-
AWS Trainium: AI 군비 경쟁 속 아마존 맞춤형 실리콘 전략 심층 분석 (25.11.3)TechStock&Review/AI&Cloud&SW 2025. 11. 3. 09:46
AWS Trainium: AI 군비 경쟁 속 아마존 맞춤형 실리콘 전략 심층 분석
1. 요약
본 보고서는 Amazon Web Services(AWS)의 맞춤형 AI 훈련용 실리콘인 Trainium 칩에 대한 다차원적 분석을 제공한다. Trainium은 단순한 비용 절감 수단을 넘어, AI 시대의 클라우드 인프라 시장에서 수직적 통합과 시장 리더십을 확보하려는 AWS의 야심 찬 전략의 핵심 기둥으로 평가된다.
보고서의 핵심 분석 결과는 다음과 같다. 첫째, Trainium의 목적 기반 아키텍처는 대규모 모델 훈련 워크로드에서 범용 GPU 대비 상당한 가격 대비 성능 우위를 제공한다. 이는 AWS 내부 벤치마크뿐만 아니라 Anthropic, Databricks와 같은 주요 고객의 실제 도입 사례를 통해 검증되었다.
둘째, 아키텍처 심층 분석 결과, Trainium은 NeuronCore 시스톨릭 어레이(systolic array)를 중심으로 한 정교한 설계를 채택하고 있다. 또한, 다계층 메모리 구조와 전례 없는 규모의 확장을 위해 설계된 이중 인터커넥트 패브릭(칩 간 연결을 위한 NeuronLink와 노드 간 연결을 위한 EFA)을 통해 AI 훈련에 최적화된 구조를 갖추고 있다.
셋째, 공급망 분석을 통해 AWS가 자회사인 Annapurna Labs를 중심으로 정교한 멀티 벤더 생태계를 구축하고 있음을 확인했다. 1세대와 2세대 칩은 세계 최고의 파운드리인 TSMC와의 긴밀한 협력을 통해 제작되었으며, 3세대부터는 Alchip, Marvell과 같은 설계 파트너와 협력하고, 미래의 인터커넥트 칩 개발을 위해 Intel과도 전략적 파트너십을 맺는 등 리스크 분산 및 혁신 전략을 구사하고 있다.
넷째, Trainium의 시장 지배력 확보에 있어 가장 큰 도전 과제는 하드웨어가 아닌 소프트웨어 생태계이다. AWS Neuron SDK는 강력한 기능을 제공하지만, NVIDIA CUDA 플랫폼이 수십 년간 구축해 온 깊은 시장 지배력과 개발자 커뮤니티의 벽을 넘어야 하는 과제를 안고 있다.
마지막으로, Trainium은 AWS의 미래 핵심 수익원이 될 Amazon Bedrock과 같은 서비스를 구동하는 엔진이자, 'Project Rainier'와 같은 하이퍼스케일 AI 이니셔티브의 기반이다. 이는 궁극적으로 AI 클라우드 시장의 경제적 균형을 AWS에 유리하게 재편하려는 거대한 전략의 일환으로 분석된다.

AWS Trainium2 칩 - 출처: AWS 2. AWS Trainium의 탄생과 진화
2.1 맞춤형 실리콘의 당위성
Trainium의 개발은 AWS의 장기적인 전략적 맥락에서 이해해야 한다. 과거 NVIDIA와 같은 외부 하드웨어 공급업체에 대한 의존은 비용, 공급망 안정성, 그리고 기술 로드맵 통제 측면에서 본질적인 제약을 야기했다. Trainium과 같은 맞춤형 실리콘은 이러한 종속성에서 벗어나 전략적 독립성을 확보하고, 하드웨어부터 소프트웨어까지 전체 스택을 성능과 비용 측면에서 최적화하기 위한 필연적인 선택이었다.
AWS는 자체 칩 설계를 통해 고객에게 더 나은 가격 대비 성능을 제공하고, AI 워크로드에 특화된 혁신을 가속화할 수 있는 기반을 마련했다.2.2 1세대 (Trainium1): 시장 진입의 교두보 확보
소개: 1세대 Trainium 칩(이하 Trainium1)으로 구동되는 Amazon EC2 Trn1 인스턴스는 AWS가 고성능 AI 훈련 가속기 시장에 본격적으로 진출했음을 알리는 신호탄이었다.13 이는 GPU가 지배하던 시장에 새로운 대안을 제시하며, 클라우드 기반 AI 훈련의 경제성을 재정의하려는 시도였다.
핵심 가치 제안: Trainium1의 핵심 목표는 아키텍처의 유효성을 검증하고 GPU에 대한 강력한 경제적 대안을 제시하는 것이었다. AWS는 Trn1 인스턴스가 동급의 GPU 기반 EC2 인스턴스와 비교하여 훈련 비용을 최대 50%까지 절감할 수 있다고 주장하며, 비용 효율성을 전면에 내세웠다.
초기 도입: Trainium1은 Databricks, Ricoh와 같은 엔터프라이즈 고객들이 성공적으로 도입하여 실제 워크로드에서 그 효용성을 입증했다.2 이는 Trainium 아키텍처가 단순한 이론적 개념을 넘어, 실제 비즈니스 환경에서 가치를 창출할 수 있음을 보여준 중요한 사례가 되었다.

Trn1 인스턴스의 핵심은 16개의 Trainium 칩입니다(각 Trainium에는 2개의 NeuronCore-v2가 포함됨). 출처: AWS
2.3 2세대 (Trainium2): 생성형 AI 시대에 대응하는 기술적 도약
성능 도약: 2세대 Trainium 칩(이하 Trainium2)은 이전 세대 대비 최대 4배의 성능 향상과 2배의 에너지 효율성 개선을 이뤄냈다. 이러한 비약적인 발전은 파운데이션 모델(FM)과 거대 언어 모델(LLM)이 요구하는 막대한 컴퓨팅 파워를 충족시키기 위해 특별히 설계된 결과물이다.
시장 포지셔닝: Trainium2는 시장의 지배적 사업자인 NVIDIA의 H100 GPU와 직접 경쟁하는 제품으로 포지셔닝되었다. AWS는 Trainium2 기반 Trn2 인스턴스가 GPU 기반 EC2 P5 인스턴스보다 30-40% 더 나은 가격 대비 성능을 제공한다고 주장하며, 시장에 강력한 도전장을 내밀었다.
