semianalysis
추론 시나리오(1k 입력, 4k 출력)로 돌아가서, 저지연 애플리케이션부터 시작하면 TCO당 성능 면에서 MI325X와 MI300X가 더 우수하다는 것을 알 수 있습니다.
출처: semianalysis
이 분석을 더 긴 지연 시간으로 확장해 보면, H100에서 LLaMA 3 70B를 제공하는 것이 성능이 약해 비용 효율성이 가장 낮음을 알 수 있습니다. MI300X와 MI325X는 vLLM과 TensorRT LLM을 사용하는 H200보다 가격이 비싸지만, 지연 시간이 길어질수록 경쟁력이 높아집니다. 흥미롭게도 MI300X에서 제공하는 비용은 MI325X에서 제공하는 비용과 거의 동일하여, 이 경우 MI325X의 성능 향상이 가격 인상을 정당화하지 못함을 알 수 있습니다.
출처: semianalysis
출처: semianalysis
요약 워크로드에서도 유사한 추세가 나타납니다. AMD GPU는 저지연 영역에서 가장 비용 효율적이며, H100은 다른 모든 설정보다 뒤처집니다. vLLM과 TensorRT를 사용하는 H200은 중간 지연 영역에서 가장 경제적이지만, MI325X의 백만 토큰당 비용은 vLLM을 사용하는 H200보다 낮아져 TensorRT를 사용하는 H200과 비슷해집니다.Llama3 405B FP8 Cost Per Million Tokens

출처: semianalysis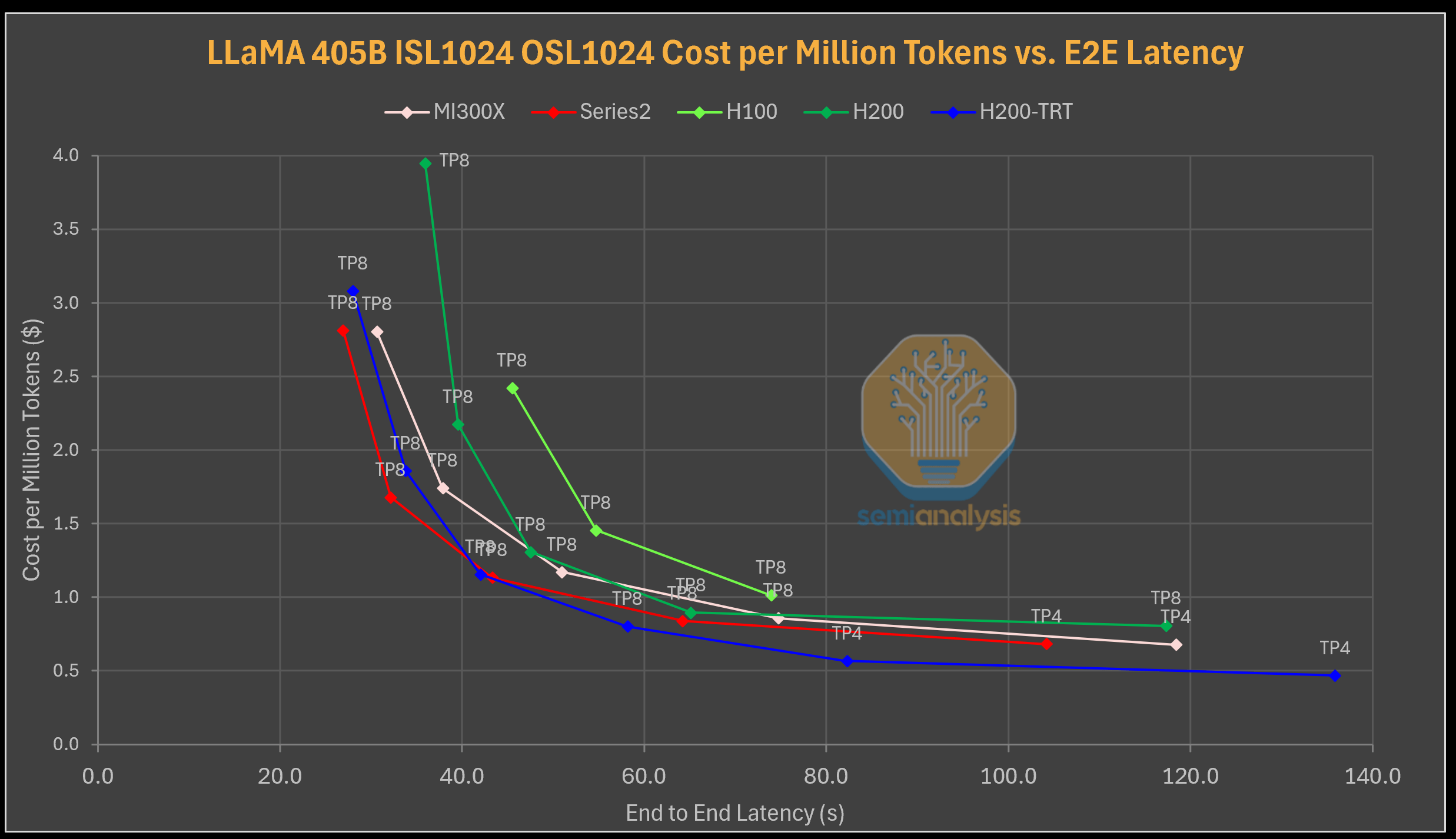
출처: semianalysis
채팅 및 번역 시나리오(1k 입력, 1k 출력, AMD GPU는 가격이 저렴하고 대규모 고밀도 모델을 제공하는 데 성능이 더 뛰어나므로 비용 효율성 차이가 더 분명해집니다. MI325X는 vLLM 및 H100을 사용하는 H200보다 지속적으로 비용이 낮고 MI300X도 vLLM을 사용하는 H200과 동등함을 알 수 있습니다. 그러나 TensorRT LLM을 사용하는 H200은 60초 지연 시간 이후에도 뛰어난 성능으로 다시 한번 승리합니다.
출처: semianalysis
추론 작업(입력 1k, 출력 4k)을 위한 초저지연 405B의 경우, MI325X와 MI300X가 H200 vLLM과 H100 vLLM보다 뛰어나다는 것은 의심의 여지가 없습니다. 심지어 TRT-LLM에서는 H200보다 뛰어납니다!
출처: semianalysis
추론 작업 시나리오에서 더 긴 지연 시간을 고려하면, 이전의 모든 고밀도 모델 제공 구성과 마찬가지로 MI300X와 MI325X는 vLLM을 탑재한 H100과 H200보다 가격 효율성이 더 높습니다. 단, TensorRT LLM을 탑재한 H200이 가장 비용 효율적입니다. H200과 AMD GPU의 가격 차이보다 성능 향상이 크기 때문입니다.
