-
DeepSeek 출시 128일 이후.. (25.7.8)TechStock&Review/AI&Cloud&SW 2025. 7. 8. 09:47
DeepSeek Debrief: >128 Days Later

출처: SemiAnalysis 중국 LLM DeepSeek R1 출시가 주식 시장과 서구 AI 세계를 뒤흔든 지 150여 일이 지났습니다. R1은 OpenAI의 추론 성능에 필적하는 최초의 공개 모델이었습니다. 그러나 DeepSeek(그리고 중국)이 입력당 0.55달러, 출력 당 2.19달러라는 매우 낮은 가격을 앞세워 AI 모델을 상품화할 것이라는 우려에 가려 이러한 우려는 상당 부분 희석되었습니다 . 이로 인해 당시 SOTA 모델인 o1의 출력 토큰 가격이 90% 이상 하락했습니다. 이후 추론 모델 가격은 크게 하락했으며, OpenAI는 최근 자사 주력 모델 가격을 80% 인하했습니다.
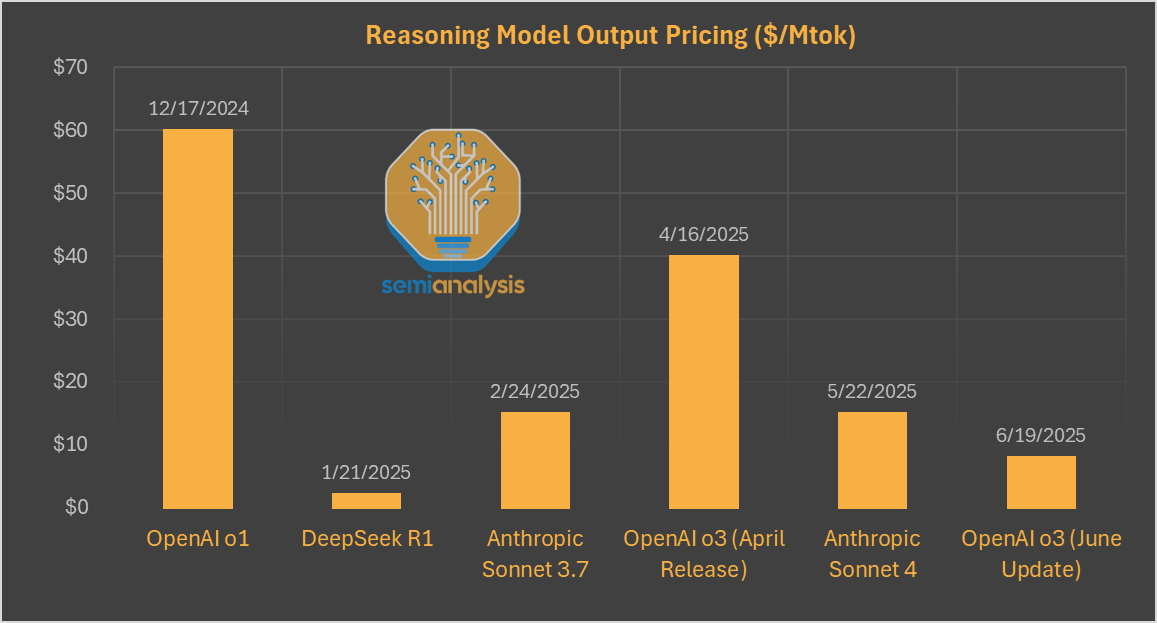
출처: SemiAnalysis, 회사겨격
DeepSeek이 출시 이후 RL 확장을 계속하면서 R1도 업데이트되었습니다. 이를 통해 모델은 여러 영역, 특히 코딩 분야에서 개선되었습니다. 이러한 지속적인 개발과 개선은 앞서 다루었던 새로운 패러다임의 특징입니다.