경제적 영향: Trainium2는 AWS에게 수십억 달러 규모의 비즈니스로 성장했으며, 분기별 150%의 성장률을 기록하며 수요가 공급을 초과하는 현상을 보였다. (아마존 2025년 3분기 실적발표 내용. 실적발표 전 시장에서는 부정적인 의견이 대다수) 이는 시장이 Trainium2의 가치를 인정하고 있음을 명확히 보여주는 지표이다. 25년 3분기 실적 발표에서 Trainium2 수요가 매우 높아 "완전히 구독(fully subscribed)" 된 상태라고 발표했으며 프로젝트 Rainier 에서 Anthropic이 차세대 'Claude' 모델을 훈련시키기 위해 50만개의 Trainium2 칩을 사용하는 대규모 AI 클러스터에 2025년 말까지 100만개로 확장 예정. 또한 AWS Bedrock 에서 사용 되는 토큰의 과반수가 이미 Trainium에서 실행되고 있습니다.

Trainium2는 AWS에서 특별히 제작한 3세대 머신러닝 칩입니다. 모든 Trainium2 칩에는 8개의 NeuronCore-V3가 포함되어 있습니다. Trainium2부터 AWS Neuron은 논리적 NeuronCore 구성(LNC)을 지원하며, 이를 통해 여러 물리적 NeuronCore의 컴퓨팅 및 메모리 리소스를 단일 논리적 NeuronCore로 결합할 수 있습니다. - 출처: AWS 

AWS Tranium2 를 이용한 Compute Instance SKU - 출처: SemiAnalysis 2.4 3세대 (Trainium3)와 그 이후: 시장 지배를 향한 로드맵
예상되는 발전: 차세대 칩인 Trainium3는 Trainium2 대비 2배의 성능 향상과 50%의 추가적인 에너지 효율성 개선을 목표로 하고 있다. 보다 보수적인 전망치로는 약 40%의 가격 대비 성능 향상이 예상된다.
시장 확대: Trainium2가 주로 Anthropic과 같은 소수의 초대형 고객 (Anthropic, Databricks) 를 대상으로 서비스되었다면, Trainium3는 중견 기업 고객까지 시장을 확대하여 고성능 AI 훈련에 대한 접근성을 대중화하는 것을 목표로 한다.
타임라인: Trainium3는 2025년 말에 프리뷰가 공개되고, 2026년 초부터 본격적인 양산에 들어갈 것으로 예상된다.
Trainium의 진화 과정은 단순한 선형적 개선이 아니라, AI 모델의 복잡성 증가에 발맞춘 기하급수적인 발전을 보여준다. Trainium1이 비용 중심의 가치를 입증하는 '개념 증명' 단계였다면, 생성형 AI의 폭발적인 성장은 AWS에게 더 큰 시장 기회를 제공했다.
이에 AWS는 Trainium2에 막대한 투자를 단행하며, 단순 비용 절감을 넘어 업계 최고의 '가격 대비 성능'을 목표로 삼았다. Trainium2의 '완전 판매(fully subscribed)' 상태는 이 전략의 성공을 입증했고, 이는 Trainium3에 대한 더욱 공격적인 로드맵을 정당화하는 근거가 되었다. 이처럼 AWS는 수직적 통합의 이점을 활용하여 AI 시장의 변화하는 요구에 기민하게 대응하는 하드웨어 전략을 구사하고 있다.
표 1: AWS Trainium 칩 세대별 비교기능 Trainium1 (Trn1) Trainium2 (Trn2) Trainium3 (예상) NeuronCore 버전 NeuronCore-v2 NeuronCore-v3 NeuronCore-v4 (예상) 최대 연산 성능 (FP8/BF16) 최대 3.4 PFLOPS (인스턴스) 최대 20.8 PFLOPS (인스턴스) ~40 PFLOPS (인스턴스) 메모리 종류 HBM HBM3e HBM3e 또는 차세대 HBM 칩당 메모리 32 GB 96 GB > 96 GB 인스턴스당 총 메모리 최대 512 GB 1.5 TB > 1.5 TB 칩 인터커넥트 (NeuronLink) NeuronLink-v2 NeuronLink-v3 차세대 NeuronLink 노드 인터커넥트 (EFA) 최대 1.6 Tbps 최대 3.2 Tbps > 3.2 Tbps 주요 지원 데이터 유형 FP32, TF32, BF16, FP16, INT8 FP32, TF32, BF16, FP16, cFP8 cFP8, 추가 최적화 데이터 유형 참고: Trainium3의 사양은 공개된 정보와 업계 동향을 바탕으로 한 예상치임.
3. Trainium 아키텍처 심층 분석
3.1 NeuronCore
핵심 설계 철학: Trainium은 범용 프로세서가 아닌, AI 훈련이라는 단 하나의 목적을 위해 제작된 주문형 반도체(ASIC)이다. 그 설계 철학은 AI 훈련에서 지배적으로 사용되는 행렬 곱셈 및 컨볼루션과 같은 특정 수학 연산의 처리 능력을 극대화하는 데 있다.
시스톨릭 어레이 (Systolic Array): NeuronCore의 핵심은 수천 개의 특수 연산 유닛이 그리드 형태로 배열된 시스톨릭 어레이이다. 이 유닛들은 심장이 혈액을 펌핑하는 것과 유사한 리드미컬하고 병렬적인 방식으로 데이터를 처리하며, 행렬 곱셈 연산에 최적화되어 있다. 이는 다수의 소형 코어를 사용하는 GPU의 아키텍처와 대조를 이룬다.