출처: semianalysis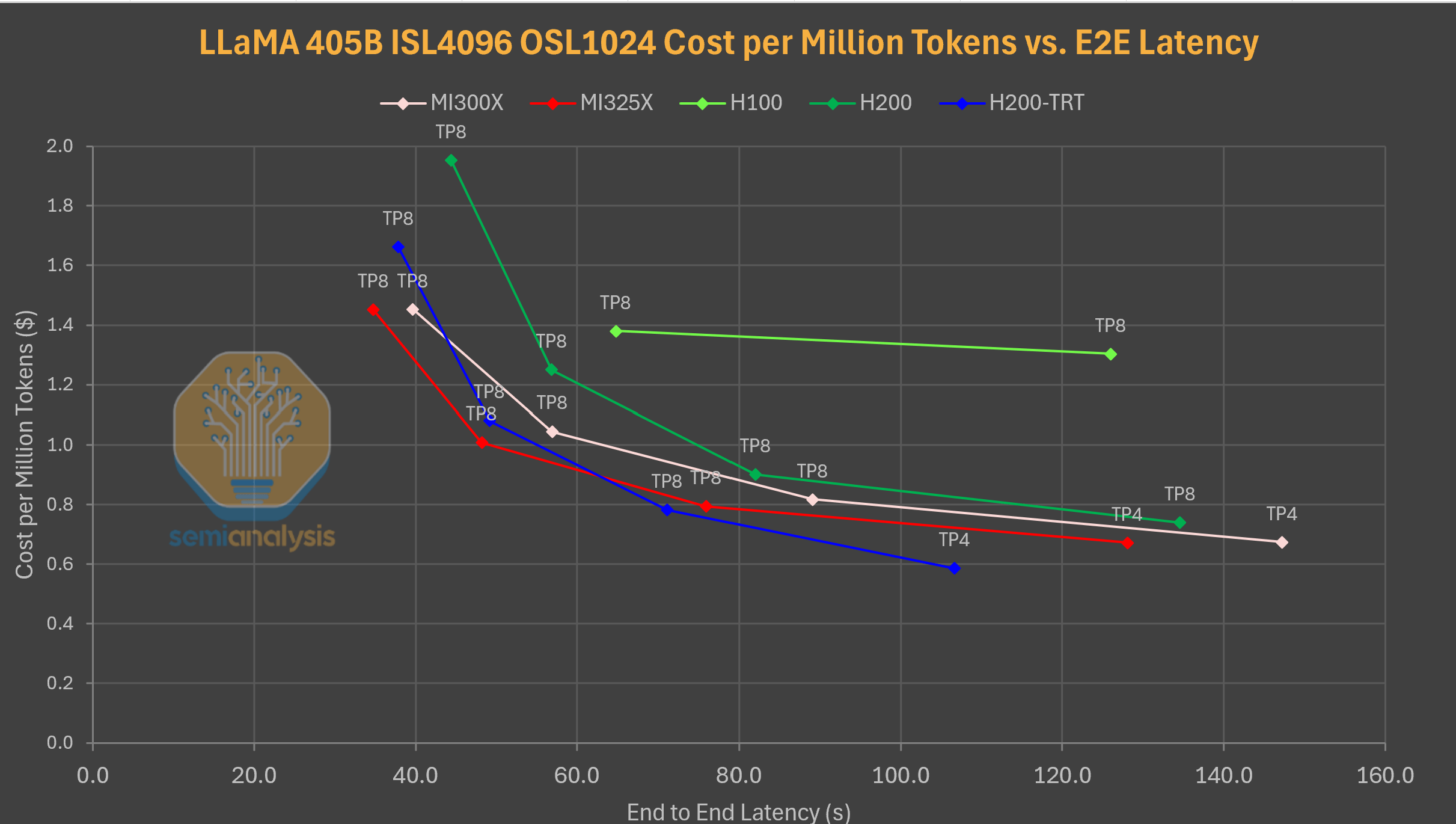
출처: semianalysis
요약 시나리오(4k 입력, 1k 출력)에서는 MI325X가 확실한 승자입니다. 낮은 지연 시간에서 MI325X는 TensorRT LLM을 탑재한 H200을 포함한 모든 설정보다 우수한 성능을 보이며, 높은 지연 시간에서도 경쟁력을 유지합니다. MI300X는 높은 지연 시간에서 vLLM을 탑재한 H200보다 비용 효율성이 뛰어나며, 낮은 지연 시간에서는 TensorRT LLM을 탑재한 H200과 비슷한 성능을 보입니다. 놀랍게도 이번에는 TensorRT LLM을 탑재한 H200이 성능이 더 우수함에도 불구하고 가격 경쟁력이 부족합니다.DeepSeekv3 670B FP8 Cost Per Million Tokens

출처: semianalysis
채팅 및 번역 작업(입력 1k, 출력 1k)의 경우, MI300X의 성능/가격은 H200과 비교했을 때 경쟁력이 부족하지만, MI325X는 지연 시간이 25초에서 40초로 H200과 비슷한 수준이지만 큰 차이는 없습니다. 가격 대비 성능 향상은 ROCm으로 전환하고 도입하는 수고를 감수할 만큼 크지 않습니다.
출처: semianalysis
추론 작업(입력 1k, 출력 4k)의 경우, 100초 지연 시간 이후에는 MI325X가 H200보다 성능이 향상되어 H200보다 $당 최대 20% 더 우수한 성능을 보입니다. 하지만 지연 시간이 짧고 상호작용성이 중간에서 높은 경우(즉, 지연 시간이 100초 미만)에는 H200이 여전히 압도적으로 우위를 점합니다. 추론 작업에서 MI300X는 $당 성능 측면에서 H200에 비해 경쟁력이 없습니다.
출처: semianalysis
요약 작업(입력 4k, 출력 1k)의 경우, 가격 대비 성능 측면에서 낮은 지연 시간과 높은 상호 작용성을 갖춘 H200이 우위를 점하는 것을 알 수 있습니다.
출처: semianalysis
요약 작업에 집중하면서 중간에서 높은 지연 시간을 살펴보면 MI300X가 H200과 경쟁력이 있고 MI325X는 H200보다 가격 대비 20~30% 더 나은 성능을 보입니다.Why does nobody use AMD besides Hyperscalers? (왜 Hyperscalers 외에는 아무도 AMD를 사용하지 않습니까?)
위의 TCO당 성능 분석은 직접 구매 시나리오에 초점을 맞춥니다. 즉, 대규모 하이퍼스케일러 또는 기업이 Neoclouds에서 GPU를 임대하는 대신 하드웨어를 직접 구매하는 상황에서 AMD GPU와 NVIDIA GPU를 구매하는 상황을 비교합니다.
GPU 임대의 경우 비용은 매우 다릅니다. AMD는 제한된 공급량과 시장 경쟁 감소로 인해 NVIDIA에 비해 상당한 경쟁적 열세에 직면해 있습니다.