https://semianalysis.com/2025/06/08/scaling-reinforcement-learning-environments-reward-hacking-agents-scaling-data/Scaling Reinforcement Learning: Environments, Reward Hacking, Agents, Scaling Data
The test time scaling paradigm is thriving. Reasoning models continue to rapidly improve, and are becoming more effective and affordable. Evaluations measuring real world software engineering tasks…
semianalysis.com
오늘은 DeepSeek이 AI 모델 경쟁에 미치는 영향과 AI 시장 점유율 현황을 살펴보겠습니다.A Boom and… Bust? (호황과… 침체? )
DeepSeek 출시 이후 소비자 앱 트래픽이 급증하여 시장 점유율이 급격히 상승했습니다. 중국 사용자에 대한 추적이 제대로 이루어지지 않고 서구권 연구소들이 중국에 진출하지 못하고 있기 때문에, 아래 수치는 DeepSeek의 전체 도달 범위를 과소평가 (understated)한 것입니다. 그러나 DeepSeek의 폭발적인 성장세는 다른 AI 앱의 성장세를 따라가지 못했으며, DeepSeek 시장 점유율은 이후 하락했습니다.

출처: SemiAnalysis, SensorTower
웹 브라우저 트래픽의 경우, DeepSeek의 트래픽이 출시 이후 절대적인 감소세를 보이며 상황은 더욱 심각해졌습니다. 다른 주요 AI 모델 제공업체들은 모두 같은 기간 동안 사용자 수가 눈에 띄게 증가했습니다.

출처: SemiAnalysis, SmiliarWeb
DeepSeek 호스팅 모델의 저조한 사용자 모멘텀은 타사 호스팅 DeepSeek 인스턴스와 극명한 대조를 이룹니다. 타사 호스트에서 R1과 V3의 총 사용량은 R1 출시 이후 거의 20배 가까이 빠르게 증가하고 있습니다.

출처: SemiAnalysis, OpenRouter
데이터를 더 자세히 살펴보면, DeepSeek 토큰을 회사 자체에서 호스팅하는 토큰으로만 분리할 수 있습니다. 이를 통해 DeepSeek의 총 토큰 점유율이 매달 감소하고 있음을 알 수 있습니다.

출처: SemiAnalysis, OpenRouter
그렇다면 DeepSeek 모델의 인기가 높아지고 가격이 매우 저렴함에도 불구하고, 사용자들이 DeepSeek 자체 웹 앱과 API 서비스에서 다른 오픈 소스 공급업체로 옮겨가는 이유는 무엇일까요?
답은 토큰경제학과 모델 제공을 위한 KPI 간의 수많은 상충 관계 (the myriad of tradeoffs) 에 있습니다. 이러한 상충 관계는 모델의 토큰당 가격이 이러한 KPI 결정의 결과이며, 모델 제공업체의 하드웨어 및 모델 설정에 따라 조정될 수 있음을 의미합니다.Tokenomics Basics (토큰경제학의 기본)
토큰은 AI 모델의 기본 구성 요소입니다. AI 모델은 토큰 형태로 인터넷을 읽고 학습하여 텍스트, 오디오, 이미지 또는 액션 토큰 형태로 출력을 생성할 수 있습니다. 토큰은 큰 언어 모델이 전체 단어나 글자 대신 세고 처리하는 작은 텍스트 조각(예: "fan", "tas", "tic")일 뿐입니다.
젠슨 황 이 데이터센터가 AI 공장으로 변모한다고 말할 때, 이러한 공장의 입력과 출력은 토큰입니다. 실제 공장과 마찬가지로 AI 공장은 P x Q 방정식으로 수익을 창출합니다. P는 토큰당 가격이고 Q는 입력 및 출력 토큰의 수량입니다.
일반 공장과 달리 토큰 가격은 모델 제공업체가 모델의 다른 속성을 기반으로 해결할 수 있는 변수입니다 . 주요 KPI는 다음과 같습니다.