이기종 엔진 (Heterogeneous Engines): Trainium2를 구동하는 NeuronCore-v3는 여러 특화된 엔진으로 구성된 이기종 아키텍처를 채택하고 있다. 여기에는 행렬 곱셈을 위한 '텐서 엔진', 리덕션 연산을 위한 '벡터 엔진', 비선형 함수를 처리하는 '스칼라 엔진', 그리고 범용 C/C++ 프로그램 실행이 가능한 'GpSimd' 엔진이 포함된다. 이는 칩 내에서 정교한 작업 분담이 이루어지고 있음을 보여준다.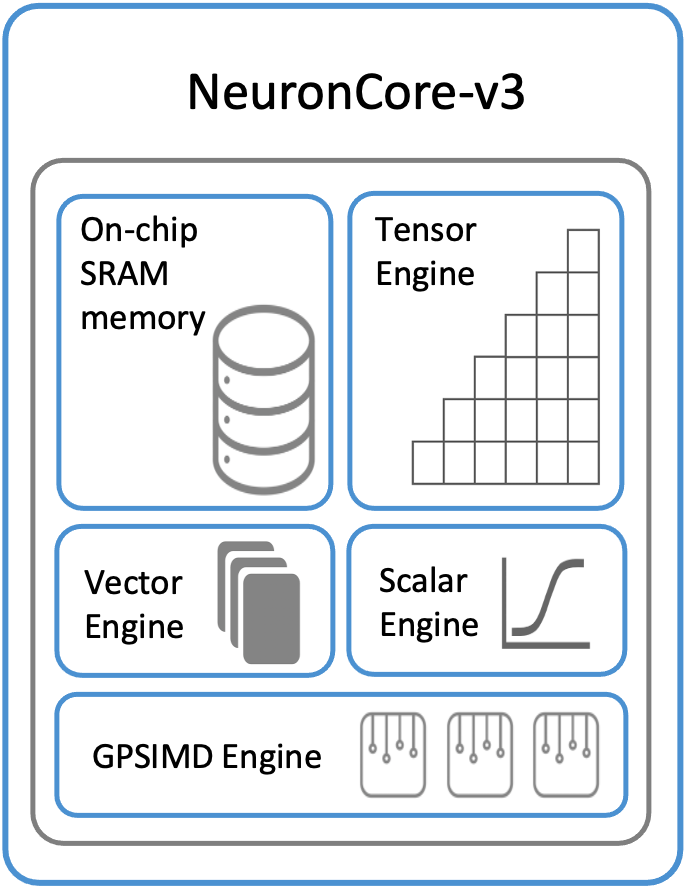
세대별 발전: Trainium 칩은 Trainium1의 NeuronCore-v2에서 Trainium2의 NeuronCore-v3 으로 진화하며 지속적으로 성능을 개선해왔다.
3.2 메모리 계층 구조
고대역폭 메모리 (HBM)
HBM은 연산 엔진에 데이터를 끊임없이 공급하는 데 결정적인 역할을 한다.- Trainium1: Trn1 인스턴스는 최대 512 GB의 HBM을 탑재하여 9.8 TB/s의 대역폭을 제공한다.
- Trainium2: 각 Trainium2 칩은 96 GB의 HBM3e 메모리를 탑재한다. 이를 통해 Trn2 인스턴스는 1.5 TB, UltraServer는 6 TB라는 막대한 메모리 용량을 갖추게 되며, 총 대역폭은 각각 46 TB/s와 185 TB/s에 달한다.
온칩 메모리 (On-Chip Memory)
시스톨릭 어레이와 직접 연결된 온칩 SRAM 또는 스크래치패드 메모리는 데이터 재사용성을 높이고 지연 시간을 줄여 성능을 극대화하는 핵심 설계 요소이다.
3.3 인터커넥트 패브릭: 대규모 확장의 열쇠
NeuronLink (스케일업 네트워킹): NeuronLink는 AWS가 독자적으로 개발한 초고속 칩-투-칩 인터커넥트 기술이다. 이 기술은 인스턴스 또는 UltraServer 내의 여러 칩들을 하나의 통합된 메모리 풀로 묶어주어 효율적인 모델 병렬 처리를 가능하게 하고 통신 병목 현상을 방지한다. 이 기술은 NeuronLink-v2에서 v3로 세대를 거듭하며 발전했다.
Elastic Fabric Adapter (EFA) (스케일아웃 네트워킹): EFA는 노드 간 통신을 위한 고성능, 저지연 네트워크 인터페이스이다. EFA는 수만 개의 가속기를 페타비트급 무손실 네트워크로 연결하는 EC2 UltraCluster를 구축하는 기반 기술이다. 네트워크 대역폭은 Trn1의 1.6 Tbps에서 Trn2의 3.2 Tbps로 확장되었다.
UltraServer 아키텍처: UltraServer는 이러한 개념을 통합한 아키텍처이다. 4개의 Trn2 인스턴스가 NeuronLink를 통해 긴밀하게 연결되어 64개의 칩으로 구성된 하나의 강력한 노드를 형성하고, 이 UltraServer는 다시 EFA를 통해 다른 UltraServer들과 클러스터를 이룬다.
이러한 이중 인터커넥트 전략은 계층적 시스템 설계의 정수를 보여준다. 이는 서로 다른 두 가지 문제를 동시에 해결한다. NeuronLink는 단일 컴퓨팅 노드 내부의 메모리 및 연산 밀도 문제를 해결하고, EFA는 데이터센터 전체에 걸친 분산 훈련 문제를 해결한다.
이러한 아키텍처는 과거에는 비현실적이었던 규모의 모델을 훈련시키기 위해 특별히 제작된 것이다. 조 단위 파라미터를 가진 모델을 훈련시키려면 모델의 일부를 저장할 막대한 로컬 컴퓨팅/메모리 자원과, 그래디언트 및 파라미터를 동기화하기 위한 노드 간 초고속 통신이 모두 필요하다.
단일 인터커넥트 기술은 이 두 가지 요구사항 사이에서 타협점을 찾아야 하지만, AWS는 NeuronLink와 EFA라는 두 개의 전문화된 패브릭을 만들어 이 문제를 해결했다. NeuronLink가 서버 내의 '고속도로' 역할을 하여 '슈퍼 가속기'(UltraServer)를 만들면, EFA는 이 슈퍼 가속기들을 연결하는 '도시 간 고속도로 시스템' 역할을 하는 것이다. 이 계층적 설계는 문제의 각 수준에서 최적의 성능을 발휘하게 하여, Project Rainier에서 볼 수 있는 엄청난 확장성을 가능하게 한다.
3.4 고급 하드웨어 최적화데이터 유형: Trainium은 높은 정밀도의 FP32부터 성능 중심의 TF32, BF16, FP16, 그리고 현대 LLM 훈련 효율성의 핵심인 새로운 구성 가능 FP8(cFP8) 데이터 유형까지 폭넓게 지원한다.
특수 기능: Trainium2에는 훈련 속도를 최대 30%까지 향상시킬 수 있는 확률적 반올림(stochastic rounding), 동적 텐서 형태 지원, C++로 작성된 맞춤형 연산자, 4배 희소성(sparsity) 지원, 전용 집합 통신(collective communication) 엔진 등 다양한 하드웨어 수준의 최적화 기능이 포함되어 있다.