현재 100개 이상의 Neocloud 공급업체가 NVIDIA GPU의 단기(6개월 미만) 임대 서비스를 제공하여 가격 경쟁을 유도하고 임대 비용을 절감하고 있습니다. 반면, 유사한 단기 AMD GPU 임대 서비스를 제공하는 공급업체는 극소수에 불과합니다.
임대 시장의 이러한 희소성은 AMD GPU 임대 가격을 인위적으로 높게 책정하여 AMD GPU의 전반적인 비용 경쟁력을 약화시킵니다. 결과적으로 NVIDIA는 지연 시간 요구 사항과 관계없이 임대 시장에서 비용 대비 성능 면에서 AMD를 지속적으로 앞지르고 있습니다. 이러한 불균형은 AMD GPU가 주요 하이퍼스케일러를 제외하고는 도입률이 낮은 이유를 설명합니다. 이들은 일반적으로 GPU를 직접 장기적으로 구매하며 AMD 임대 시장의 가격 제약에 직면하지 않고도 AMD의 유리한 하드웨어 경제성을 활용할 수 있습니다.What rental price would make AMD GPUs competitive with Nvidia for renters of compute for inference? (추론용 컴퓨팅을 임대하는 사람들에게 AMD GPU가 Nvidia와 경쟁력을 갖추려면 어떤 임대 가격이 필요할까요?)
2025년 2분기 현재 H200의 1개월 계약 시장 임대 가격은 GPU당 시간당 약 2.5달러로, 변동 폭이 크고 저품질 클라우드의 경우 가격이 더 낮습니다. MI325X의 1개월 임대 계약은 존재하지 않는 반면, MI300X의 1개월 임대 계약은 시간당 2.5달러가 넘기 때문에 MI300X는 임대 경쟁력이 떨어집니다. 아래에서는 NVIDIA H200 임대와 경쟁력을 갖추려면 MI300X와 MI325X의 대략적인 1개월 임대 가격이 얼마여야 하는지 계산했습니다.
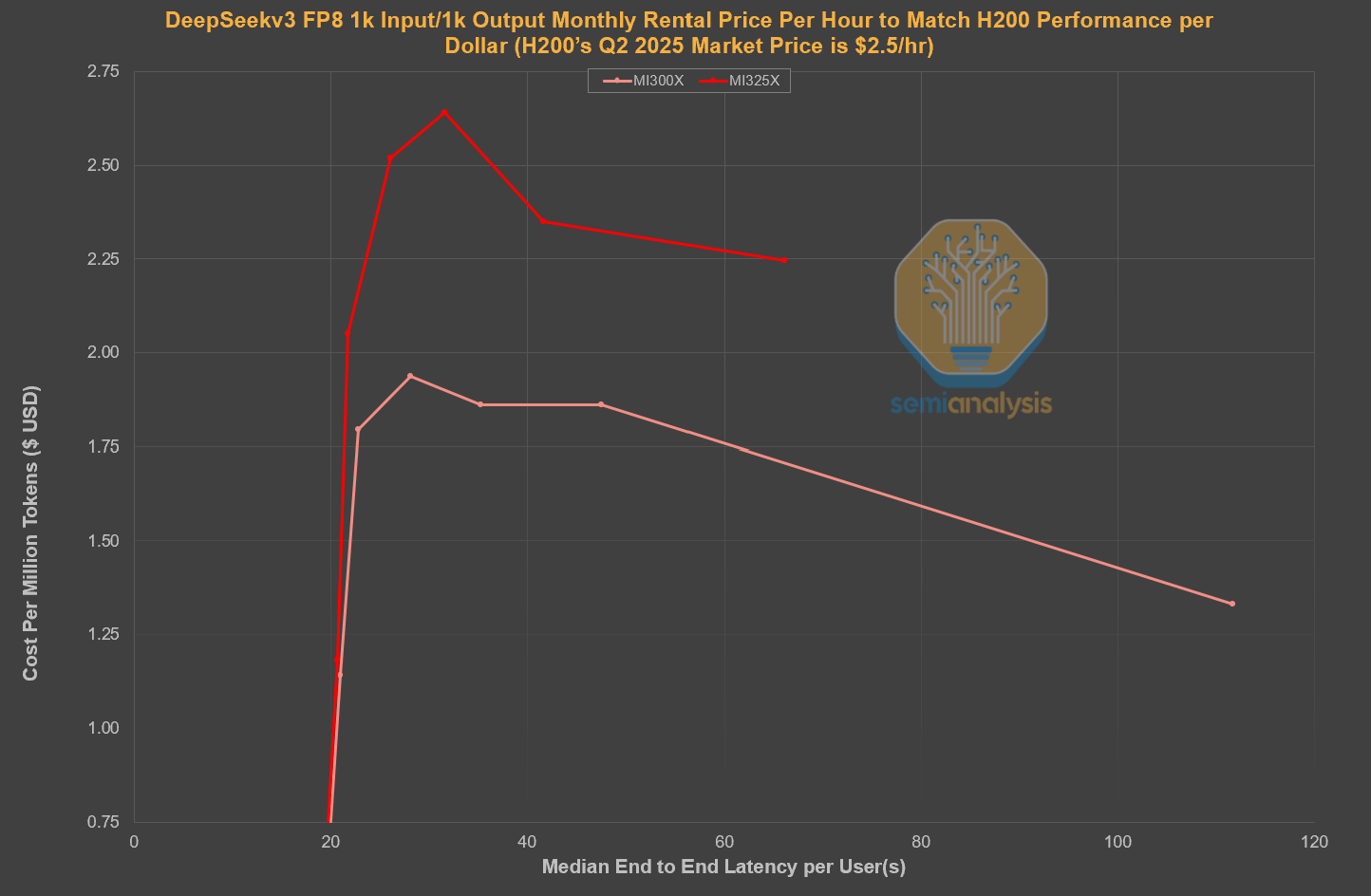
출처: semianalysis
번역 및 채팅 작업(입력 1,000건, 출력 1,000건)의 경우, MI300X 대여 가격은 H200과 경쟁하려면 시간당 1.9달러로 책정되어야 합니다. MI325X는 H200과 경쟁하려면 1개월 계약 기간 동안 시간당 2.5달러 미만으로 책정되어야 합니다.