- 지연 시간(Latency) 또는 첫 번째 토큰 생성 시간(Time-to-First-Token/TTFT): 모델이 토큰을 생성하는 데 걸리는 시간입니다. 이는 '첫 번째 토큰 생성 시간' 또는 모델이 사전 채우기 단계(즉, 입력 토큰을 KVCache에 인코딩하는 단계)를 완료하고 디코딩 단계에서 첫 번째 토큰을 생성하는 데 걸리는 대략적인 시간이라고도 합니다.
- 상호작용성(Interactivity) : 각 토큰이 생성되는 속도로, 일반적으로 사용자당 초당 토큰 수로 측정됩니다. 일부 제공업체는 상호작용성의 역함수인 각 출력 토큰 간 평균 시간(Time Per Output Token - 출력 토큰당 시간 또는 TPOT)에 대해서도 언급합니다. 사람의 판독 속도는 초당 35단어이지만, 대부분의 모델 제공업체는 초당 약 20 ~ 60토큰의 출력 속도를 기준으로 삼고 있습니다.
- 컨텍스트 윈도우(Context Window) : 이전 토큰이 제거되고 모델이 대화의 이전 부분을 '잊기' 전까지 모델의 '단기 메모리'에 얼마나 많은 토큰을 보관할 수 있는지를 나타냅니다. 사용 사례에 따라 필요한 컨텍스트 윈도우가 다릅니다. 대규모 문서 및 코드 기반 분석은 모델이 데이터에 대해 일관성 있게 추론할 수 있도록 더 큰 컨텍스트 윈도우를 통해 이점을 얻습니다.
어떤 모델에서든 이 세 가지 KPI를 조작하여 토큰당 원하는 가격을 효과적으로 산출할 수 있습니다. 따라서 토큰을 백만 토큰당 가격($/Mtok)으로만 논의하는 것은 항상 생산적이거나 실용적이지 않습니다. 이는 토큰 사용자의 작업 부하와 요구 사항의 특성을 무시하기 때문입니다.DeepSeek Trade-Offs (DeepSeek의 장단점)
이제 DeepSeek이 R1 모델에 어떤 방식으로 서비스를 제공하는지에 대한 토큰 경제학을 살펴보고, 왜 자체 모델에서 시장 점유율을 잃어왔는지 알아보겠습니다.

출처: https://openrouter.ai/ 2025년 5월 접속. 3:1 입력:출력 비율로 계산된 혼합 $/Mtok
지연 시간과 가격을 비교해보면 DeepSeek 자체 서비스가 더 이상 지연 시간 측면에서 가장 저렴하지 않다는 것을 알 수 있습니다. 실제로 DeepSeek이 제품 가격을 이렇게 저렴하게 책정할 수 있는 가장 큰 이유는 모델이 첫 번째 토큰으로 응답하기 전까지 사용자가 수 초 동안 기다려야 하기 때문입니다. 이는 동일한 가격에 제공하면서도 응답 지연 시간이 훨씬 짧은 다른 제공업체와 비교되는 점입니다. 토큰 사용자는 Parasail이나 Friendli와 같은 제공업체를 통해 지연 시간이 거의 없는 서비스를 2~4달러에 구매할 수 있습니다. Microsoft Azure는 DeepSeek보다 2.5배 더 높은 가격에 서비스를 제공하지만 지연 시간은 25초 더 짧습니다. 이 데이터를 수집한 이후 DeepSeek의 상황은 더욱 심각해졌습니다. 거의 모든 R1 0528 인스턴스가 이제 5초 미만의 지연 시간 으로 호스팅되고 있기 때문입니다.

출처: https://openrouter.ai/ 2025년 5월 접속. 3:1 입력:출력 비율로 계산된 혼합 $/Mtok, 거품 크기는 컨텍스트 창 크기를 나타냄
동일한 플롯을 사용하지만 컨텍스트 윈도우에 버블 크기를 추가하면, DeepSeek이 제한된 추론 컴퓨팅 리소스로 매우 저렴한 모델을 제공하기 위해 실행하는 또 다른 단점을 확인할 수 있습니다. DeepSeek은 주요 모델 제공업체 중 가장 작은 64K 컨텍스트 윈도우를 실행합니다. 컨텍스트 윈도우가 작을수록 코딩과 같이 모델이 코드 베이스 전반에 걸쳐 많은 양의 토큰을 일관되게 기억하여 추론해야 하는 사용 사례가 제한됩니다. 위 차트에서 Lambda와 Nebius와 같은 제공업체를 사용하면 동일한 가격으로 2.5배 이상의 컨텍스트 크기를 얻을 수 있습니다.