4. 성능, 벤치마크 및 경쟁 포지셔닝
4.1 AWS 성능 주장 및 고객 검증주요 지표
AWS는 Trainium의 성능 우위를 강조하기 위해 다음과 같은 핵심 지표들을 제시한다:
동급 GPU 대비 최대 50%의 훈련 비용 절감, P5 인스턴스 대비 30-40% 더 나은 가격 대비 성능, 그리고 구형 V100 GPU 대비 2-5배 빠른 속도 (사실상 Nvidia A100 급 연산 능력으로 Nvidia 의 최신 GPU B200 보다는 매우 떨어지는 속도) 와 3-8배 저렴한 비용.
고객 평가 (정성적 및 정량적)- Anthropic: 주력 모델인 Claude 3.5 Haiku를 Bedrock 서비스에서 Trainium2로 실행했을 때 60% 더 빠른 속도를 달성했다. 이는 선도적인 AI 연구소로부터의 중요한 성능 검증이다.
- Databricks: 자사의 Mosaic AI 플랫폼에서 모델을 훈련하는 고객들에게 최대 30%의 총소유비용(TCO) 절감 효과를 제공할 것으로 기대하고 있다.
- poolside: 차세대 모델을 UltraServer로 훈련하여 EC2 P5 인스턴스 대비 40%의 비용 절감을 예상하고 있다.
- Itaú Unibanco: 추론 작업에서 GPU 대비 7배의 처리량 향상을 달성하여, Trainium 아키텍처가 훈련뿐만 아니라 추론에서도 다재다능함을 입증했다.
이러한 고객 평가는 무작위로 선정된 것이 아니라, AI 가치 사슬 전반에 걸쳐 Trainium의 효용성을 입증하기 위해 전략적으로 구성되었다.
Anthropic은 최첨단 파운데이션 모델 개발사를 대표하고, Databricks는 엔터프라이즈 AI 플랫폼 계층을, poolside는 특정 도메인(소프트웨어 개발)에 특화된 AI 스타트업을, 그리고 Itaú는 AI를 도입하는 전통적인 기업을 상징한다.
AWS는 최상위 고객인 Anthropic을 확보함으로써 하드웨어의 한계를 시험하는 최고 수준의 신뢰성을 얻었다. 이후 수천 개의 하위 고객을 보유한 Databricks를 공략함으로써 강력한 채널 파트너십을 구축했다.
마지막으로 전통적인 은행과 스타트업 사례를 통해 Trainium의 이점이 다양한 비즈니스 유형과 사용 사례에 적용될 수 있음을 보여주었다. 이 다각적인 검증 전략은 AWS가 단순한 벤치마크 수치에만 의존하는 것보다 훨씬 빠르게 시장의 신뢰를 확보하기 위해 설계된 것이다.
4.2 경쟁 환경 분석
NVIDIA H100과의 직접 비교: 단일 칩의 순수 성능 측면에서는 NVIDIA H100이 우위에 있다는 점은 인정된다. 그러나 경쟁의 핵심은 TCO와 가격 대비 성능이다. Trainium2는 A100 클러스터와 유사한 처리량을 약 50%의 비용으로 제공하며, H100에 비해서는 상당한 비용 우위를 가지면서 경쟁력 있는 성능을 제공하는 것으로 포지셔닝된다.
Google TPU v5e와의 비교: Trainium과 TPU는 모두 효율성을 위해 설계된 맞춤형 ASIC이다. 칩 시간당 온디맨드 가격 면에서는 TPU v5e가 약간의 우위를 가질 수 있으나, Trainium은 광범위한 AWS 클라우드 생태계에 직접 통합되어 있다는 점이 핵심적인 전략적 이점이다.
전력 효율성: Trainium의 뛰어난 전력 효율성(와트당 성능)은 데이터센터 규모에서 TCO에 결정적인 영향을 미치는 핵심 차별화 요소이다. AWS는 Trainium이 A100 대비 2배의 와트당 성능을 제공한다고 주장한다.
표 2: 경쟁 하드웨어 사양 분석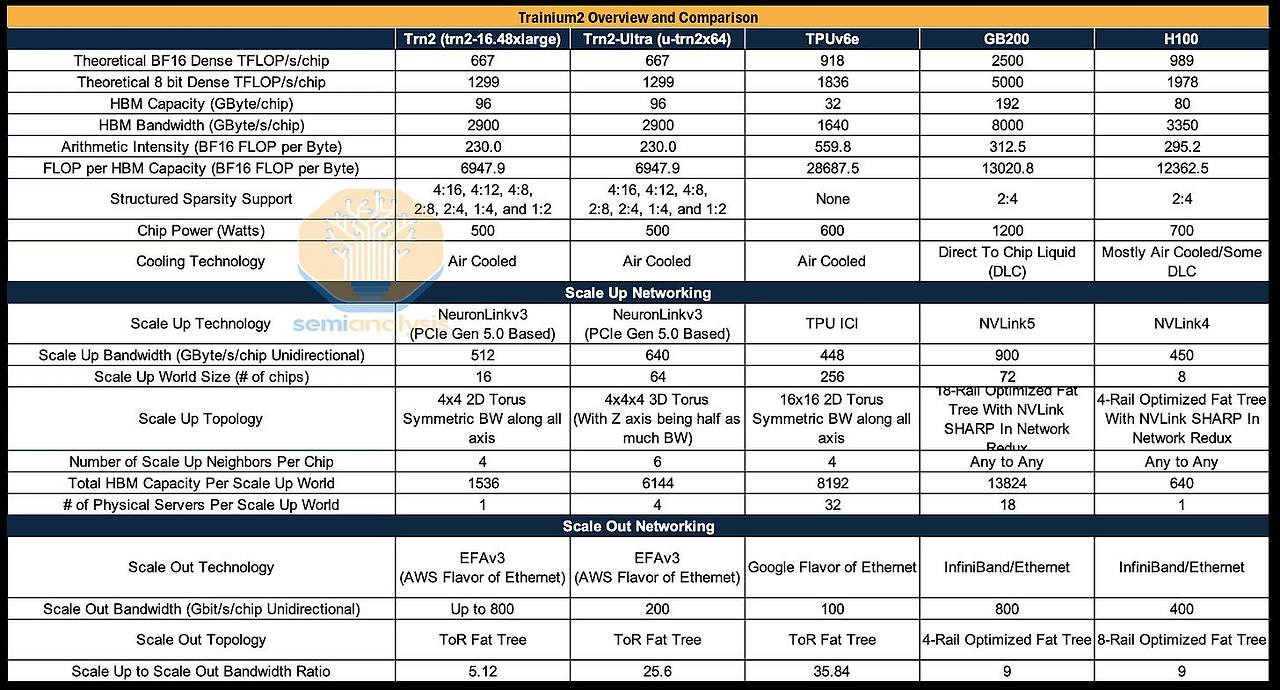
출처: SemiAnalysis 4.3 사용성 및 도입 장벽
Trainium이 강력한 가격 대비 성능을 제공하는 것은 사실이지만, 이는 AWS Neuron SDK에 대한 헌신과 잠재적인 모델 리팩토링을 요구하는 트레이드오프를 수반한다. 반면, NVIDIA의 CUDA 생태계는 가장 쉬운 도입 경로를 제공한다. 이는 Trainium 도입을 고려하는 개발자들에게 중요한 마찰 지점으로 작용할 수 있다.