출처: semianalysis
추론 작업(입력 1k, 출력 4k)의 경우, MI300X는 H200과 비교했을 때 달러당 경쟁력 있는 성능을 발휘하려면 1개월 계약 기준으로 시간당 $2.1~$2.4 미만으로 책정되어야 합니다. MI325의 경우, 경쟁력을 갖추려면 상호작용성에 따라 시간당 $2.75~$3의 GPU당 가격이 책정되어야 합니다.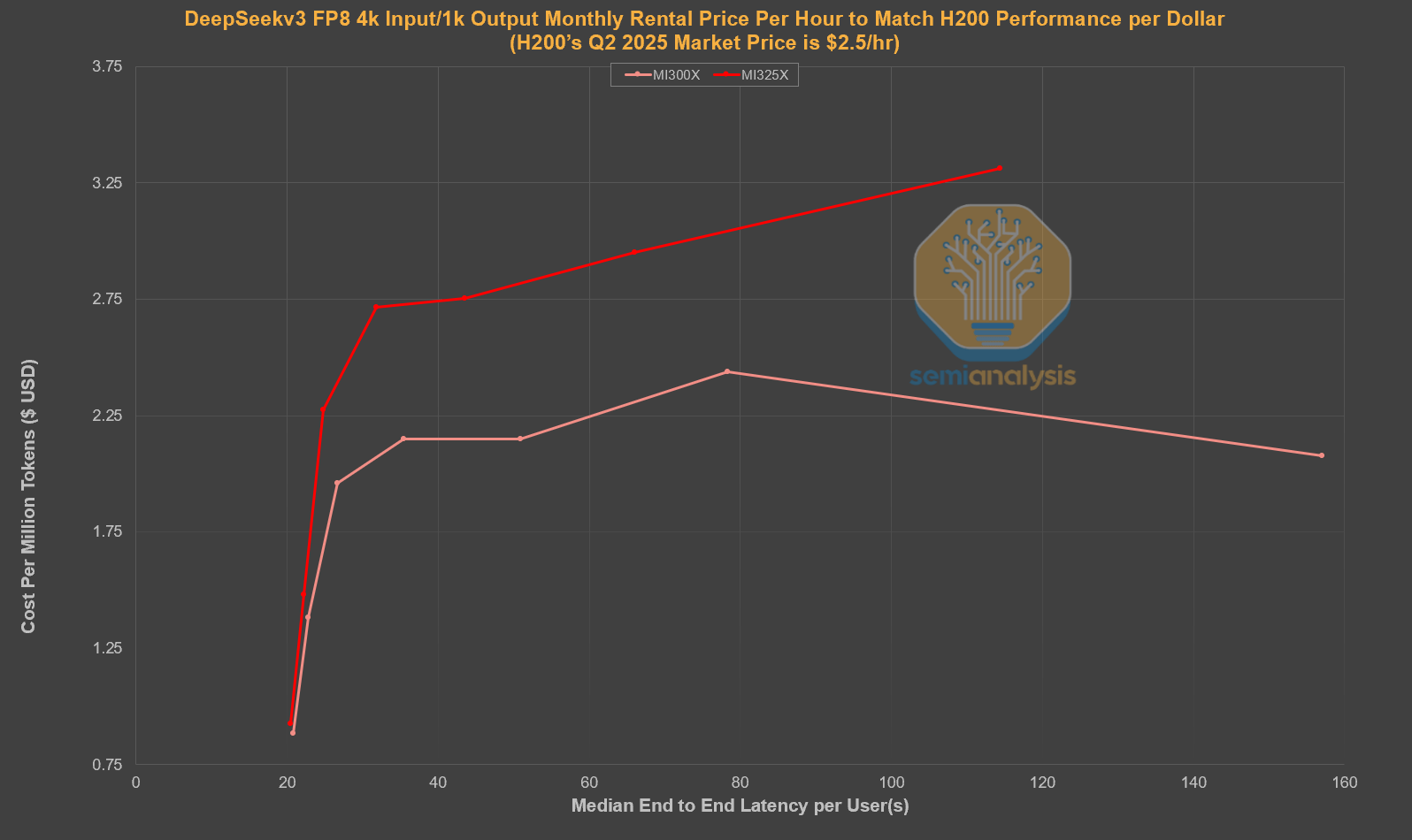
출처: semianalysis
요약 작업(입력 4k, 출력 1k)의 경우, MI325X 1개월 계약 가격은 시간당 2.75달러~3달러이고, MI300X 가격은 시간당 2.1달러~2.4달러입니다.Sneak Peek of B200 Performance (B200 성능 미리 보기)
현재 소프트웨어 지원이 부족하여 전체 벤치마크 실행에 B200을 포함하지 않았습니다. 이 글을 쓰는 시점을 기준으로 대부분의 주요 서비스 프레임워크는 B200 GPU를 안정적으로 지원하지 않습니다. vLLM의 표준 릴리스 이미지는 아직 B200을 지원하지 않으며(참고), SGLang 팀은 B200 지원에 대한 명확한 일정을 발표하지 않았습니다. AMD 측에서는 MI355X를 벤치마킹하지 않았습니다. 아직 생산 단위가 확보되지 않았기 때문입니다. 엔지니어링 샘플이 있지만 버그가 완전히 해결되지 않았기 때문에 아직 테스트할 준비가 되지 않았습니다.
TensorRT-LLM은 B200을 지원하지만, 일부 모델에만 최적화되어 있으며, 이 일부 모델에는 DeepSeek V3 FP8이 특히 부족합니다. 따라서 B200의 성능을 미리 살펴보기 위해 일부 모델과 시나리오에서 TensorRT-LLM과 B200을 벤치마킹했습니다. 아래 그래프에서는 추론 작업 부하(1k 입력, 4k 출력)에 대한 LLaMA 70B와 405B를 보여줍니다.