출처: SemiAnalysis 벤치마크
하드웨어를 살펴보면, DeepSeek V3에서 AMD와 NVDA 칩을 비교한 위의 벤치마킹 결과를 통해 제공업체가 $/Mtok를 어떻게 계산하는지 확인할 수 있습니다. 단일 GPU 또는 GPU 클러스터에 더 많은 사용자를 동시에 배치함으로써, 모델 제공업체는 최종 사용자가 경험하는 총 대기 시간을 늘리고 지연 시간을 늘리며 상호 작용성을 낮출 수 있습니다(x축은 사용자당 중간 종단 간 지연 시간의 중간값으로 측정). 이를 통해 토큰당 총 비용을 줄일 수 있습니다. 배치 크기가 커지고 상호 작용성이 낮아지면 토큰당 비용이 감소하지만, 사용자 경험은 크게 저하됩니다.
분명히 말씀드리자면, 이는 DeepSeek의 적극적인 (active) 결정입니다. DeepSeek은 사용자로부터 수익을 창출하거나 채팅 앱이나 API 서비스를 통해 많은 토큰을 제공하는 데 관심이 없습니다. DeepSeek은 AGI 달성에만 집중하며 최종 사용자 경험에는 관심이 없습니다.
매우 높은 비율로 배칭(Batching)하면 추론 및 외부 사용에 가능한 최소한의 컴퓨팅만 사용할 수 있습니다. 이를 통해 연구 개발 목적으로 최대량의 컴퓨팅을 내부적으로 유지합니다. 앞서 논의했듯이 미국의 수출 통제는 중국 생태계의 모델 제공 역량을 제한했습니다. 따라서 DeepSeek의 경우 오픈 소스화하는 것이 합리적입니다. 보유한 컴퓨팅은 내부적으로 유지되고 다른 클라우드에서 모델을 호스팅하여 인지도와 글로벌 채택을 확보할 수 있습니다.
미국의 수출 통제로 인해 중국의 대규모 모델 추론 역량이 크게 제한되었지만, Tencent(Hunyuan-A13B) , Alibaba(qwen3) , Baidu(ernie4.5), 심지어 Rednote 에서 최근 출시한 제품에서 알 수 있듯이 유용한 모델을 학습하는 능력에는 그다지 방해가 되지 않았다고 생각합니다.Anthropic is More Like DeepSeek than They’d like to Admit (Anthropic은 그들이 인정하고 싶어하는 것보다 DeepSeek과 더 유사합니다.)
AI 세계에서 가장 중요한 것은 컴퓨팅입니다. DeepSeek처럼 Anthropic도 컴퓨팅에 제약을 받습니다. Anthropic은 제품 개발을 코드에 집중해 왔으며, Cursor와 같은 코딩 애플리케이션에서 높은 채택률을 보였습니다. Cursor 에서 높은 사용률은 사용자가 가장 중요하게 생각하는 비용과 경험을 제공했기 때문이라고 생각합니다. Anthropic은 AI 업계에서 오랬동안 1위를 유지하고 있습니다.
Cursor와 같은 토큰 소비자의 성공을 목격한 Anthropic은 터미널에서 실행할 수 있는 Claude Code를 출시했습니다. Claude Code의 사용량이 급증하면서 OpenAI의 codex는 큰 타격을 입었습니다.
이에 대응하여 구글은 자체 도구인 Gemini CLI를 출시했습니다. 클로드 코드와 유사한 코딩 도구이지만, 구글은 TPU를 통해 컴퓨팅의 이점을 활용하여 사용자에게 무료로 엄청나게 큰 요청 제한을 제공합니다.