5. 소프트웨어 생태계: AWS Neuron SDK
5.1 Neuron SDK의 핵심 구성 요소
Neuron 컴파일러: Neuron 컴파일러는 PyTorch와 같은 상위 레벨 프레임워크에서 작성된 모델을 NeuronCore 하드웨어에서 효율적으로 실행될 수 있는 최적화된 코드로 변환하는 역할을 한다. 이 과정에서 연산자 융합, 데이터 유형 변환, 그래프 분할과 같은 다양한 최적화를 수행한다.
Neuron 런타임: Neuron 런타임 라이브러리는 컴파일된 모델을 Trainium 칩에서 실행하는 것을 관리한다. 데이터 이동, 스케줄링, NeuronCore 간의 통신 등을 처리하여 원활한 실행 환경을 제공한다.
프레임워크 통합: Neuron SDK는 PyTorch, TensorFlow, JAX와 같은 인기 있는 머신러닝 프레임워크와 긴밀하게 통합되어 있다. 개발자 입장에서는 단 몇 줄의 코드 변경만으로 기존 모델을 Trainium 하드웨어에서 실행할 수 있어, 초기 도입 장벽을 크게 낮춘다.
개발자 도구: SDK는 하드웨어 활용도, 성능 병목 현상, 모델 실행 과정에 대한 깊이 있는 통찰력을 제공하는 프로파일링 및 디버깅 도구를 포함하고 있다. 이는 모델 최적화에 필수적인 기능이다.Anthropic Claude 의 경우 Neuron Compiler 가 아닌 Low-Level 의 XLA Compiler 를 직접 사용하는 것으로 보입니다.
https://spedtrder.tistory.com/64Claude - 최근 3가지 이슈에 대한 사후 분석 (25.9.19)
A postmortem of three recent issues(Claude - 최근 3가지 이슈에 대한 사후 분석) 이 보고서는 Claude의 응답을 간헐적으로 지연시켰던 세 가지 버그에 대한 기술 보고서입니다. 아래에서 발생한 문제, 해결에
spedtrder.tistory.com
Trainium의 나쁜 소식은 일반적으로 Pytorch<>XLA 코드패스가 Meta에 의해 내부적으로 광범위하게 사용되지 않으며 대부분 AWS 및 Google Phitorch 팀에 의해 유지된다는 것입니다. 이는 Pytorch<>XLA 코드패스에 대한 버그가 많은 주된 이유입니다. 또한 Google과 AWS Phitorch 팀은 Deepmind 및 Anthropic과 같은 실험실의 워크로드가 Jax 스택을 통해 실행되기 때문에 Jax 팀에 비해 두 번째 클래스입니다.
JAX는 전통적으로 Google의 내부 XLA ML 컴파일러를 사용할 때 Google의 TPU 칩에서만 작동했지만 TPU와 Trainium2는 모두 거대한 수축기 배열과 3D 토러스를 사용하는 정적으로 컴파일 된 그래프가있는 AI 칩이기 때문에 JAX의 프로그래밍 모델은 Trainium2에 잘 적합하다고 생각합니다. 즉, Trainium이 XLA Compiler 플러그인 및 PRJT 런타임에 연결하는 것이 직관적입니다. JAX의 논리적 인 입방체 메쉬와 축은 Trainium 토폴로지에 매우 잘 맞습니다. AWS는 최근 JAX <> Trainium 통합을 위한 공개 베타를 발표했는데, 이는 매우 흥미로운 방향입니다.
5.2 고급 프로그래밍 기능: NKI 및 맞춤형 연산자
Neuron Kernel Interface(NKI)는 Triton과 유사한 Python 기반 인터페이스로, 고급 개발자들이 맞춤형 커널을 작성하고 NeuronCore의 명령어 집합 아키텍처(ISA)에 직접 접근할 수 있게 해준다. 이는 기본적으로 지원되지 않는 새로운 모델 아키텍처를 연구하고 최적화하는 데 매우 중요하다.
NKI의 존재는 전략적으로 매우 중요한 결정이다. 대부분의 사용자는 상위 레벨 프레임워크 통합에 의존하겠지만, NKI는 하드웨어의 성능을 극한까지 끌어내야 하는 최상위 1%의 사용자(예: Anthropic의 연구원 또는 아마존 내부 팀)에게 '탈출구'를 제공한다.반대로 AI Research 담당 직원들에게는 상당히 고통스러운 작업이 추가되는 경우이다. Nvidia CUDA 의 경우 소프트웨어 프레임워크 Ecosystem 과 Nvidia 의 전폭적인 지원으로 high-level 의 코딩 만으로 원하는 모델 연구, 실험, 운영을 할 수 있다. 물론 Nvidia GPU 는 가격이 비싸다. 하지만 이러한 불편함을 해소하여 좀더 빠르게 모델을 Time-To-Market 할 수 있다면 이것만으로 서비스 제공하는 입장에서는 이득이라고 볼 수 있다.
이는 플랫폼이 블랙박스가 되는 것을 방지하고 AI 연구의 최전선을 지원할 수 있도록 보장한다. 맞춤형 하드웨어의 가장 큰 위험 중 하나는 예측하지 못한 새로운 모델 아키텍처에 적응하지 못하는 것이다.
만약 새로운 유형의 신경망 계층이 인기를 얻었을 때 Neuron 컴파일러가 이를 제대로 지원하지 못한다면, 전체 하드웨어 플랫폼이 쓸모없게 될 수 있다. NKI는 이러한 위험을 완화한다. 고급 사용자들이 컴파일러를 우회하고 하드웨어를 직접 프로그래밍할 수 있게 함으로써, 원칙적으로 어떤 새로운 연산이든 효율적으로 구현할 수 있도록 보장한다. 이 기능은 끊임없이 새로운 기술을 발명하는 Anthropic과 같은 최상위 AI 연구소를 유치하고 유지하는 데 필수적이다. 따라서 NKI는 대중 시장을 위한 기능이라기보다는, 플랫폼의 미래를 보장하고 AI 커뮤니티에서 가장 영향력 있는 플레이어들과의 신뢰를 구축하기 위한 전략적 장치이다.