출처: semianalysis
TensorRT LLM을 탑재한 B200(B200-TRT)은 LLaMA 70B 벤치마크에서 압도적인 우위를 점하며, 전반적으로 낮은 지연 시간과 높은 처리량을 제공합니다. MI325X와 MI300X는 B200과 경쟁하기에는 턱없이 부족합니다.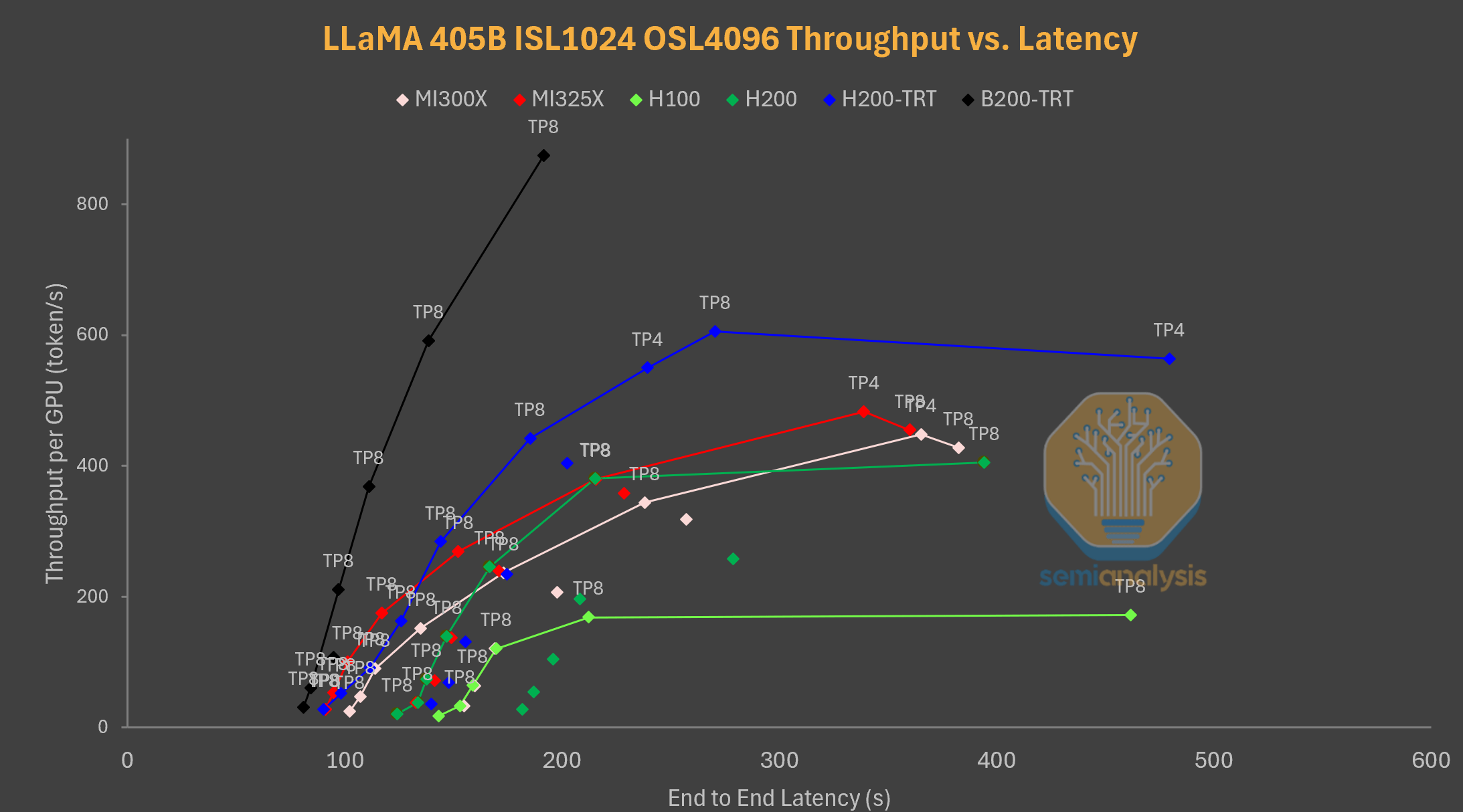
출처: semianalysis
LLaMA 405B의 경우, B200은 모든 지연 시간과 처리량에서 다른 모든 설정을 압도하는 성능을 보였으며, 테스트한 가장 높은 요청률에서도 정점에 도달하지 못했습니다.
B200은 지금까지 실행한 벤치마크에서 매우 높은 성능을 보여주었습니다. 전체적인 결과를 확실히 파악하기 위해, 몇 달 안에 MI355X와 B200의 학습 및 추론 성능에 대한 보고서를 발표할 예정입니다.
📌 Nvidia B200 TRT-LLM 모델 밴치 마크 결과
출처: https://github.com/NVIDIA/TensorRT-LLM
AMD and NVIDIA Bugs During Inference (추론 중 AMD 및 NVIDIA 버그)
벤치마킹 과정에서 여러 가지 난관에 부딪혔습니다.
서빙 프레임워크에 튜닝 플래그가 너무 많아 조합 구성이 폭발적으로 늘어납니다. 예를 들어, vLLM은 max-num-seq, max-num-batched-tokens, num-scheduler-steps, max-model-len을 사용하는데, 이러한 구성의 대부분은 각 플래그가 개별적으로 성능에 미치는 영향에 대한 문서화가 부족합니다. 이로 인해 벤치마킹에 엄청난 시간이 소요되었고, 최적의 성능을 달성하기 위한 적절한 조합을 찾았는지 보장할 수 없었습니다. 결과적으로 NVIDIA와 AMD 엔지니어들이 최상의 구성을 제공해 줄 것을 기대해야 했습니다. 모든 서빙 프레임워크가 각 플래그의 성능 영향에 대한 문서를 개선하고, 이상적으로는 자동 튜닝 기능을 제공하기를 바랍니다. AMD와 Nvidia는 GPU에 이러한 기능을 제공하고 공개적으로 제공해야 합니다. 기꺼이 협력하겠습니다.
서빙 프레임워크의 코드 업데이트 속도 때문에 최신 성능 결과를 얻는 데 어려움을 겪었습니다. 최상의 구성을 적용하더라도, 한 GPU 유형에 대한 벤치마크 실행에는 60~120시간이 소요되며, 프레임워크 업데이트 코드는 거의 매주 발생합니다. vLLM v0에서 v1로의 전환, SGLang CUDA 그래프 캡처 실패, SGLang AMD 세그먼테이션 오류로 인해 벤치마킹을 처음부터 다시 시작해야 했고, 플래그 재구성 요청을 받을 때마다 여러 번 재시작해야 했습니다. 더욱 심각한 것은 AMD가 피드백 루프 사이에 새로 개발된 기능을 활성화해 달라고 여러 번 요청하여 여러 번 재실행해야 했고, 소프트웨어 버전에도 차이가 발생했습니다. 향후 라이브 벤치마크 웹사이트를 공개하여 이 문제를 해결하고자 합니다.
벤치마킹에 시간이 오래 걸리는 또 다른 이유는 여러 머신에서 실험을 병렬화할 수 없기 때문입니다. 클라우드 서비스 제공업체의 머신에서 처리량과 지연 시간 차이가 무시할 수 없을 정도로 크게 발생하여 AMD와 NVIDIA가 모든 실험을 다시 해달라고 요청했습니다.
마지막으로, AMD는 별도의 저장소 포크와 구성을 유지 관리하면서 심각한 지연을 초래했습니다. AMD가 별도의 vLLM 포크를 유지하고 있기 때문에 별도의 벤치마킹 설정을 작성해야 했습니다. 이 글을 쓰는 시점에 AMD는 vLLM 포크를 폐기하고 더 이상 사용하지 않도록 설정했습니다. 이러한 변화를 환영하며 AMD가 다른 소프트웨어에도 이러한 방식을 도입하기를 바랍니다. 구성 측면에서는 AITER 관련 환경 변수가 추가되어 PYTORCH_TUNABLE_OP 플래시백이 발생했습니다. 저희는 환경 변수를 사용하여 기능을 활성화하는 것에 대해 부정적인 입장을 표명했으며, PYTORCH_TUNABLE_OP처럼 이 문제도 해결되기를 바랍니다.AMD SGLang CI Testing Lacks Coverage Parity (AMD SGLang CI 테스트의 적용 범위 동등성 부족)
AMD의 전반적인 지속적 통합(CI)은 지난 5개월 동안 크게 개선되었습니다. 5개월 전만 해도 AMD는 SGLang 추론 CI를 전혀 사용하지 않았지만, 이제는 어느 정도 사용하고 있습니다. 하지만 안타깝게도 CI 테스트 커버리지는 NVIDIA에 비하면 턱없이 부족합니다.