출처: 구글
주요 AI 모델 API 가격 비교 (1백만 토큰당, USD) (25.7.7일 기준)모델 분류 서비스 모델명 입력 (Input) 출력 (Output) 특징 고성능 모델 OpenAI GPT-4o $5.00 $15.00 텍스트, 이미지 등 멀티모달 지원, 빠른 속도 OpenAI GPT-4 Turbo $10.00 $30.00 대규모 컨텍스트, 높은 추론 능력 OpenAI GPT-4 $30.00 $60.00 - Anthropic Claude 3 Opus $15.00 $75.00 뛰어난 추론 및 분석 능력 Google Gemini 2.5 Pro $1.25 (20만 토큰 이하) /
$2.50 (20만 토큰 초과)$10.00 (20만 토큰 이하) /
$15.00 (20만 토큰 초과)긴 컨텍스트(최대 100만 토큰), 합리적인 가격 중급/보급형 모델 Anthropic Claude 3.5 Sonnet $3.00 $15.00 Opus와 Haiku 사이의 균형 잡힌 성능 xAI Grok-beta $5.00 $15.00 실시간 정보 접근 가능성 (X 연동) OpenAI GPT-3.5 Turbo $0.50 $1.50 저렴한 비용, 빠른 응답 속도 경량/고속 모델 Anthropic Claude 3 Haiku $0.80 $4.00 매우 빠르고 비용 효율적인 모델 📌 참고: 구글의 경우 TPU 덕분에 압도적인 가격 경쟁력을 보여주고 있음. 보통 학습이 끝난 인프라는 추론 인프라로 전환된다고 함.
Claude Code는 뛰어난 성능과 디자인에도 불구하고 비용이 많이 듭니다. 여러모로 Anthropic 모델의 코드 성공은 회사에 상당한 부담을 안겨주었습니다. 왜냐하면 Anthropic 의 컴퓨팅 자원이 매우 제한적이기 때문입니다.
이는 Claude 4 Sonnet의 API 출력 속도에서 가장 두드러집니다. Claude 4 Sonnet 출시 이후 속도가 40% 감소하여 초당 45개 토큰을 약간 상회합니다. 이는 DeepSeek의 경우와 유사합니다. 사용 가능한 컴퓨팅 자원으로 모든 수신 요청을 관리하기 위해 더 높은 속도로 일괄 처리해야 하기 때문입니다. 또한 코딩 사용량이 토큰 수가 많은 대화에 치우치는 경향이 있어 토큰 수가 적은 캐주얼 채팅 애플리케이션에 비해 컴퓨팅 리소스 사용량이 증가합니다. 그럼에도 불구하고 o3나 Gemini 2.5 Pro와 같은 유사 모델은 훨씬 빠른 속도로 실행되며, 이는 OpenAI와 Google의 훨씬 더 큰 컴퓨팅 리소스를 반영합니다.