5.3 CUDA의 해자(Moat): Neuron의 힘겨운 싸움
기존 강자의 이점: NVIDIA의 CUDA는 사실상의 산업 표준으로, 20년에 걸쳐 성숙한 라이브러리, 개발자 도구, 그리고 방대한 전문가 커뮤니티를 구축했다. 이는 경쟁자들이 넘기 어려운 강력한 '해자(moat)' 즉, 경쟁 장벽으로 작용한다.
개발자 경험 격차: AWS가 도입을 단순화하기 위해 노력하고 있음에도 불구하고, 개발자들은 Neuron SDK를 사용하면서 학습 곡선이나 "하드웨어 특유의 문제"에 직면할 수 있다. 이는 익숙한 CUDA 환경에 비해 마찰을 유발하는 지점이다.
AWS의 대응 전략: AWS는 가장 인기 있는 프레임워크(PyTorch, JAX)와의 네이티브 통합을 보장하고, Hugging Face와 같은 허브와 협력하며 , 광범위한 문서와 컨테이너화된 환경(DLC)을 제공하여 배포를 단순화하는 방식으로 이 문제에 대응하고 있다.
6. 공급망 해부: 설계부터 제조까지
6.1 Annapurna Labs: 내부 설계의 핵심 동력Annapurna Labs는 2015년 아마존이 인수한 이스라엘의 마이크로일렉트로닉스 회사로, Graviton, Inferentia, 그리고 Trainium을 포함한 AWS의 모든 맞춤형 실리콘을 설계하는 핵심 기지이다. 이들의 설계 철학은 칩을 단독으로 설계하는 것이 아니라, 전체 서버와 소프트웨어 스택을 먼저 설계하고 그에 최적화된 칩을 역으로 정의하는 '시스템 우선' 접근 방식을 취한다.
6.2 파운드리 및 제조 파트너
Trainium1 & Trainium2
TSMC의 보도자료에 따르면, "Amazon Annapurna Labs 팀은 AWS Trainium 제품을 개발하면서 TSMC의 CoWoS®와 같은 첨단 패키징 기술을 사용하여 TSMC와 긴밀히 협력하고 있다"고 명시되어 있다. 이를 통해 TSMC가 핵심 파운드리 파트너임을 확실히 알 수 있다. 구체적인 공정 노드(5nm)는 명시되지 않았지만, 성능 목표를 고려할 때 최첨단 공정이 사용되었을 가능성이 높다.
Trainium3
Trainium3의 공급망은 ASIC 설계 전문 기업인 Alchip과 커넥티비티 IP 제공업체인 Marvell과의 공동 개발로 명확히 밝혀졌다. 이는 더 복잡한 미래 칩을 위해 보다 분산되고 협력적인 설계 모델로 전환하고 있음을 시사한다. (TSMC 3nm 공정 사용, 26년 1분기 양산 예정, 100만개 이상 주문 예상)미즈호 증권 보고서(25년 10월) 에 의하면 Broadcom 의 4번째 고객이 Anthropic 이라는 추정치가 나오고 있어서 향후 차세대 Trainium4 의 수요에 대해서는 좀 더 지켜봐야 할 것 같습니다.
6.3 다각화되는 미래: Intel과의 파트너십
최근 AWS가 "Intel 18A 공정 기반의 차세대 AI 패브릭 칩을 공동 개발"하기로 한 것은 매우 중요한 진전이다. 이 파트너십은 Trainium의 핵심 연산 다이가 아닌, NeuronLink의 진화된 형태인 칩렛 기반 인터커넥트 패브릭에 관한 것일 가능성이 높다. 이 움직임은 AWS의 파운드리 의존도를 TSMC에만 국한하지 않고 다각화하며, 미국 CHIPS 법과 같은 정책에 힘입어 진행되는 반도체 제조의 자국 회귀(reshoring) 흐름을 활용하는 전략적 의미를 가진다.
공급망의 진화는 AWS의 정교하고 성숙해가는 글로벌 전략을 보여준다. 초기 세대에서는 TSMC와의 파트너십을 통해 단순성과 세계 최고 수준의 기술 접근성을 확보했다. Trainium3에서는 복잡성 관리를 위해 전문 파트너인 Alchip과 Marvell을 참여시켰다. 그리고 Intel과의 파트너십은 가장 흥미로운 전략적 행보다. 이는 대만과 관련된 지정학적 리스크를 줄이는 동시에, TSMC에 대한 경쟁 압력을 가해 협상력을 높이고, Intel의 최첨단 18A 공정을 조기에 활용하여 기술적 우위를 점하려는 다목적 포석이다. 이는 단순한 엔지니어링을 넘어선 고도의 산업 및 지정학적 전략이다.
표 3: AWS Trainium 세대별 ASIC 공급망 파트너세대 주 설계사 핵심 설계 파트너 파운드리 / 제조 공정 Trainium1 Annapurna Labs N/A TSMC (추정, CoWoS 패키징 기술 사용) Trainium2 Annapurna Labs N/A TSMC (5nm, CoWoS 패키징 기술 사용) Trainium3 Annapurna Labs Alchip, Marvell TSMC (3nm) 미래 AI 패브릭 Annapurna Labs Broadcom, Intel Intel (18A 공정) 7. 전략적 전망 및 미래 과제
7.1 궁극의 해자로서의 수직적 통합Trainium은 실리콘부터 서비스에 이르기까지 AI 스택 전체를 통제하려는 AWS 전략의 핵심이다. 이러한 수직적 통합은 기성 부품을 사용할 때는 불가능한 공동 최적화를 가능하게 하여, 더 나은 성능과 낮은 비용을 실현하는 근간이 된다.
7.2 AWS AI 플라이휠의 동력: Amazon Bedrock의 역할
Trainium은 Amazon Bedrock과 같은 관리형 AI 서비스의 경제적 실행 가능성과 높은 수익성을 보장하는 저비용, 고성능 엔진이다. "Amazon Bedrock에서 사용되는 토큰의 대부분이 이미 Trainium에서 실행되고 있다"는 사실은 이 전략이 이미 성과를 거두고 있음을 보여준다. CEO 앤디 재시는 Bedrock이 "EC2만큼 큰 비즈니스"이자 "세계에서 가장 큰 추론 엔진"이 될 것이라는 비전을 제시했는데, 이는 전적으로 Trainium 및 Inferentia와 같은 맞춤형 실리콘에 의존하는 비전이다.