3주 전, Anush(AMD AI Czar)는 SGLang CI를 수정하기 위해 핵심 엔지니어 중 한 명에게 996번 작업을 맡겼습니다. AMD는 어느 정도 진전을 이루었지만, 안타깝게도 여전히 수십 개의 단위 테스트가 누락되어 있습니다. 적절한 테스트가 없다면 AMD는 소프트웨어 품질 저하와 버그 증가로 인해 개발자 경험 저하 및 도입 속도 저하를 겪게 될 것입니다.
출처: semianalysis
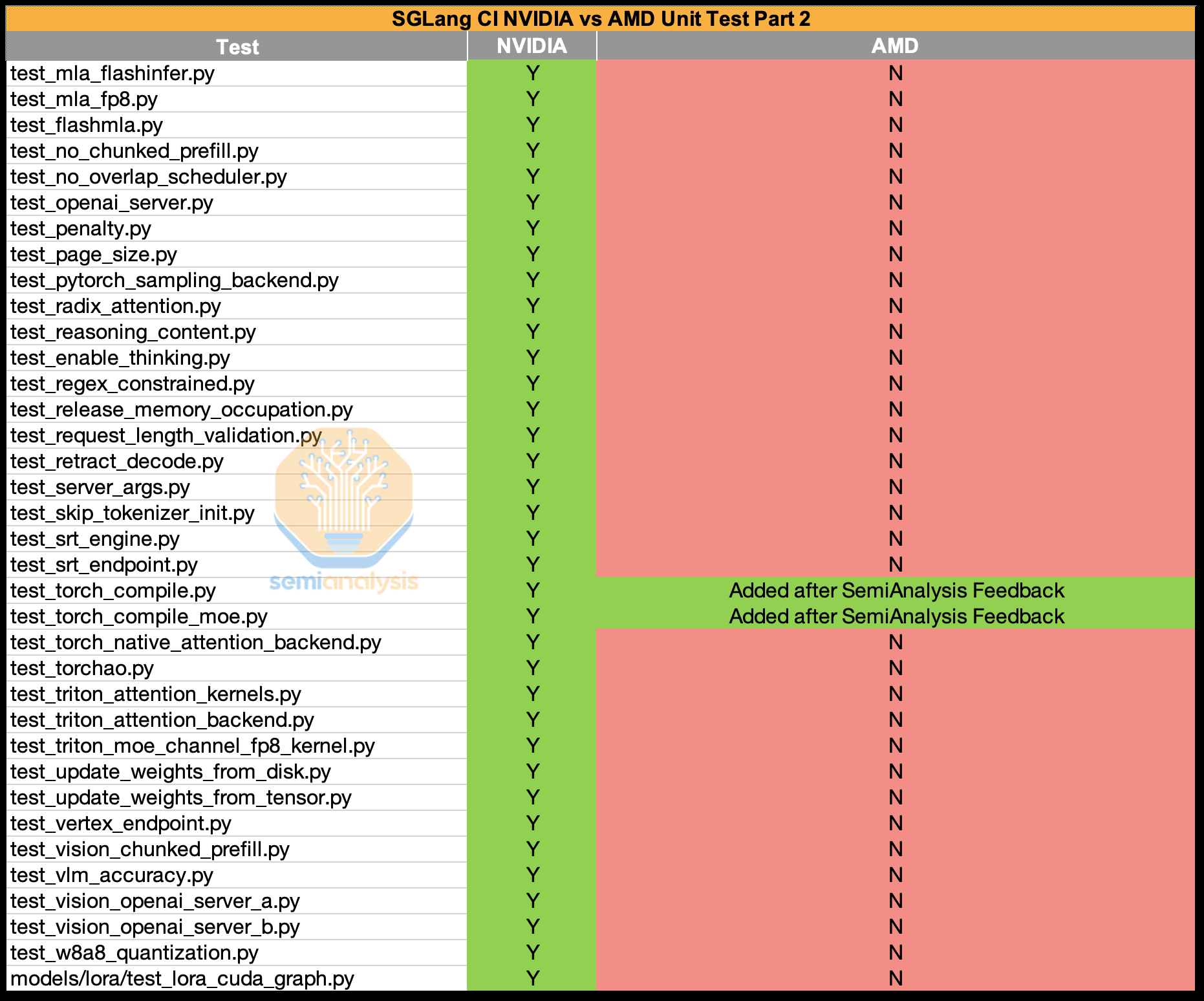
출처: semianalysis
또한 DeepSeekv3와 관련된 DP 어텐션, MoE EP 테스트 등 다중 GPU 단위 테스트가 많이 누락되었습니다.

출처: semianalysis
Using ROCm makes the models “Dumber” than on CUDA (ROCm을 사용하면 모델이 CUDA보다 "더 멍청해집니다")
야간 정확도 측면에서, AMD는 SemiAnalysis가 3주 전 정확도 문제를 지적하기 전까지 정확도 테스트를 전혀 진행하지 않았습니다. 대부분의 모델에서 AMD에서 NVIDIA를 사용했을 때보다 정확도 품질이 떨어지는 것을 확인했습니다. 테스트된 모델의 25%는 AMD에서 실행했을 때 정확도 테스트에서 실패했습니다.
즉, ROCm에서 동일한 모델을 사용하면 NVIDIA에서 얻을 수 있는 결과보다 더 멍청한 결과를 얻게 됩니다.
AMD는 이 문제를 즉시 해결하기 위해 996명의 엔지니어를 더 투입해야 합니다!
출처: SemiAnalysis, SGLang, Github
📌 역자주: AMD 드라이버는 Nvidia 드라이버 보다 성능이 떨어져서 채굴 업계에서도 가격은 저렴하지만 상대적으로 운영안정성이 낮은 업계 평판이 있었음. 아마도 회사의 출발점이 다른것이 근본적인 원인이 아닌가 생각됨.
Stock Buy Backs Versus Internal Clusters (자사주 매입 VS 내부 클러스터)
2025년 1분기에 AMD는 자사주 매입에 약 7억 5천만 달러를 지출했지만, 내부 R&D를 위한 클러스터 임대에는 1,300만 달러만 지출한 것으로 추산됩니다. ROCm 소프트웨어 품질은 크게 개선되었지만, 소프트웨어 품질과 개발자 경험은 여전히 NVIDIA 소프트웨어 품질과 기능 완성도에는 미치지 못합니다.