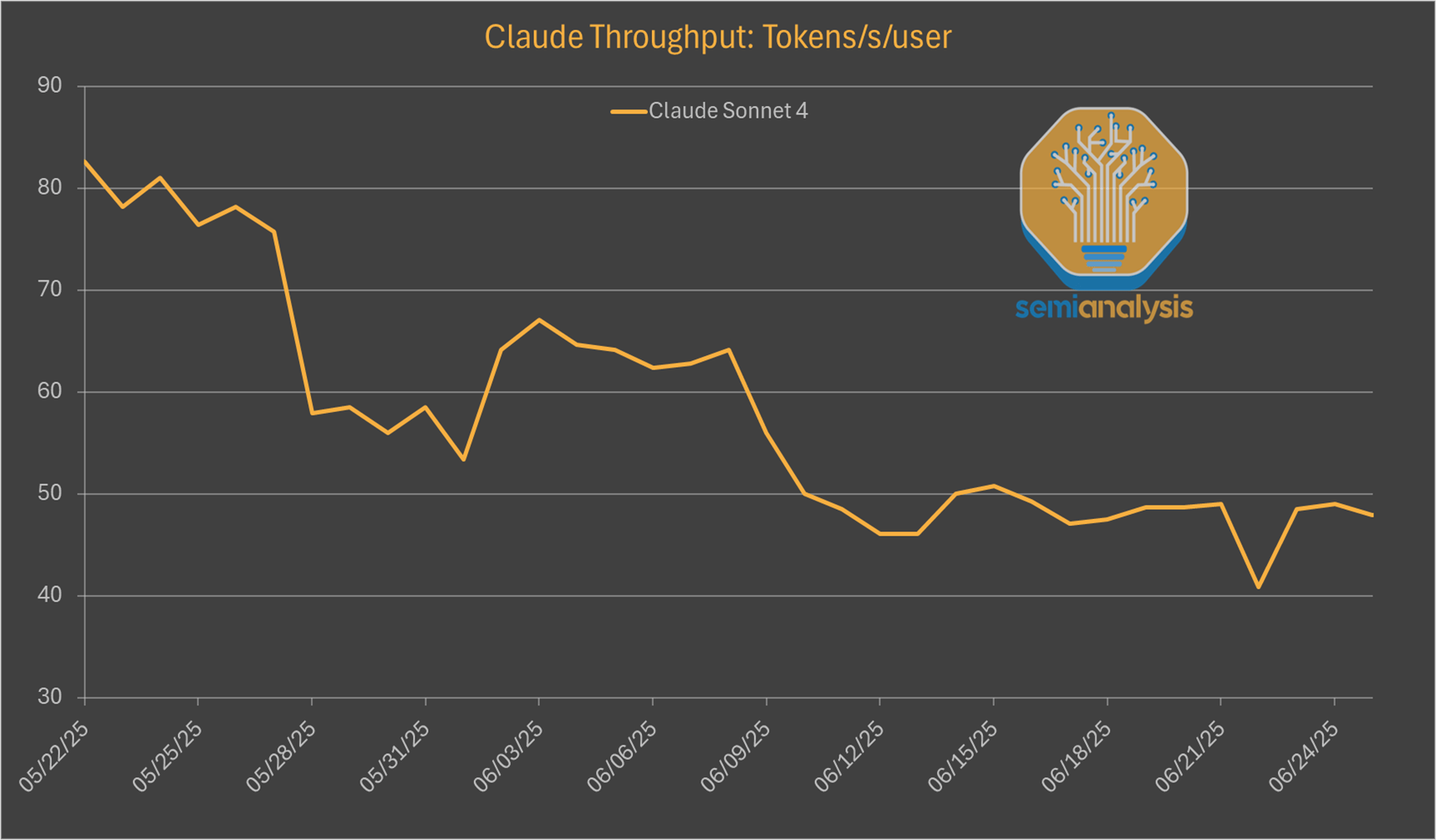
출처: SemiAnalysis, Artificial Analysis
Anthropic은 더 많은 컴퓨팅을 인수하는 데 주력하고 있으며, Amazon과 대규모 계약을 체결했습니다.
https://semianalysis.com/2024/12/03/amazons-ai-self-sufficiency-trainium2-architecture-networking/Amazon’s AI Self Sufficiency | Trainium2 Architecture & Networking
Amazon is currently conducting one of the largest build-out of AI clusters globally, deploying a considerable number of Hopper and Blackwell GPUs. In addition to a massive Capex invested into Nvidi…
semianalysis.com
Anthropic은 50만 개가 넘는 Trainium 칩을 확보하여 추론과 학습에 사용할 예정입니다. Claude 4는 AWS Trainium에서 사전 학습되지 않았다는 의견이 지배적이지만, 이러한 협력 관계는 아직 진행 중입니다. GPU와 TPU에서 학습되었기 때문입니다.