7.3 하이퍼스케일 야망: Project Rainier와 AI 슈퍼컴퓨팅의 미래
Anthropic을 위해 구축된 대규모 AI 컴퓨팅 클러스터인 Project Rainier는 이미 약 50만 개의 Trainium2 칩으로 운영되고 있으며, 100만 개 이상으로 확장될 예정이다. 이는 단순한 대규모 고객 배포를 넘어, AWS가 세계에서 가장 강력한 슈퍼컴퓨터 중 하나를 구축하고 있음을 의미하며, 소수의 기업만이 도달할 수 있는 규모로 운영할 수 있는 역량을 과시하는 것이다.
AWS의 전략은 훈련 하드웨어 계층을 상품화하여 서비스 계층(Bedrock)에서 가치를 포착하는 것이다. Trainium을 통해 저렴한 비용으로 훈련 환경을 제공함으로써 모델 개발자들을 AWS 플랫폼으로 유인한다. 일단 모델이 AWS에서 훈련되면, 그 모델은 AWS의 추론 인프라(Inferentia 및 Bedrock)에 배포될 가능성이 매우 높아진다. 훈련은 크지만 한정된 자본 지출인 반면, 추론은 애플리케이션 사용량에 따라 확장되는 지속적인 운영 비용이다. 따라서 추론 워크로드의 평생 가치가 훨씬 높다. AWS는 Trainium을 '고객 확보' 도구로 사용하여 훨씬 더 큰 추론 시장으로 고객을 유도하는 것이다. 이는 AI 스택에 적용된 전형적인 '플라이휠(flywheel)' 전략이다.
7.4 도전 과제와 앞으로의 길
소프트웨어 전쟁: 가장 큰 도전은 여전히 CUDA의 지배력에 맞서는 소프트웨어 생태계와 개발자 채택 문제이다. 성공은 Neuron SDK를 일반 개발자들이 원활하고 강력하며 쉽게 채택할 수 있도록 만드는 데 달려 있다.
실행 리스크: Trainium 개발 및 확장은 막대한 복잡성과 자본 투자를 요구한다. Trainium3/4 로드맵의 지연이나 기대에 미치지 못하는 성능은 NVIDIA와 다른 경쟁자들에게 다시 주도권을 내주는 결과를 초래할 수 있다.
시장 역학: AI 하드웨어 시장은 매우 치열하다. AWS는 NVIDIA뿐만 아니라 Google의 TPU, Microsoft의 Maia, 그리고 수많은 스타트업들과의 경쟁에서 앞서 나가기 위해 끊임없이 혁신해야 한다.
결론
AWS Trainium은 클라우드 컴퓨팅의 거인이 AI 시대의 기반이 되는 하드웨어 계층을 장악하기 위해 얼마나 깊이 있고 장기적인 투자를 하고 있는지를 보여주는 명백한 증거이다. 1세대 칩이 비용 효율성을 입증하는 데 중점을 두었다면, 2세대와 3세대로 이어지는 로드맵은 생성형 AI가 요구하는 극한의 성능과 규모를 충족시키기 위한 기술적 도약을 보여준다. 정교한 NeuronCore 아키텍처, 방대한 메모리 시스템, 그리고 NeuronLink와 EFA로 구성된 이중 인터커넥트 패브릭은 Trainium이 단순한 GPU의 대안이 아니라, 하이퍼스케일 AI 훈련을 위해 처음부터 다시 설계된 시스템임을 증명한다.
공급망 분석을 통해 드러난 Annapurna Labs, TSMC, Alchip, Marvell, 그리고 Intel과의 다각적인 협력 관계는 AWS가 기술적 리더십을 유지하고 지정학적 리스크를 관리하기 위해 얼마나 정교한 글로벌 전략을 구사하고 있는지를 보여준다.
그러나 Trainium의 궁극적인 성공은 하드웨어의 성능만으로 결정되지 않는다. 가장 큰 도전은 NVIDIA CUDA가 수십 년간 구축해 온 견고한 소프트웨어 생태계와 개발자 커뮤니티의 벽을 넘는 것이다. AWS Neuron SDK의 사용 편의성과 기능 확장이 Trainium의 시장 채택 속도를 결정할 핵심 변수가 될 것이다.
전략적으로 Trainium은 AWS AI 플라이휠의 핵심 동력이다. 저렴한 훈련 비용으로 개발자들을 유치하고, 이를 통해 장기적으로 더 큰 수익을 창출하는 추론 워크로드를 AWS 생태계에 고정시키는 역할을 한다. Project Rainier와 같은 프로젝트는 AWS가 AI 인프라를 단순한 서비스가 아닌, 국가적 규모의 전략 자산으로 간주하고 있음을 시사한다. 결국 AWS Trainium은 AI의 미래가 클라우드에서 펼쳐질 것이며, 그 클라우드의 가장 깊은 곳, 실리콘 레벨부터 AWS가 통제하겠다는 강력한 의지의 표명이다.