예를 들어, 분산형 프리필 추론 최적화는 이러한 최적화 개발에 필요한 내부 클러스터 수준 리소스 부족으로 인해 아직 AMD에 적용되지 않았습니다.
AMD의 내부 R&D 예산에 대한 추정치는 AMD가 내부적으로 약 4,000대의 MI300X를 보유하고 있으며, 하이퍼스케일러와 Neoclouds에서 임대하는 데 시간당 1.5달러가 소요된다는 사실에 기반합니다. 시간당 1.5달러/GPU * 4,000개 GPU * 90일/분기 * 24시간/일 = 분기당 1,300만 달러의 R&D 클러스터 지출입니다. 그들은 지출을 늘리고 있지만, 장기적으로 팀과 프로젝트에 클러스터를 할당하기보다는 단기 GPU 임대를 통해 이를 실천하고 있습니다.
출처: SemiAnalysis
속도가 관건이며, AMD가 기회를 잡으려면 더 빠르게 달리고 더 큰 투자를 해야 합니다. 더 많은 내부 클러스터 리소스는 내부 개발 및 CI 지원 가속화에 도움이 될 것입니다.
AMD가 자체적으로 테스트하지 않았고 AMD 내부적으로 4K GPU만 보유하고 있다면 고객이 왜 AMD의 대형 클러스터를 구매하겠습니까? MI325X와 같은 더 큰 규모의 계획이 있지만, 이는 장기 계약이 아닌 단기 계약으로만 제공됩니다.AMD’s Lack of Disaggregated Prefill Inference Optimization (AMD의 분산된 사전 채우기 추론 최적화 부족)
AMD가 단일 노드 추론에서는 우위를 점하고 있지만, 현재 AMD는 분산형 프리필(disaggregated prefill), 스마트 라우팅(Smart Routing), NVMe KV 캐시 계층화(NVMe KV Cache Tiering)와 같은 여러 추론 기능에 대한 지원을 부족합니다. 분산형 서빙은 수년간 업계 표준이 되어 왔으며, 지난달 NVIDIA는 분산형 추론 프레임워크인 Dynamo를 오픈소스로 공개하여 이 기술의 대중화를 더욱 가속화했습니다. 분산형 서빙은 별도의 컴퓨팅 인스턴스를 사용하여 프리필 및 디코딩을 포함한 여러 단계의 요청을 처리합니다.

출처: SemiAnalysis
또한 NVIDIA는 SGLang과 파트너십을 맺고 SGLang에 분산형 서빙 기능을 추가했지만, AMD SGLang 분산형 서빙 기능은 아직 없습니다. AMD에는 분산형 프리필 솔루션이 없기 때문에 NVIDIA가 순수 성능과 비용 대비 성능 면에서 우위를 점하고 있습니다.
AMD는 LMSys의 SGLang 유지 관리 팀에 16노드 MI300X 클러스터를 제공하여 파트너십을 모색하고 ROCm에서도 분산형 프리필을 작동시킬 수 있도록 할 계획입니다. NVIDIA Dynamo의 포크 버전을 사용하는 AMD 분산형 프리필 프로토타입은 6월 12일 AMD의 Advancing AI 행사에서 시연될 것으로 예상됩니다.
출처: Source: LMSys
AMD와 Nvidia의 역량 간 격차는 Nvidia Dynamo의 다른 기능에서도 나타납니다.
Dynamo Smart Router는 다중 GPU 추론 배포에서 각 토큰을 사용 가능한 두 인스턴스 모두에 지능적으로 라우팅합니다. 사전 채우기 단계에서는 수신 토큰이 사전 채우기를 제공하는 여러 GPU에 균등하게 분배되어 사전 채우기 단계에서 특정 전문가의 병목 현상을 방지하는 것을 의미합니다.
마찬가지로, 디코딩 단계에서는 시퀀스 길이와 요청이 디코딩을 제공하는 GPU 전반에 걸쳐 적절하게 분산되고 균형을 유지하는 것이 중요합니다. 트래픽이 많은 일부 전문가는 Dynamo에서 제공하는 GPU Planner를 통해 복제되어 부하 분산을 유지할 수 있습니다.
라우터는 또한 모델을 제공하는 각 복제본에 부하를 분산하는데, 이는 AMD의 vLLM을 비롯한 여러 추론 엔진에서는 지원하지 않는 기능입니다.
출처: Nvidia
Dynamo의 GPU Planner는 프리필 및 디코드 노드 모두의 자동 확장 기능을 제공하며, 하루 종일 자연스럽게 발생하는 수요 변동에 맞춰 추가 노드를 가동합니다. MoE 모델에서 프리필 및 디코드 노드 모두에서 여러 전문가 간의 로드 밸런싱을 구현할 수 있습니다. GPU Planner는 부하가 높은 전문가에게 추가적인 컴퓨팅을 제공하기 위해 추가 GPU를 가동합니다. 또한 필요에 따라 프리필 및 디코드 노드 간에 노드를 동적으로 재할당하여 리소스 활용도를 극대화할 수 있습니다.
이 기능은 디코딩 및 프리필에 사용되는 GPU 비율을 변경할 수 있도록 지원합니다. 특히 Deep Research와 같이 디코딩보다 프리필이 더 많이 필요한 경우에 유용합니다. 이러한 애플리케이션은 방대한 양의 컨텍스트를 검토해야 하지만 상대적으로 적은 양의 컨텍스트만 생성하기 때문입니다.
안타깝게도 이 기능은 현재 AMD 생태계에서 제공되지 않습니다.