Anthropic은 또 다른 주요 투자자인 구글 컴퓨팅에도 눈을 돌렸습니다. Anthropic은 GCP로부터 상당한 양의 컴퓨팅, 특히 TPU를 임대하고 있습니다. 이러한 성공에 힘입어 Google Cloud는 다른 AI 기업으로 서비스 범위를 확대하고 있으며, OpenAI와도 계약을 체결했습니다. 이전 보도와는 달리, Google은 OpenAI에 TPU가 아닌 GPU만 임대하고 있습니다.
📌 참고: 구글은 Anthropic 지분의 약 14% (30억 수준) 지분 보유하고 있으며 의결권이나 이사회 참여권이 없는 투자만 진행하여 Anthropic의 독립적인 운영을 보장하고 있습니다. 아마존 또한 Anthropic 지분에 약 40억 투자하고 있으며 AWS를 주 클라우드 제공업체로 활용하는 전략적 파트너쉽 체결 하였으며 아마존 또한 지배적인 영향력을 행사하지 않는 수준으로 투자하고 있습니다.Speed Can be Compensated for (속도는 보상될 수 있다.)
Claude의 속도는 컴퓨팅 제약을 나타내지만, 전반적으로 Anthropic의 UX는 DeepSeek보다 우수합니다. 첫째, 속도는 느리지만 DeepSeek의 초당 25개 토큰보다 빠릅니다. 둘째, Anthropic 모델은 질문에 답하는 데 다른 모델보다 훨씬 적은 토큰이 필요합니다. 즉, 빠른 속도에도 불구하고 사용자는 훨씬 짧은 응답 시간을 경험하게 됩니다.
작업량에 따라 다를 수 있지만, Gemini 2.5 Pro와 DeepSeek R1-0528은 Claude보다 3배 이상 많은 단어를 사용합니다. Gemini 2.5 Pro, Grok 3, DeepSeek R1은 여러 벤치마크 점수를 종합하는 Artificial Analysis’ intelligence index 를 실행하는 데 훨씬 더 많은 토큰을 사용했습니다. 실제로 Claude는 주요 추론 모델 중 총 출력 토큰 양이 가장 적었으며, Claude 3.7 Sonnet보다 눈에 띄는 향상을 보였습니다.
토큰경제학의 이러한 측면은 제공업체들이 모델을 개선하기 위해 다양한 측면에서 노력하고 있음을 보여줍니다. 단순히 더 많은 정보/지능 (intelligence) 를 제공하는 것이 아니라, 토큰을 생산할 때마다 더 많은 정보/지능 (intelligence) 를 제공하는 것입니다.

출처: Artificial Analysis Intelligence Index, SemiAnalysis Rise of the Inference Clouds (추론 클라우드의 부상)
Cursor, Windsurf, Replit, Perplexity 및 기타 "GPT Wrappers" 또는 AI 토큰 기반 앱이 대중적으로 알려지면서, ChatGPT와 같이 월별 구독 형태로 제공하는 것이 아니라 서비스 형태로 토큰을 판매하는 Anthropic의 초점을 따르는 회사가 점점 늘어나고 있습니다.
원문출처: https://semianalysis.com/2025/07/03/deepseek-debrief-128-days-later/DeepSeek Debrief: >128 Days Later
SemiAnalysis is hiring an analyst in New York City for Core Research, our world class research product for the finance industry. Please apply here It’s been a bit over 150 days since the launc…
semianalysis.com
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
Kimi K2 오픈소스 모델: 종합 성능 및 아키텍처 분석 (25.7.13) (8) 2025.07.13 프로젝트 Vend: Claude는 작은 가게를 운영할 수 있을까? (25.7.11) (16) 2025.07.11 젠슨 황의 2025 GTC 파리 키노트: AI, 양자 컴퓨팅, 로보틱스의 미래 (25.6.14) (3) 2025.06.14 Tesla Dojo에서 결함 컴퓨팅 노드 탐지 방법 및 효율화 (25.6.12) (2) 2025.06.11 네이버 플레이스, NVIDIA TensorRT-LLM으로 SLM 기반 vertical 서비스 최적화 (25.6.6) (5) 2025.06.06