Works cited
- AI Accelerator - AWS Trainium Customers - AWS - Amazon AWS, https://aws.amazon.com/ai/machine-learning/trainium/customers/
- AI Accelerator - AWS Trainium, https://aws.amazon.com/ai/machine-learning/trainium/
- Amazon's Trainium 2: A Deep Dive into AWS's Next-Generation AI Chip - Vamsi Talks Tech, https://www.vamsitalkstech.com/ai/amazons-trainium-2-a-deep-dive-into-awss-next-generation-ai-chip/
- AI Chips Explained: Inside the workings of AWS Trainium chip - About Amazon, https://www.aboutamazon.com/stories/ai-chips-aws-trainium2-explain
- [News] AWS's Trainium3 Reportedly Draws Interest from Large, Mid ..., https://www.trendforce.com/news/2025/10/31/news-awss-trainium3-reportedly-draws-strong-interest-from-large-mid-sized-clients-ramping-early-26/
- The Irony Of AWS Being Intel's Latest Savior - The Next Platform, https://www.nextplatform.com/2024/09/17/the-irony-of-aws-being-intels-latest-savior/
- TSMC Launches OIP 3DFabric Alliance to Shape the Future of ..., https://pr.tsmc.com/english/news/2968
- Cloud AI Platforms Comparison: AWS Trainium vs Google TPU v5e vs Azure ND H100, https://www.cloudexpat.com/blog/comparison-aws-trainium-google-tpu-v5e-azure-nd-h100-nvidia/
- AWS Unveils Next-Gen AI Chips with Trainium 3 and Ultra Servers at re:Invent 2024, But Unlikely to Challenge Nvidia's Dominance, https://www.ctol.digital/news/aws-trainium-3-chips-vs-nvidia-ai-hardware-reinvent-2024/
- AWS re:Invent 2025 to feature Trainium3, scaling secure AI agents - Constellation Research, https://www.constellationr.com/blog-news/insights/aws-reinvent-2025-feature-trainium3-scaling-secure-ai-agents
- AWS Silicon Innovation – Amazon Web Services, https://aws.amazon.com/silicon-innovation/
- AWS Chips Away at Nvidia's Lead with Rising Demand for Custom AI Processors, https://anysilicon.com/aws-chips-away-at-nvidias-lead-with-rising-demand-for-custom-ai-processors/
- Scaling distributed training with AWS Trainium and Amazon EKS | Artificial Intelligence, https://aws.amazon.com/blogs/machine-learning/scaling-distributed-training-with-aws-trainium-and-amazon-eks/
- AWS Trainium vs. NVIDIA GPU-Optimized AMI Comparison - SourceForge, https://sourceforge.net/software/compare/AWS-Trainium-vs-NVIDIA-GPU-Optimized-AMI/
- Compare AWS Trainium vs. NVIDIA GPU-Optimized AMI in 2025 - Slashdot, https://slashdot.org/software/comparison/AWS-Trainium-vs-NVIDIA-GPU-Optimized-AMI/
- AWS Marketplace: AWS Trainium POC - Amazon.com, https://aws.amazon.com/marketplace/pp/prodview-vfz6umskmdkwq
- Navigating GPU Challenges: Cost Optimizing AI Workloads on AWS, https://aws.amazon.com/blogs/aws-cloud-financial-management/navigating-gpu-challenges-cost-optimizing-ai-workloads-on-aws/
- Follow us into the lab where AWS designs custom chips - About Amazon, https://www.aboutamazon.com/news/aws/take-a-look-inside-the-lab-where-aws-makes-custom-chips
- AWS' custom chip strategy is showing results, and cutting into Nvidia's AI dominance : r/hardware - Reddit, https://www.reddit.com/r/hardware/comments/1ler0gx/aws_custom_chip_strategy_is_showing_results_and/
- Distributed Training of Large Language Models on AWS Trainium - Amazon Science, https://assets.amazon.science/fa/fc/6c9a63824f1fa3655fc757825256/distributed-training-of-large-language-models-on-aws-trainium.pdf
- AWS's most powerful AI chip, in-depth analysis!-Electronics Headlines-EEWORLD, https://en.eeworld.com.cn/mp/Icbank/a390003.jspx
- On the Programmability of AWS Trainium and Inferentia | by Chaim Rand - Medium, https://chaimrand.medium.com/on-the-programmability-of-aws-trainium-and-inferentia-cd455826e26c
- Trainium Architecture — AWS Neuron Documentation, https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/arch/neuron-hardware/trainium.html
- AWS NeuronCore Architecture — AWS Neuron Documentation, https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/arch/neuron-hardware/neuroncores-arch.html
- Amazon EC2 Trn1 Instances for High-Performance Model Training are Now Available - AWS, https://aws.amazon.com/blogs/aws/amazon-ec2-trn1-instances-for-high-performance-model-training-are-now-available/
- Video: Transformer training shootout, part 2: AWS Trainium vs. NVIDIA V100 - Julien Simon, https://julsimon.medium.com/video-transformer-training-shootout-part-2-aws-trainium-vs-nvidia-v100-525fca92ef22
- Is there an AI strategy for AWS? Customers are confused and frustrated. - Reddit, https://www.reddit.com/r/aws/comments/1o42gev/is_there_an_ai_strategy_for_aws_customers_are/
- AWS Neuron SDK Documentation — AWS Neuron Documentation, https://awsdocs-neuron.readthedocs-hosted.com/
- How the GenAI Revolution Reminds Us of 1990s Computing - The New Stack, https://thenewstack.io/how-the-genai-revolution-reminds-us-of-1990s-computing/
- Nvidia Competitors: AI Chipmakers Fighting the Silicon War | Beebom, https://beebom.com/nvidia-competitors-ai-chipmakers/
- AWS Trainium | Artificial Intelligence, https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/aws-trainium/
- Using TensorFlow-Neuron and the AWS Neuron Compiler - AWS Deep Learning AMIs, https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-tf-neuron.html
- Quickstart: Configure and deploy a vLLM server using Neuron Deep Learning Container (DLC), https://awsdocs-neuron.readthedocs-hosted.com/en/latest/containers/get-started/quickstart-configure-deploy-dlc.html
- AWS Semiconductor | AWS for Industries, https://aws.amazon.com/blogs/industries/tag/aws-semiconductor/
- Accelerate chip-design verification process by running Siemens EDA Calibre on AWS, https://aws.amazon.com/blogs/industries/accelerate-chip-design-verification-process-by-running-siemens-eda-calibre-on-aws/
- Annapurna Labs - Wikipedia, https://en.wikipedia.org/wiki/Annapurna_Labs
- How silicon innovation became the 'secret sauce' behind AWS's success - Amazon Science, https://www.amazon.science/how-silicon-innovation-became-the-secret-sauce-behind-awss-success
- AI-Chip | A list of ICs and IPs for AI, Machine Learning and Deep Learning. - GitHub Pages, https://basicmi.github.io/AI-Chip/
- The Silicon Supercharge: How Specialized AI Hardware is Redefining the Future of Intelligence in Late 2025 | FinancialContent, https://markets.financialcontent.com/stocks/article/tokenring-2025-10-29-the-silicon-supercharge-how-specialized-ai-hardware-is-redefining-the-future-of-intelligence-in-late-2025
반응형'TechStock&Review > AI&Cloud&SW' 카테고리의 다른 글
TPU 위협론: 시장의 소음(FUD)과 본질(Signal)의 분리 (25.12.8) (0) 2025.12.08 Microsoft의 AI 전략 분석 - 에너지에서 토큰까지 (25.11.17) (1) 2025.11.17 어시스턴트 에서 에이전트로: Microsoft Copilot의 전진과 옆길 (25.10.13) (0) 2025.10.13 Microsoft 데이터 센터의 AI 칩 레밸 냉각기술 (25.9.25) (1) 2025.09.25 iPhone 17 A19 칩 AI 추론 성능 벤치마크 (25.9.24) (2) 2025.09.24