출처: Nvidia
NVIDIA Dynamo의 KVCache 오프로드 관리자는 이전 사용자 대화의 KVCache를 NVMe 스토리지에 저장하여 전반적인 사전 채우기 실행의 효율성을 높여줍니다.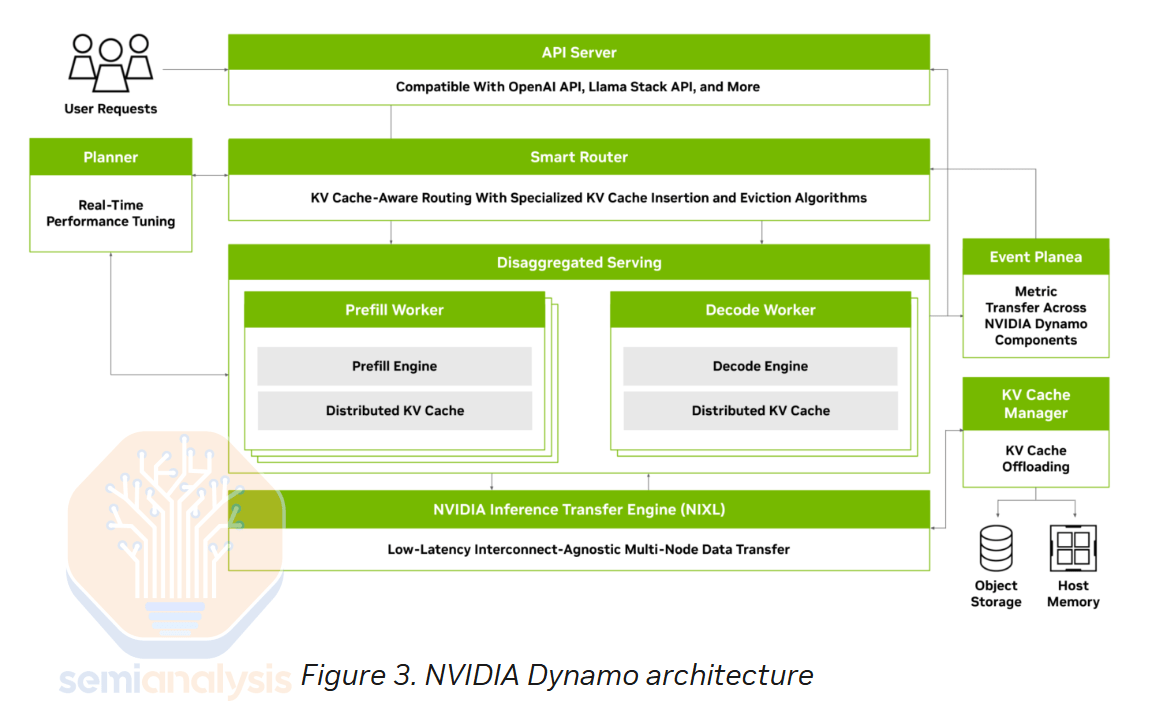
출처: Nvidia
사용자가 LLM과 진행 중인 다중 응답 대화에 참여할 때, LLM은 대화 초반에 제시된 질문과 응답을 고려하여 이를 입력 토큰으로 활용해야 합니다. 단순 구현에서는 추론 시스템이 이전 질문과 응답을 생성하는 데 사용된 KV 캐시를 폐기하게 되므로, KV 캐시를 다시 계산하고 동일한 계산을 반복해야 합니다.
Dynamo의 NVMe KVCache 오프로드 기능을 사용하면 사용자가 대화에서 벗어나면 KVCache를 NVMe 스토리지 시스템으로 오프로드하여 대화에 복귀할 때까지 저장할 수 있습니다. 사용자가 대화에서 후속 질문을 하면 NVMe 스토리지 시스템에서 KVCache를 빠르게 불러올 수 있으므로 KVCache를 다시 계산할 필요가 없습니다.
이렇게 하면 사전 채우기 노드의 용량을 확보하여 더 많은 수신 볼륨을 처리하거나, 필요한 사전 채우기 배포 크기를 줄일 수 있습니다. 또한 KV 캐시를 검색하는 데 필요한 시간이 계산하는 시간보다 훨씬 단축되어 사용자는 첫 번째 토큰을 얻는 데 걸리는 시간이 단축되어 훨씬 더 나은 경험을 할 수 있습니다.
출처: Nvidia
KVCache 오프로드를 위한 이러한 기능은 RLVR 및 도구를 사용하는 다중 에이전트 시스템이 보편화됨에 따라 점점 더 중요해질 것이며, AMD가 모색해야 할 또 다른 중요한 기능입니다.
NVIDIA Dynamo 외에도 점점 더 많은 분산 서비스 라이브러리가 사용되고 있습니다. 예를 들어, DeepSeek 추론 시스템 복제 시도에서 SGLang 팀은 KV 캐시 전송에 Mooncake Transfer Engine을 사용했습니다. Mooncake Transfer Engine은 고성능 무복사 데이터 전송 라이브러리입니다. 원래 Mooncake 서비스 플랫폼의 일부로 설계된 Mooncake Transfer Engine은 이제 NIXL에 백엔드 플러그인으로 통합되었습니다. 최근 Red Hat AI는 KV 캐시 전송에 NIXL을 사용하는 Kubernetes 네이티브 분산 추론 프레임워크인 llm-d를 발표했습니다. NIXL의 인기가 높아짐에 따라 NVIDIA GPU는 최고 수준의 최신 지원을 받게 될 것입니다. AMD가 개발자를 지원하지 않으면 동일한 소프트웨어 단편화 문제가 다시 발생할 것입니다.
AMD 엔지니어는 위에서 언급한 모든 추론 최적화를 모색하고 구현하기 위해 훨씬 더 많은 컴퓨팅 리소스가 필요할 것입니다.Next Steps and Future Exploration (다음 단계 및 미래 탐색)
저희는 벤치마킹 방법론을 지속적으로 개선하기 위해 최선을 다하고 있습니다. 이러한 노력의 일환으로, 장기적으로는 소프트웨어 업데이트 제공 속도에 발맞추기 위해 GitHub CI를 활용한 주간 실행 등 자동화된 정기 벤치마크 오픈소스 저장소를 구축할 계획입니다. 이를 통해 커뮤니티에서 결과를 검증할 수 있도록 감사 가능한 벤치마크 로그를 확보할 수 있습니다. 이미 여러 업계 협력사로부터 이러한 노력을 지원하기 위한 지원을 약속받았습니다.
프록시 벤치마크를 실제 운영 워크로드에 더욱 근접하게 수렴하기 위해, 입력 및 출력 시퀀스 길이 비율을 더욱 심도 있게 분석하고 다양한 입력/출력 길이 분포를 가진 추론 채팅 로그 멀티턴 데이터 세트를 수집할 것입니다.
원문 출처:
https://semianalysis.com/2025/05/23/amd-vs-nvidia-inference-benchmark-who-wins-performance-cost-per-million-tokens/#tco-per-hour-per-gpu-%e2%80%93-self-owned-and-operated-clustersAMD vs NVIDIA Inference Benchmark: Who Wins? – Performance & Cost Per Million Tokens
It has been long claimed that AMD’s AI servers can achieve better inference performance per total cost of ownership (TCO) than Nvidia. We have spent the past six months investigating and validating…
semianalysis.com
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
Tesla Dojo에서 결함 컴퓨팅 노드 탐지 방법 및 효율화 (25.6.12) (2) 2025.06.11 네이버 플레이스, NVIDIA TensorRT-LLM으로 SLM 기반 vertical 서비스 최적화 (25.6.6) (5) 2025.06.06 화웨이 AI CloudMatrix 384 - 엔비디아 GB200 NVL72 에 대한 중국의 대답 (25.5.7) (9) 2025.05.07 마이크로소프트 데이터센터 동결 과 전략의 변화 (25.5.1) (0) 2025.05.01 ChatGPT vs Grok vs Gemini vs Perplexity 사용자 테스트 및 비교 (25.2.23) (1) 2025.02.23